
译者 | 布加迪
审校 | 重楼
想象一下,你戴着耳机驾驶一辆汽车,每五分钟才更新一次路况信息,而不是持续不断地提供当前位置情况的视频流。过不了多久,你就会撞车。
虽然这种类型的批处理在现实世界中并不适用,却是当今许多系统运行的方式。批处理诞生于过时的技术限制,迫使应用程序依赖静态的延迟数据。当计算、内存和存储均有限时,这种方法可能是唯一可行的解决方案,但它与我们跟现实世界互动的方式完全不符合,更不符合AI的运作方式。
生成式AI具有不可思议的潜力,不能将大语言模型(LLM)视为静态数据库,即等待输入并提供输出的反应式系统。AI依赖实时情境数据才能蓬勃发展。如果固守批处理观念,我们无异在扼杀其能力。
不妨探讨一下为什么批处理范式已过时,它如何阻碍了AI应用的发展,以及为什么AI的未来需要一种实时事件流平台。
为什么我们受困于批处理模式?
用于分析和机器学习的面向批处理的系统几十年来一直主导着技术界。这些系统应运而生,是在计算机内存有限、算力有限、存储空间极小的时代创建的。然而,同样的传统方法现正被应用于新时代的生成式AI。
机器学习运维(MLOps)在很大程度上围绕一组离散的、顺序的任务发展而来,比如特征工程、模型训练、模型测试、模型部署和偏差表征。这种概念模型非常适合面向批处理的开发和交付,但它限制了这些应用程序在不断变化的世界中的反应性和准确性。那些需要更好响应的应用程序势必需要避开通用的MLOps基础设施。
我们认为,这是一种有缺陷的方法。
没有人因设计批处理过程而被解雇
究其核心,这种范式将数据聚合到一个中央数据库中,数据被动地等待系统或用户轮询和调用。由此形成的系统其用途完全取决于接收到的查询的具体需求。虽然这种方法适用于当时的限制,但从根本上脱离了我们体验世界并与之互动的方式。
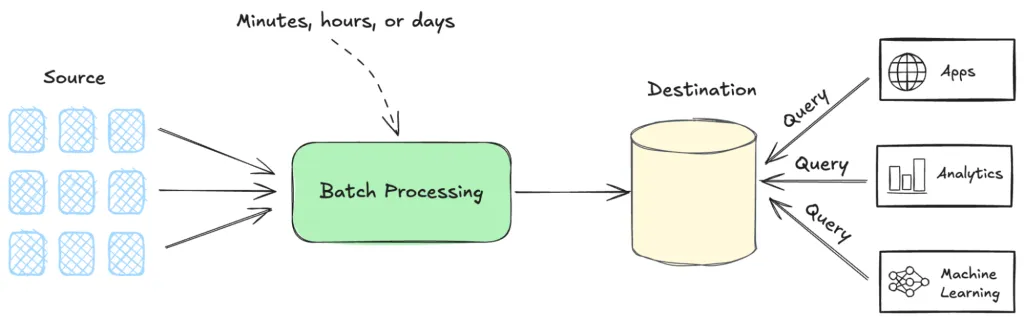
图1. 批流程的总体示意图
尽管技术不断发展,这种观念依然根深蒂固。今天,我们有了数据流平台之类的替代技术,可以实现实时的事件驱动架构。但是批处理系统仍然存在,倒不是由于它们是最好的解决方案,而是由于它们已成为认可的行事方式。
就像“没有人因购买IBM系统而被解雇”这句老话,批处理系统同样如此:没有人因设计了一个将数据聚集在一个地方的系统而被解雇,前提是根据这个集中式数据采取行动高效而可靠。我们习惯于把工作看成是一系列任务,完成一项后再进行下一项。运筹学和精益制造等学科的成熟结果表明,我们在做批量工作时表现出色,因为我们通过实践变得更好,而转换思维比较低效。现代分布式系统不需要受制于我们的局限性。
机器学习中的批处理思维
在日常生活中,我们并不基于“批量更新”来应对世界。我们不断地处理信息,对不断变化的情境做出反应和适应。然而,历史限制导致了批处理成为默认范式。
传统的机器学习反映了这种面向批处理的思维。模型围绕严格的线性工作流程进行操作:
- 收集训练数据:收集特定领域的静态数据集,常用于时间快照。
- 特征工程:对数据进行预处理、完善并为模型做好准备。
- 训练模型:模型基于筛选后的数据而构建。
- 测试模型:将现有数据的一些部分与训练数据隔离出来,用于对照某些预定义的性能阈值测试模型的有效性。
- 部署模型:一旦部署,模型就变成了固定的工件,用于预测查询。
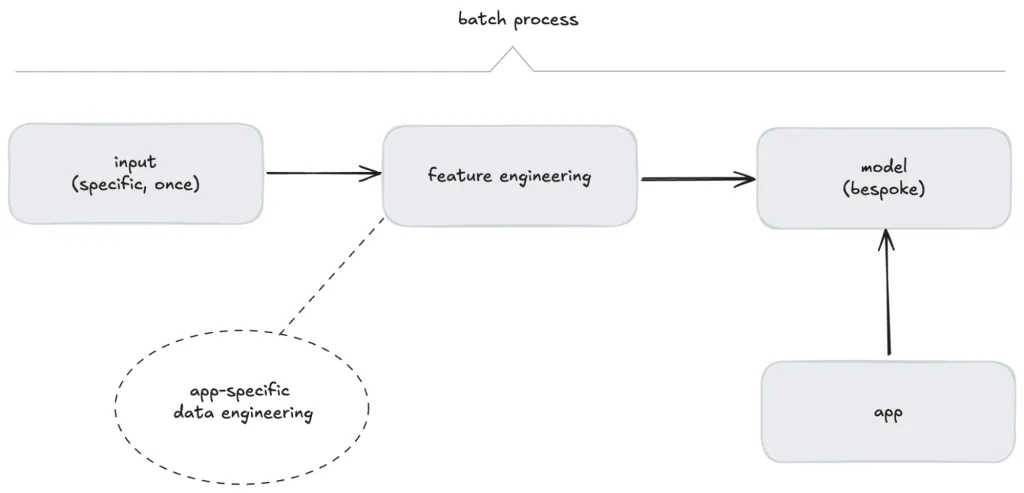
图2. 传统机器学习的批流程
虽然这个过程针对特定的用例很有效,但是本质上僵化,缺乏适应性。
相比之下,生成式AI如此具有变革性的原因之一是因为基础模型天生可重用,并且能够解决许多领域的各种问题。然而,为了使这些模型在不同领域之间可重用,必须在提示组装期间确保数据在特定情景中,而批处理无法满足这一要求。
若没有情景化的数据,LLM无法提供价值
不妨考虑一个简单的例子。想象一下,我们开发一款基于AI的航班助理,当航班延误时可以帮助客户。
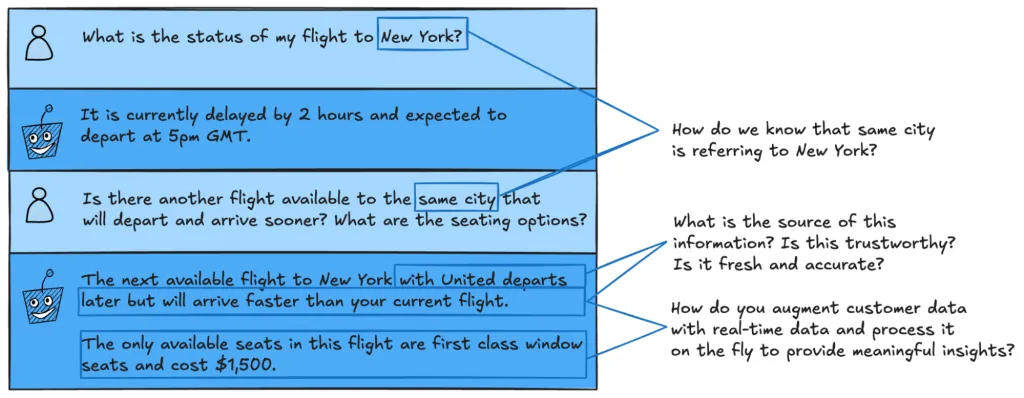
图3. 用户与AI航班助理之间的示例交互
在上面的两轮交互中,需要很多情景信息来满足客户的要求。
LLM需要记住,相关的城市是纽约。它需要知道客户身份和当前预订情况、当前航班信息、出发/到达时间、座位布局、座位偏好、定价信息和航空公司变更政策。
相比传统的机器学习:模型使用针对特定应用程序的数据进行训练,LLM并不使用你的数据进行训练,它们使用一般信息进行训练。针对特定应用程序的数据工程发生在提示组装期间,而不是模型创建期间。
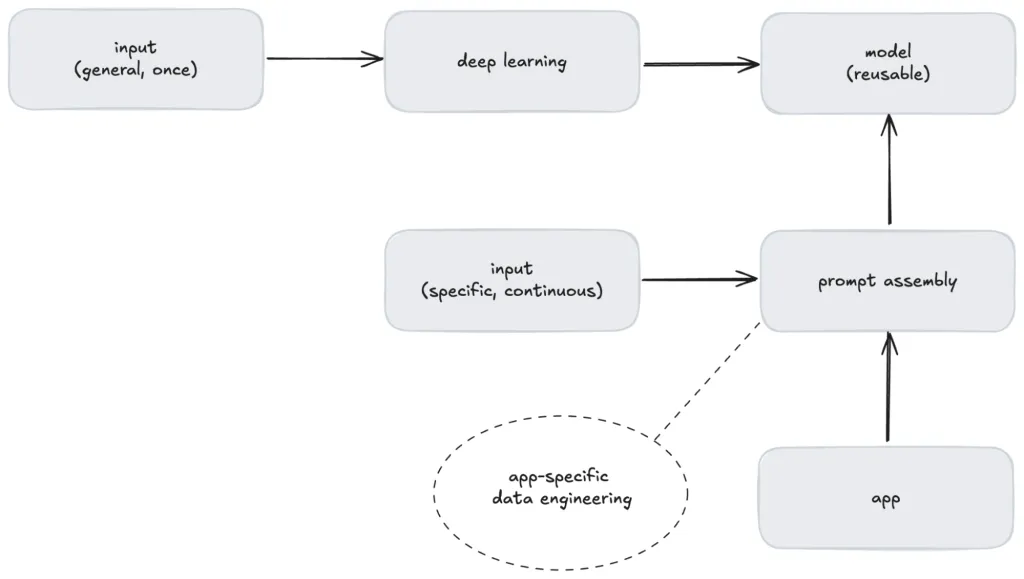
图4. 通过提示组装实现的LLM可重用性和定制性
在每分钟发表两篇医学论文、每小时解决8400起法律案件的当下,静态数据远远不够。AI系统需要实时流动的数据来给出解决方案。尽管有更好的选择,但坚持使用面向批处理的系统限制了现代应用的潜力,尤其是AI方面。是时候重新思考这种过时的方法,拥抱反映我们在动态实时的世界如何生活和工作的架构了。
LLM是外向型
当我们设计下一代AI应用程序时,可能会陷入同样的面向批处理的陷阱。我们将LLM视为数据库(等待输入并响应特定查询的响应式工具)。但这种观念与LLM具有的能力根本不匹配。AI不仅仅用于保存信息,它还用于推理、生成和进化。
数据库是内向型,保存信息,只在明确要求时才提供,而LLM是外向型,旨在参与、合成和主动贡献。它们适合于这种环境:应用情景不断变化,并且能够支持这种动态行为的架构。面向批处理的方法(模型和数据定期更新,但其他方面是静态的)扼杀了生成式AI的真正潜力。
要真正发掘AI的潜力,我们需要转变思维。
AI系统应该是工作流程的积极参与者——献计献策,参与动态对话,在一些情况下还能自主操作。这需要大幅改动架构。我们需要的不是静态的查询-响应系统,而是能够实现流畅实时的交互和灵活适应的事件驱动架构。
流处理如何发掘AI的潜力?
数据流平台支持实时需求,即支持连续的、事件驱动的工作流程来满足动态快节奏的系统需求。在金融、电信和电子商务等几毫秒事关成败的领域,面向批处理的架构力不从心。需要应用程序在交易进行时检测欺诈,在产品销售时更新库存量,或者在客户交互期间提供实时个性化。
图5. 流处理的总体示意图
面向生成式AI的流处理
生成式AI的大多数实际用例都有赖于实时的情境数据。流处理平台通过克服批处理系统无法解决的重大挑战来补充这些模型。
- 实时情境化:LLM需要最新的数据来生成有意义的响应。比如说,基于AI的航班助理需要即时访问航班延误、取消和重新预订选项。流处理平台则提供了这种实时上下文,确保AI在需要时获得所需的信息。
- 动态决策:生成式AI系统能做的不仅仅是响应查询。流处理平台允许AI对不断变化的输入做出动态反应,比如在库存量变化时调整产品推荐,或者对刚发布的新法律适用案件做出反应。
- 可扩展、解耦的架构:LLM常常需要与从CRM到分析平台的多个系统集成。流处理平台支持解耦的架构,其中每个组件可以在使用相同数据流的同时独立操作。这避免了批处理系统的瓶颈和刚性,允许AI应用程序有效地扩展。
- 减少AI工作流程的延迟:在批处理系统中,数据收集与数据处理之间的延迟可能导致过时的信息。比如说,存储客户数据的批量更新矢量数据库可能会推荐已经缺货的产品。流处理消除了这种延迟,使AI工作流程与实际情形保持一致。
代理型AI:行动而不是等待的AI
代理型AI的兴起激发了人们对并不仅限于简单的查询/响应交互的代理的兴趣。这种系统可以自主发起行动、做出决策并适应不断变化的环境。
以典型的AI代理为例。我们可以把代理看作自动化过程,对所处环境进行推理,并主动采取行动来实现某些指定的目标。它的决策可能很复杂,包含受中间数据查询影响的条件分支逻辑。
它可能需要从多个来源提取数据,处理提示工程和RAG工作流程,并直接与各种工具交互以执行确定性和随机性的工作流程。所需的编排很复杂,依赖多个系统。如果代理需要与其他代理进行联系,复杂性只会有增无减。如果没有灵活的架构,这些依赖关系使得扩展和修改几乎不可能实现。
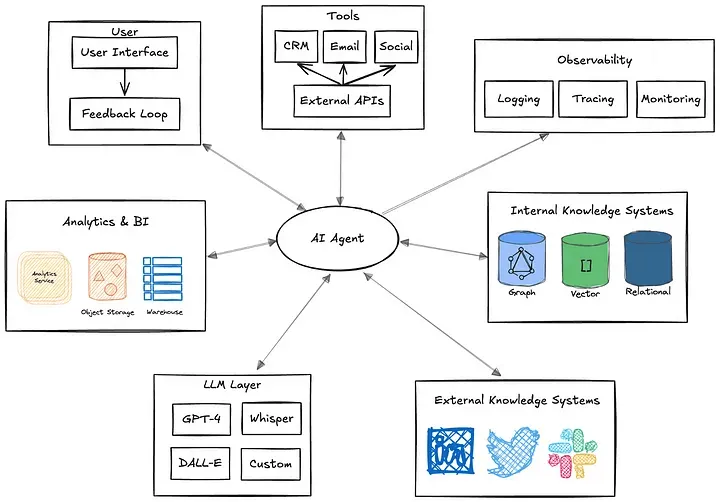
图6. 代理依赖关系概况图
要做到这一点,它们需要:
- 持续感知:实时事件流,比如库存、用户行为或系统状态等方面的变化。
- 情境推理:综合动态数据以推断意图和规划行动的能力。
- 自主决策:无需等待明确的用户指令即可执行操作,比如重新预订航班或动态调整系统配置。
比如说,使用流处理的基于AI的旅行助理可以自动监控航班时刻表、识别延误、重新预订受影响的航班并通知用户,这一切都无需人工干预。换成批量更新的静态数据,这种程度的自主就不可能实现。
流处理平台通过提供持续的低延迟数据流和实时计算必不可少的基础设施来满足这些需求。没有这个基础,自主、协作的AI系统仍是遥不可及的梦想。
流处理是生成式AI的未来
生成式AI是我们在构建和使用技术的方式上的一场根本性转变。要充分发掘其潜力,我们需要与AI处理和获得见解的方式保持一致的系统:持续、动态、实时。流处理平台为这种演变提供了基础。
如果将AI应用程序与流处理平台集成,我们就可以:
- 从被动AI系统转向主动AI系统。
- 支持实时个性化和决策。
- 确保LLM依据最新、最相关的数据运行。
- 创建可扩展的、灵活的架构,可以随AI的进步而发展。
生成式AI不仅仅旨在构建更智能的系统,还旨在构建连续的、不断变化的事件流。流处理平台使这一切成为可能,弥合了昔日静态系统与基于AI的动态未来之间的缺口。
原文标题:Stop Treating Your LLM Like a Database,作者:Sean Falconer


