
本文的第一作者是董冠霆,目前就读于中国人民大学高瓴人工智能学院,博士一年级,导师为窦志成教授和文继荣教授。他的研究方向主要包括大语言模型推理,多智能体强化学习、深度搜索智能体等。在国际顶级会议如 ICLR、ACL、AAAI 等发表了多篇论文,并在快手大模型应用组、阿里通义千问组等大模型团队进行实习。其代表性工作包括 AUTOIF、Tool-Star、RFT、Search-o1、WebThinker、Qwen2 和 Qwen2.5 等。本文的通信作者为中国人民大学的窦志成教授与快手科技的周国睿。
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM 往往需要结合外部工具进行多轮交互,现有 RL 算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
为此,我们提出了全新的 Agentic Reinforced Policy Optimization(ARPO)方法,专为多轮交互型 LLM 智能体设计。
ARPO 首次发现模型在调用外部工具后会推理不确定性(高熵)显著增加的现象,并基于此引入了熵驱动的自适应 rollout 策略,增强对高熵工具调用步骤的探索。同时,通过引入优势归因估计,模型能够更有效地理解工具交互中各步骤的价值差异。在 13 个计算推理、知识推理和深度搜索等高难基准上,ARPO 在仅使用一半工具调用预算的情况下,仍显著优于现有样本级 RL 方法,为多轮推理智能体的高效训练提供了可扩展的新方案。

论文标题:Agentic Reinforced Policy Optimization
论文链接:https://arxiv.org/abs/2507.19849
代码仓库:https://github.com/dongguanting/ARPO
开源数据 & 模型:https://huggingface.co/collections/dongguanting/arpo-688229ff8a6143fe5b4ad8ae
目前不仅在 X 上收获了超高的关注度,同时荣登 Huggingface Paper 日榜,周榜第一名🏆!
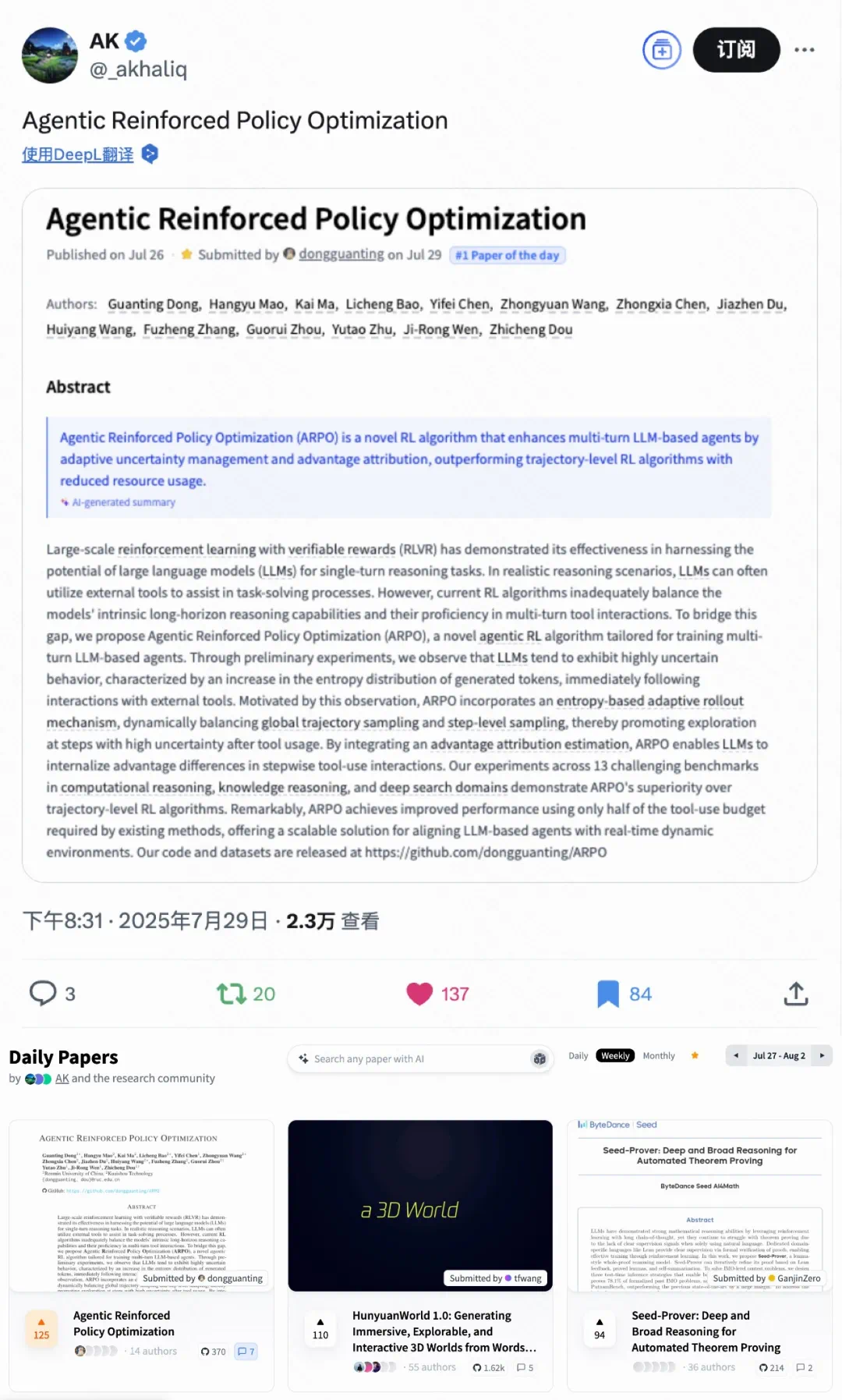
研究动机:抓住工具调用后的高熵时刻
近年来,可验证奖励的大规模强化学习在单轮推理任务中充分释放了前沿大语言模型的潜力,表现亮眼。然而,在开放式推理场景下,LLM 不仅需要具备长程规划与自适应决策能力,还需与外部工具进行动态的多轮交互。这催生了 Agentic RL 这一新范式,将训练从静态求解转向动态的智能体 - 环境推理。现有 Agentic RL 方法多采用样本级算法(如 GRPO、DAPO),在固定特殊 token 下独立采样完整的工具调用轨迹,并基于最终输出奖励模型。但这种方式常因奖励稀疏、工具过用等问题导致多轮交互价值被低估,忽视了工具调用过程中每一步的细粒度行为探索。
通过对 LLM 在深度搜索任务中的 token 熵分布进行分析,研究发现模型在每次工具调用后的初始生成阶段熵值显著升高,说明外部工具反馈会引入高不确定性,而这正是现有方法未充分利用的探索契机。
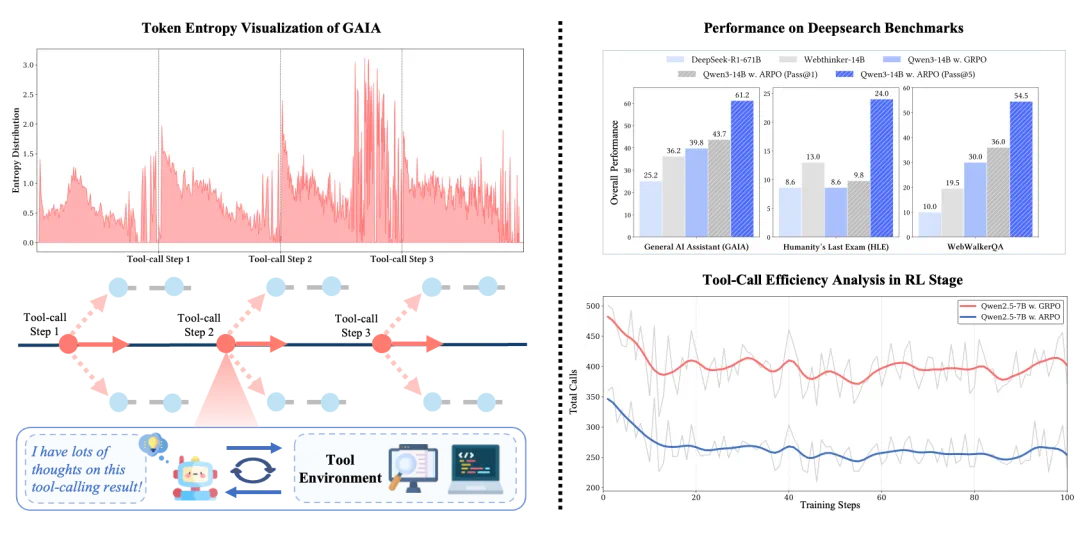
图 1:左图展示大模型在调用工具后的高熵现象,右图对比 ARPO 与基线性能
ARPO 框架:训练模型自主实现推理时的多工具调用
针对上述发现,我们提出 Agentic Reinforced Policy Optimization(ARPO),核心思想是在高熵工具调用步骤中,自适应地分支采样,探索更多多样化的推理路径。具体来说,我们的贡献如下:
我们量化了 LLM 在 Agentic 推理过程中的 token 熵变化,揭示了样本级 RL 算法在对齐 LLM 智能体方面的固有限制。
我们提出了 ARPO 算法,引入基于熵的自适应 rollout 机制,在保持全局采样的同时,在高熵工具调用步骤中鼓励分支采样。此外,ARPO 结合优势归因估计,帮助 LLM 更好地内化步骤级工具使用行为中的优势差异。
除了启发式动机,我们还从理论上论证了在 LLM 智能体训练中引入 ARPO 算法的合理性。
在 13 个高难基准上的实验表明,ARPO 在仅使用一半工具调用训练预算的情况下,性能稳定优于主流 RL 算法,为探索 Agentic RL 提供了可行性参考与实践启示。
工具调用的熵变现象:高熵时刻与探索困境
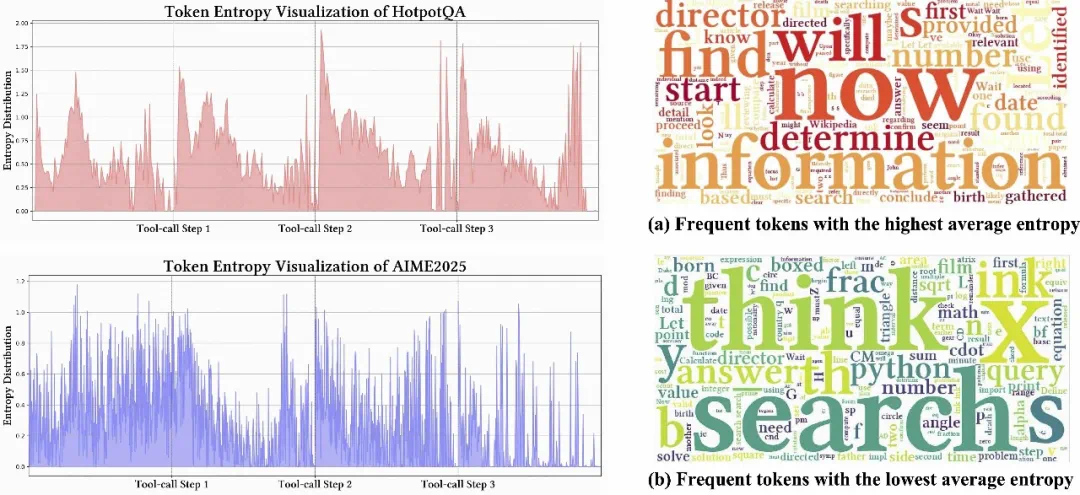
图 2:跨数据集分析基于 LLM 的工具使用智能体的 token 熵变化与 token 频率分布
通过分析大型模型在结合工具执行复杂搜索与推理任务时的 token 熵值,我们发现以下几点:
1. 在每次工具调用后的前 10–50 个 token 内,熵显著上升。
2. 在推理的初始阶段,熵往往会增加,但仍低于大模型接收到工具调用反馈后的水平。
3. 搜索引擎的反馈引入的熵波动比代码编译器的执行反馈更大。
这些现象可以归因于外部反馈与模型内部推理之间的 token 分布转移,这甚至导致引入的推理不确定性超过原始输入的问题。此外,搜索引擎通常提供丰富的文本内容,而代码编译器输出则由确定性的数字组成,这导致前者的熵波动更大。
工具设计:多样化工具支撑 Agentic 推理
本研究聚焦于优化基于 LLM 的工具使用智能体的训练算法。在梳理现有 Agentic RL 研究后,我们选取三类具有代表性的工具,用于实证评估 ARPO 的有效性:
搜索引擎:通过执行网络搜索查询检索相关信息,支持本地及在线模式。
网页浏览智能体:访问并解析搜索引擎返回的网页链接,提取并总结关键信息以响应查询。
代码解释器:自动执行 LLM 生成的代码,若执行成功则返回结果,否则返回编译错误信息。
这些工具覆盖信息检索、内容解析与程序执行等多类功能,为多轮交互与复杂推理场景提供了强有力的支撑。
ARPO 算法:利用熵信号指导 LLM 逐步优化工具调用
基于熵的自适应 rollout 机制
ARPO 的核心思想在于结合全局采样与熵驱动的局部采样,在模型工具调用后不确定性升高的阶段加大探索力度,从而提升推理效果。其基于熵的自适应 rollout 机制包含四个关键步骤:
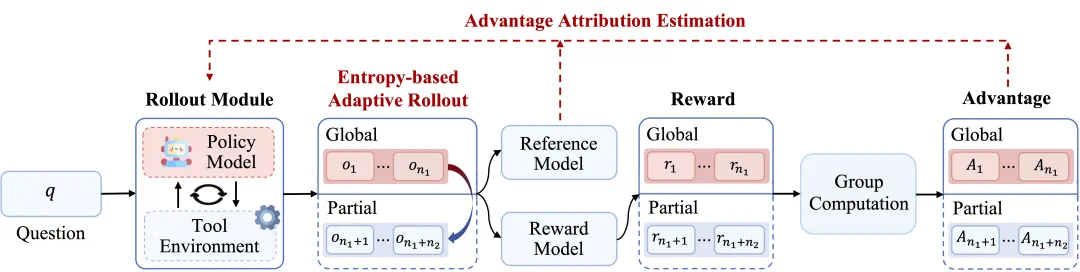
图 3:ARPO 的基于熵驱动的自适应 rollout 机制,结合全局探索与局部高熵节点分支
1. Rollout 初始化
设定全局 rollout 规模 M,首先进行样本级全局采样:LLM 针对输入问题 q 生成 N 条初始轨迹,并计算每条轨迹首个 token 的熵值,形成初始熵矩阵 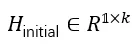 。剩余 M-N 条轨迹的采样预算保留给局部采样。
。剩余 M-N 条轨迹的采样预算保留给局部采样。
2. 熵变监控
在每次工具调用步骤 t 后,模型会在拼接工具返回结果后继续生成 k 个 token,并计算步骤级熵矩阵 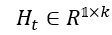 。通过
。通过 量化相对于初始状态的归一化熵变化,从而判断当前推理不确定性的变化趋势。
量化相对于初始状态的归一化熵变化,从而判断当前推理不确定性的变化趋势。
3. 基于熵的自适应分支
为引导模型在熵值显著升高的节点进行更深探索,定义工具调用步骤 t 的局部采样概率: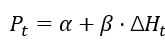
模型的分支决策如下:

该机制将探索资源自适应分配到熵上升区域,这些区域往往蕴含更高的信息增益。
4. 终止条件
Rollout 过程持续进行,直到分叉路径数达到预算上限 M-N(停止分支并完成采样)或所有路径提前终止。若预算仍有剩余,则补充全局采样以覆盖更全面的推理空间。
ARPO 通过上述机制在保证计算复杂度维持在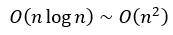 范围内的同时,实现了不确定性感知的高效探索,使大模型能够精准识别并充分利用工具调用后的高信息增益阶段。
范围内的同时,实现了不确定性感知的高效探索,使大模型能够精准识别并充分利用工具调用后的高信息增益阶段。
优势归因估计
ARPO 的熵驱动自适应 rollout 会产生包含共享推理片段和分支路径的轨迹,这启发我们优化策略更新方式,更好地利用步骤级工具调用信息。
两种优势估计方式
1. 硬优势估计(Hard)
明确区分共享和分支 token,对共享部分计算平均优势,对分支部分单独计算:
对分支 token 的优势估计:
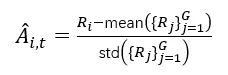
对共享 token 的优势估计:
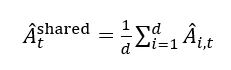
2. 软优势估计(Soft)
在策略优化过程中隐式区分共享和分支推理链的 token,通过 GRPO(Group Relative Policy Optimization)在分组更新中动态调整重要性采样比率 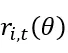 自然地处理了两类 token:
自然地处理了两类 token:
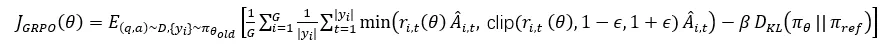
其中重要性采样比率:
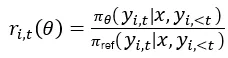
当两个轨迹在 t 步之前共享相同 token 前缀时,它们的共享 token 具有相同的重要性权重 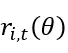 ,因此这一更新过程近似等价于硬优势估计,并且更优雅。
,因此这一更新过程近似等价于硬优势估计,并且更优雅。
实验结果证明软优势估计在 ARPO 训练中能稳定获得更高奖励,故将其设为默认优势估计方法。
分层奖励设计
ARPO 的奖励函数综合考虑答案正确性、工具调用格式及多工具协作。 如果模型在推理中使用了搜索(<search>)和代码(<python>)等多种工具,并保证答案正确且格式合规,会获得额外奖励,公式如下:

其中:

通过软优势估计与分层奖励机制,ARPO 在训练中能更平稳、更高效地优化多轮工具使用策略。
实验结果:10 + 综合推理任务评测
为了充分评估 ARPO 的泛化性和高效性,我们考虑以下三种测试集:
・ 计算型推理任务:评估模型的计算推理能力,包括 AIME24,AIME25,MATH500,GSM8K,MATH。
・ 知识密集型推理任务:评估模型结合外部知识推理的能力,包括 WebWalker,HotpotQA,2WIKI,MisiQue,Bamboogle。
・ 深度搜索任务:评估模型的深度搜索能力,包括 HLE,GAIA,SimpleQA,XBench。
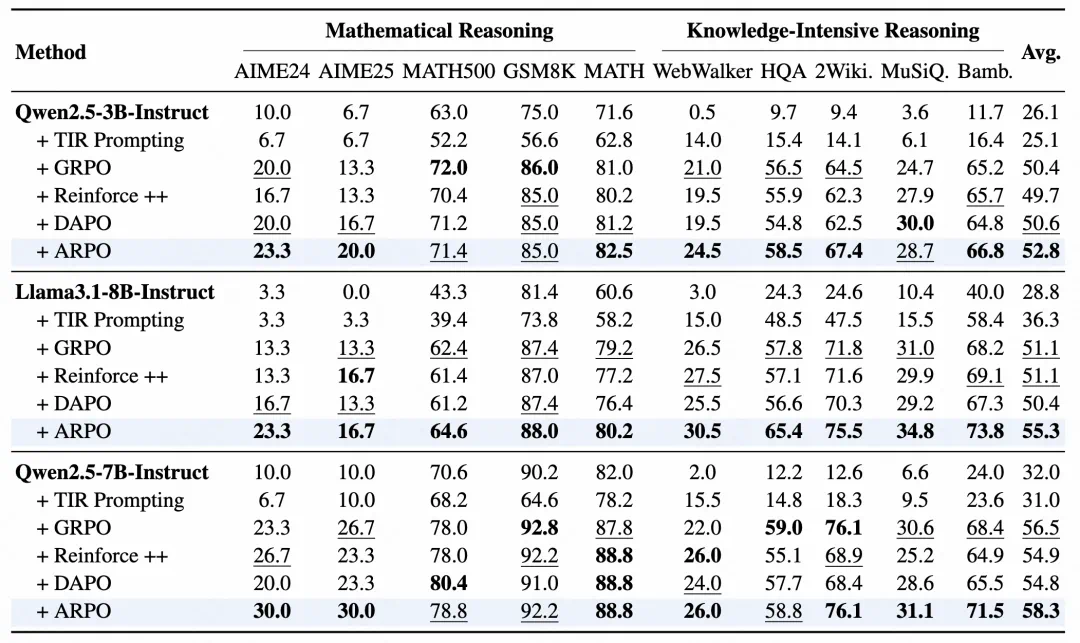
从实验结果可以发现:
ARPO 整体表现优于主流方法:ARPO 在大部分任务上准确率高于 GRPO、DAPO 等样本级 RL 方法,在工具调用密集任务(如 GAIA、HLE)中提升幅度更明显。
多任务保持稳定性能:ARPO 在计算、知识与搜索任务中均保持较好的表现,没有明显性能短板,验证其跨任务的适配能力。
实验:采样分析与工具调用效率评估
多轮采样能力提升模型表现
由于 Deepsearch 任务具有动态、多轮交互的特点,单纯使用 Pass@1 指标难以全面反映模型的工具调用潜力。我们进一步分析了 Pass@3 和 Pass@5 指标,发现无论是 8B 还是 14B 规模模型,在经过 ARPO 对齐训练后,均表现出持续提升和良好的规模效应。其中,14B 模型在 Pass@5 指标上表现尤为出色:
GAIA 达到 61.2%
HLE 达到 24.0%
XBench-DR 达到 59%
工具调用效率显著提升
在 Agentic RL 训练中,工具调用次数直接影响成本。我们以 Qwen2.5-7B 模型为例,将 ARPO 与 GRPO 方法进行对比
ARPO 在整体准确率上优于 GRPO
同时仅使用了约一半的工具调用次数
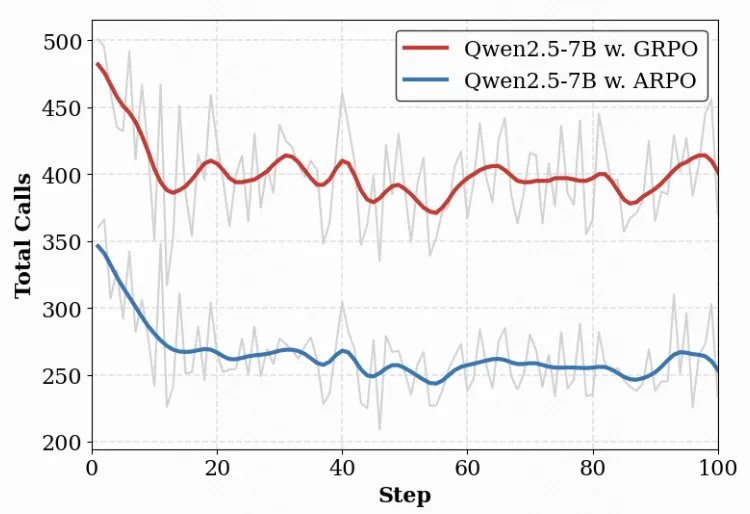
这得益于 ARPO 独特的基于熵的自适应采样机制,仅在高熵工具调用步骤进行分支采样,极大地扩展了工具行为的探索空间,同时降低了不必要的调用。
总结与未来展望
ARPO 算法有效提升了多轮工具推理代理的性能,解决了现有样本级 RL 方法在多轮交互中探索不足、泛化能力欠缺的问题。通过熵驱动自适应采样和优势归因机制,ARPO 能够在工具调用频繁、推理路径复杂的任务中实现更高效、更稳定的输出。未来,为持续提升 Agentic RL 模型的能力,仍有多个方向值得探索:
多模态 Agentic RL:ARPO 目前主要针对文本推理任务,在处理图像、视频等多模态信息方面仍有局限。未来可扩展至多模态任务中,探索模型在多模态场景下的工具调用与策略优化。
工具生态扩展:ARPO 已经验证了在多工具协作任务上的潜能。未来可引入更多类型的外部工具(如代码调试器、数据分析工具、实时 API 调用等),并通过工具使用策略优化进一步提升复杂任务表现。
大规模与实时部署:ARPO 展示了较高的训练效率和推理泛化性,未来可探索在更大规模模型和实时动态环境中的部署与适配,降低成本同时提升实用价值。


