译者 | 朱先忠
审校 | 重楼
Sesame使用一种名为残差向量量化的深度学习技术对语音进行编码
最近,Sesame人工智能公司发布了他们最新的语音转语音(Speech-to-Speech)模型的演示。这是一个非常擅长说话的对话式人工智能代理,它们能够提供相关的答案,并带有表情地说话,而且说实话,它们非常有趣,互动性很强。
请注意,有关这方面的系统的技术论文尚未发布,但他们确实发布了一篇简短的博客文章,并提供了有关他们使用的技术和他们所构建的先前算法的大量信息。
谢天谢地,他们提供了足够的信息,让我能够撰写这篇文章并制作一个YouTube视频。
训练对话语音模型
Sesame是一个会话语音模型,简称CSM。它输入文本和音频,并将语音生成音频。虽然他们没有在文章中透露其训练数据来源,但我们仍然可以尝试进行可靠的猜测。上述博客文章大量引用了另一个CSM,即2024年的Moshi模型,幸运的是,Moshi模型的创建者在他们的论文中透露了他们的数据来源。Moshi模型使用了700万小时的无监督语音数据、170小时的自然和脚本对话(用于多流训练)以及2000多个小时的电话对话(Fischer数据集)。

Sesame模型是建立在Moshi模型论文(2024)基础上的
生成音频到底需要什么?
原始形式的音频只是一长串振幅值 ——波形。例如,如果以24kHz的频率采样音频,则每秒捕获24,000个浮点值。
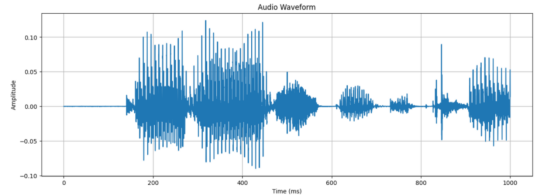
这里使用24000个值来表示1秒的语音!(图片由作者生成)
当然,处理一秒钟的数据中的24000个浮点值是非常耗费资源的,尤其是因为Transformer的计算量会随着序列长度的平方而增长。如果我们能够压缩这个信号并减少处理音频所需的样本数量,那就太好了。
后面,我们将深入探讨Mimi编码器,特别是残差向量量化器(RVQ),它们是当今深度学习中音频/语音建模的支柱。文章最后,我们将介绍Sesame模型如何使用其特殊的双转换器架构生成音频。
预处理音频
卷积在压缩和特征提取方面大有裨益。Sesame模型使用Mimi语音编码器来处理音频。Mimi也曾在前面提到的Moshi论文中被介绍过。Mimi是一个自监督音频编解码器模型,它首先将音频波形转换为离散的“潜在”标记,然后重建原始信号。Sesame仅使用Mimi的编码器部分来对输入的音频进行标记。让我们来仔细了解一下这是如何操作的。
Mimi输入24Khz的原始语音波形,并将其传入多个步幅卷积层,对信号进行下采样,步幅分别为4、5、6、8和2。这意味着,第一个CNN模块将音频下采样4倍,然后是5倍,再是6倍,以此类推。最终,它以1920的倍数下采样,将帧率降至每秒12.5帧。
卷积块还将原始浮点值投影到512的嵌入维度。每个嵌入聚合原始1D波形的局部特征。1秒的音频现在表示为大约12个大小为512的向量。这样,Mimi将序列长度从24000减少到仅12,并将它们转换为密集的连续向量。

在应用任何量化之前,Mimi编码器会将输入的24KHz音频下采样1920倍,并将其嵌入到512维空间中。换句话说,每秒可以获得12.5帧,每帧都是一个512维向量(图片来自作者视频)。
什么是音频量化?
给定卷积层之后获得的连续嵌入,我们希望对输入语音进行标记化。如果我们可以将语音表示为一系列标记,那么我们就可以应用标准的语言学习Transformer来训练生成模型。
Mimi使用残差向量量化器(RVQ分词器)来实现这一点。我们很快会讨论残差部分,但首先,我们先来看看一个简单的vanilla向量量化器是如何做的。
向量量化
向量量化背后的想法很简单:训练一个码本(codebook ),它是1000个随机向量代码的集合,大小均为512(与嵌入维度相同)。
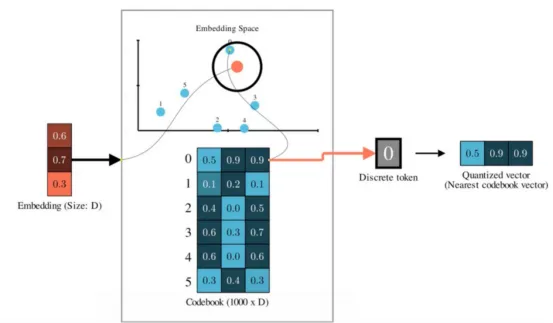
一个Vanilla向量量化器。训练一个嵌入的码本。给定一个输入嵌入,我们将其映射/量化到最近的码本条目(作者视频截图)
然后,给定输入向量,我们将其映射到码本中最近的向量——本质上就是将一个点映射到其最近的聚类中心。这意味着,我们有效地创建了一个固定的标记词汇表来表示每个音频帧,因为无论输入帧的嵌入是什么,我们都将用最近的聚类质心来表示它。
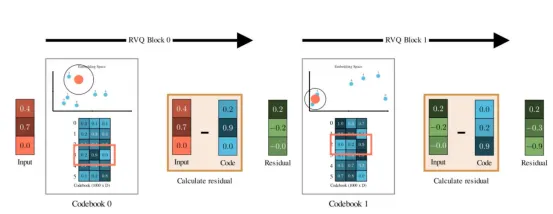
残差向量量化
简单的向量量化的问题在于,由于我们将每个向量映射到其聚类的质心,信息损失可能过高。这种“映射”很少是完美的,因此原始嵌入和最近的码本之间总是存在误差。
残差向量量化的核心思想是,它不仅仅局限于一个码本。相反,它尝试使用多个码本来表示输入向量。
- 首先,使用第一个码本量化原始向量。
- 然后,从原始向量中减去该质心。剩下的就是残差—— 即第一次量化中未捕获的误差。
- 现在取这个残差,并使用充满全新代码向量的第二个代码本 再次对其进行量化——再次将其捕捉到最近的质心。
- 减去这个值,你会得到一个更小的残差。用第三个码本再次量化……你可以对任意数量的码本重复此操作。
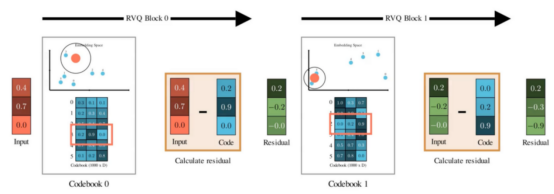
残差向量量化器(RVQ)使用新的码本和VQ层对输入嵌入进行分层编码,以表示先前码本的误差
每一步都会逐层捕捉上一轮遗漏的细节。假设你对N个码本重复此操作,那么你将从每个量化阶段获得一个由N个离散标记组成的集合,用来表示一个音频帧。
RVQ最酷的地方在于,它们被设计成在第一个量化器中具有较高的归纳偏差,倾向于捕捉最重要的内容。在后续的量化器中,它们会学习越来越细粒度的特征。
如果您熟悉PCA,可以认为第一个码本包含主要主成分,用于捕获最关键的信息。后续码本代表高阶成分,包含更多细节信息。
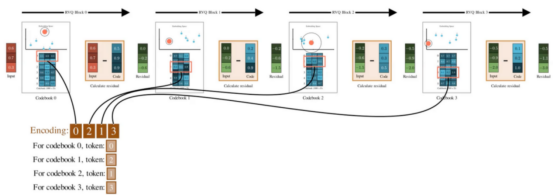
残差向量量化器(RVQ)使用多个码本对输入向量进行编码——每个码本一个条目(作者视频截图)
声学与语义密码本
由于Mimi是针对音频重建任务进行训练的,因此编码器会将信号压缩到离散化的潜在空间,而解码器则会从潜在空间将其重建回来。在针对此任务进行优化时,RVQ码本会学习在压缩的潜在空间内捕捉输入音频的基本声学内容。
Mimi还单独训练了一个码本(原始VQ),该码本专注于嵌入音频的语义内容。正因如此,Mimi被称为“分割RVQ分词器”——它将量化过程划分为两个独立的并行路径:一个用于语义信息,另一个用于声学信息。
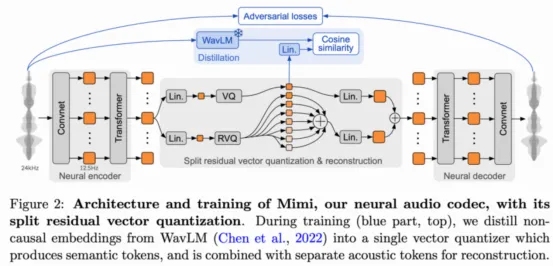
Mimi架构(来源:Moshi论文)许可证:免费
为了训练语义表征,Mimi使用知识蒸馏技术,并使用现有的语音模型WavLM作为语义教师。Mimi引入了一个额外的损失函数,用于减小语义RVQ代码与WavLM生成的嵌入之间的余弦距离。
音频解码器
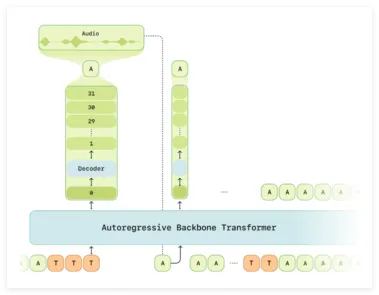
给定一个包含文本和音频的对话,我们首先使用文本和音频标记器将它们转换为一个标记嵌入序列。然后,该标记序列作为时间序列输入到转换器模型中。在作者的博客文章中,该模型被称为自回归骨干转换器(Autoregressive Backbone Transformer)。它的任务是处理该时间序列并输出“第零个”码本标记。
然后,一个称为音频解码器的轻量级转换器会根据主干转换器生成的第零个代码,重建下一个码本标记。需要注意的是,由于主干转换器能够看到整个过去的序列,因此第零个代码已经包含了大量关于对话历史的信息。轻量级音频解码器仅对第零个标记进行操作,并生成其余N-1个代码。这些代码由N-1个不同的线性层生成,这些线性层输出从其对应码本中选择每个代码的概率。
你可以把这个过程想象成在纯文本的LLM中根据词汇表预测文本标记。只不过,基于文本的LLM只有一个词汇表,而RVQ标记器则以N个码本的形式拥有多个词汇表,因此你需要训练一个单独的线性层来为每个词汇表建模码本。
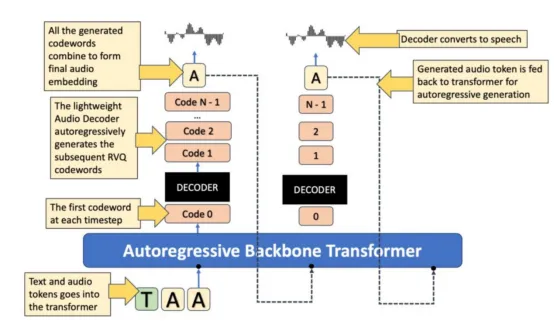
Sesame架构
最后,所有码字生成完成后,我们将它们聚合起来,形成组合的连续音频嵌入。最后一步是将音频转换回波形。为此,我们应用转置卷积层将嵌入从12.5Hz升频回kHz波形音频。本质上,这相当于逆转了我们在音频预处理过程中最初应用的变换。
总结

观看本文附带的视频!(作者视频)
以下是针对Sesame模型的一些要点的总结:
- Sesame建立在多模式对话语音模型或CSM之上。
- 文本和音频一起被标记以形成标记序列,并输入到主干转换器中,该转换器对该序列进行自回归处理。
- 虽然文本的处理方式与其他基于文本的LLM类似,但音频的处理则直接基于其波形表示。他们使用Mimi编码器,通过分割RVQ标记器将波形转换为潜在代码。
- 多模态骨干变换器消耗一系列标记并预测下一个第零个码字。
- 另一个称为音频解码器的轻量级转换器根据第零个代码字预测下一个代码字。
- 最终的音频帧表示是通过组合所有生成的码字并上采样回波形表示而生成的。
参考文献和必读论文
- 查看我的ML YouTube频道
- Sesame模型博客文章和演示
- 相关论文:
Moshi:https://arxiv.org/abs/2410.00037
SoundStream:https://arxiv.org/abs/2107.03312
HuBert:https://arxiv.org/abs/2106.07447
Speech Tokenizer:https://arxiv.org/abs/2308.16692
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Sesame Speech Model: How This Viral AI Model Generates Human-Like Speech,作者:Avishek Biswas