有人用 LLM 来审查有关 LLM 的论文?
这个星期,每个 AI 研究组都在焦急地等待全球顶会 CVPR 2025 放榜。
AI 领域的热度一年比一年高,今年的审稿工作也是时间紧,任务重。直到北京时间周四凌晨,论文接收的结果才被逐步上传到 OpenReview 上。大会官方表示,预计项目主席很快会向所有作者发出电子邮件,介绍更多详细信息,包含最终评审的分数。
许多研究者也已经在社交网络上分享了论文被接收的喜悦:
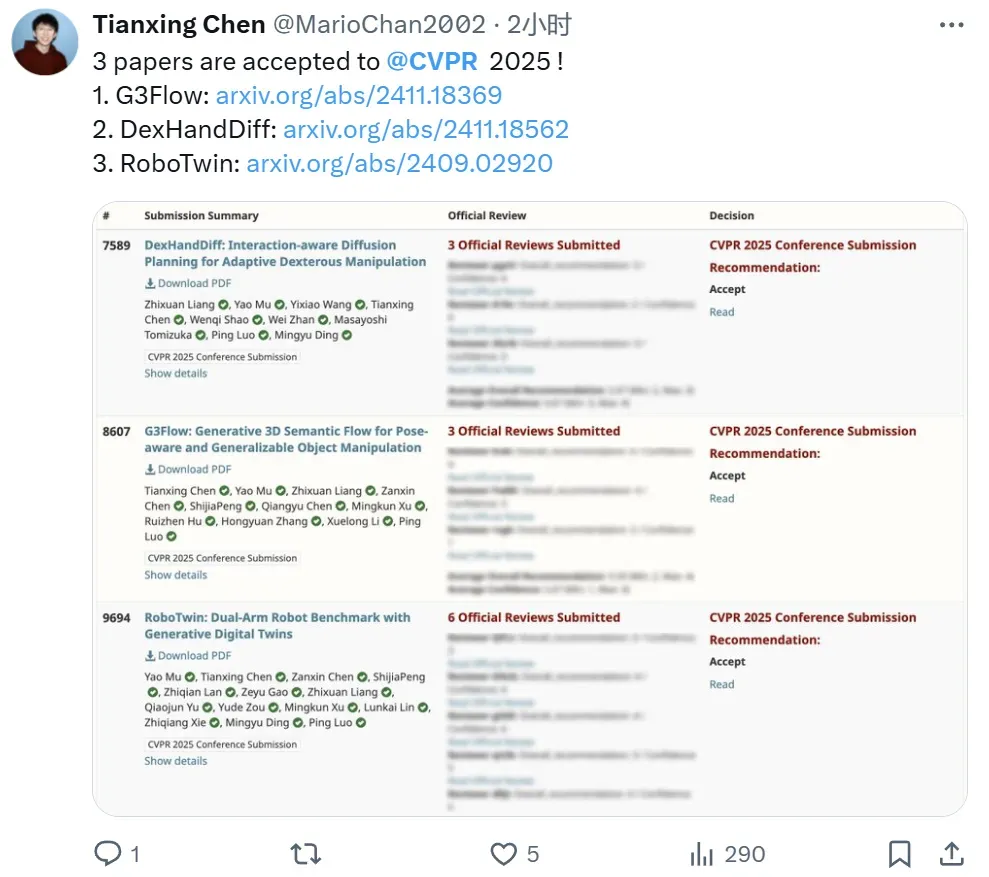
即将前往香港大学读博的深圳大学四年级本科生 Tianxing Chen(陈天行)宣布自己有三篇论文被 CVPR 2025 接收
CVPR 2025 共收到 13008 篇经过审核的有效投稿,项目委员会最终推荐的接收论文数为 2878 篇,接收率为 22.1%。
相比去年 11532 篇提交、2719 篇接收的数字(接收率 23.6%),今年的大会录取率创下了历史新低。可见今年的计算机视觉行业更加火热,竞争也更加激烈了。
横向比对的话,同属 AI 全球顶会的 ICLR 2025(接收率 32.08%)、NeurIPS 2024 (接收率 25.8%)等都选择了扩大录取范围。CVPR 的「严格把关」引发了人们的讨论。对此,官方表示大会主办方不会刻意引导论文的录取比例,论文是否被接收是 AC(Area Chair、领域主席)对论文原始、独立的决定。
然而事情没有这么简单。
就在论文接收结果放出的同时,CVPR 也对部分审稿人进行了一番声讨:

CVPR 2025 官方推特表示,领域主席(Area Chair/AC)发现了一些极不负责任的审稿人 —— 他们要么完全放弃了审稿流程,要么就提交了质量极低的审稿结果,其中一些结果还是由大型语言模型(LLM)生成的。
同时,CVPR 官方还公布了对此事件的处理结果:经过彻底的调查,项目主席 (PC)决定拒收 19 篇论文;根据之前传达的 CVPR 2025 政策,这些论文原本可被接收,但它们的作者都已被认定为极不负责任的审稿人。
不过,CVPR 官方并没有公布这些「不负责任的审稿人」的名单。有人认为如果公布人名的话,此举会有更大的威慑力。
还有人补充说,不负责任的审稿人不仅是那些使用大语言模型写评审的人,还包括那些对审稿过程敷衍了事,以及没有明确理由就拒绝竞争者论文的人。
Meta 研究科学家 Felix Juefei Xu 更是将自己对此事的想法整理成了一条长推文。他尤其关注被惩罚的审稿人的合作者 —— 他们原本并无过错,却因为审稿人的失职而一并受到拒收惩罚。他认为这是一种大锤猛砸式的方法,而手术刀式的处理可能会更仁慈一些。
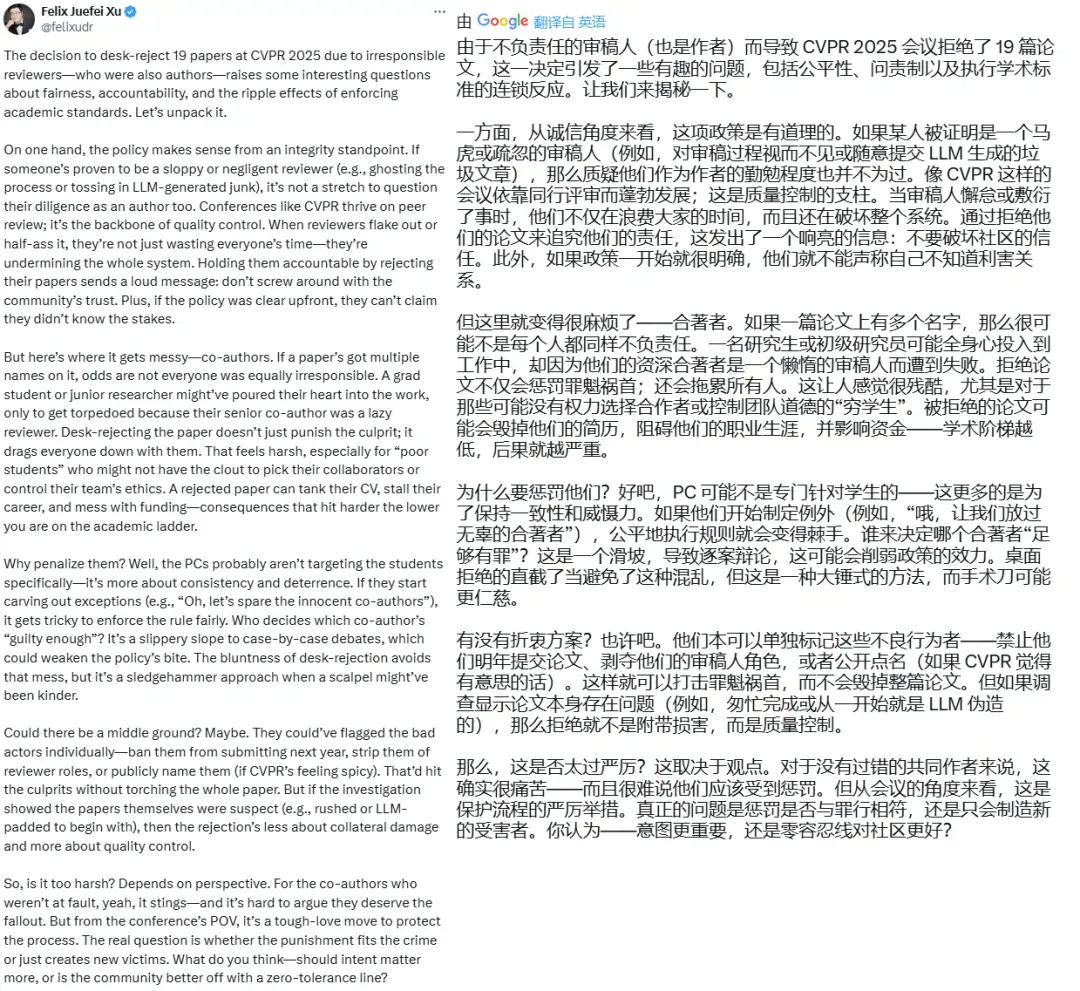
不知道我们的读者朋友对此有什么看法?是否觉得这种惩罚对其他合作者来说并不公平?
此外,在 AI 学术界热议 CVPR 2025 论文接收情况时,Snap 研究科学家 Ivan Skorokhodov 发现 CVPR 会议的谷歌学术排名(h5 指数)已经上升到了第二名,仅次于《Nature》,超过了历史悠久的《新英格兰医学杂志》和《Sicence》。

把所有学科都算上,全球第二。
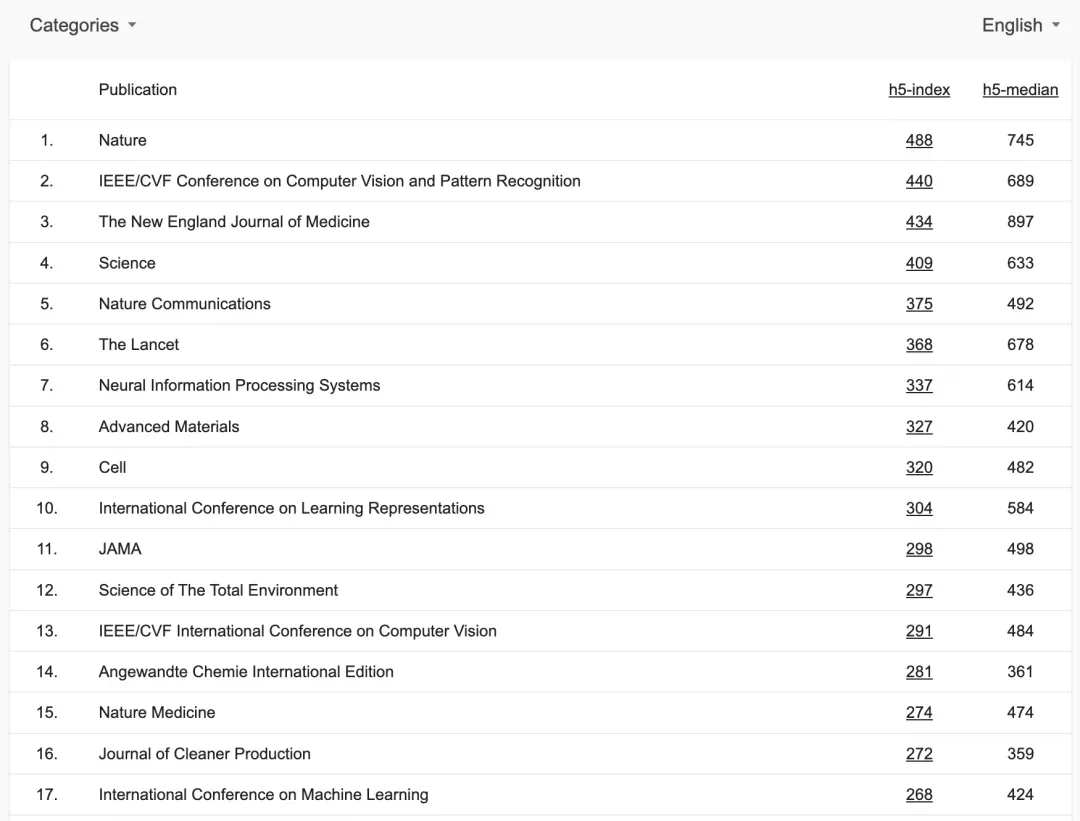
而且不只是 CVPR,NeurIPS、ICLR、ICCV 和 ICML 也都进入了前 20 名,分别位列第 7/10/13/17 位!
再考虑到这个排名是基于 h5 指数的(h5 指数是过去 5 年内发表的文章的 h 指数),也就是说并没有计算发布在 arXiv 上的论文的引用情况,因此如果再把这些引用加进来,Nature 很可能就会失去谷歌学术排名第一的宝座。
AI 研究真算得上是热潮汹涌!
你是否投稿了 CVPR 2025 会议,接收情况如何呢?


