1192个GPU削减到213个,82%的用量削减——当我看到阿里云Aegaeon系统在三个月测试中的这个数据时,第一反应是这怎么可能?
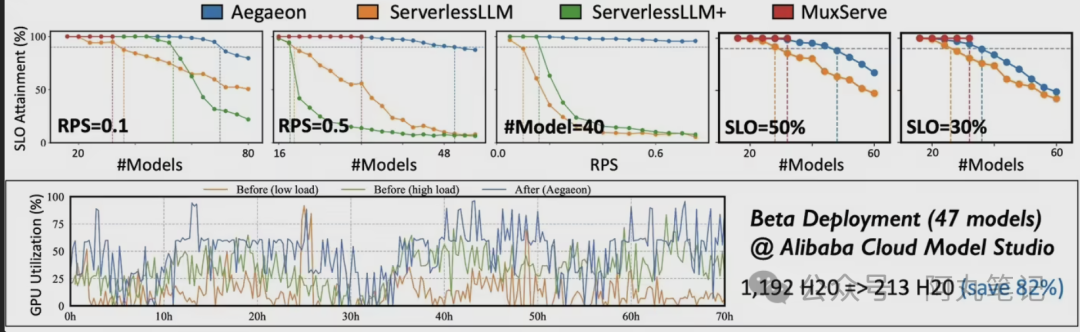
要知道,这可是在服务数十个720亿参数大模型的情况下实现的。按照现在H20 GPU的价格,这意味着硬件成本直接砍掉了80%以上。
更让人意外的是,这套系统不仅没有影响性能,反而在某些指标上还有提升。单GPU能同时服务7个不同模型,吞吐量比现有方案提升1.5-9倍。
GPU资源浪费到底有多严重?
我特意去了解了一下现在AI模型服务的现状,发现问题确实挺严重的。
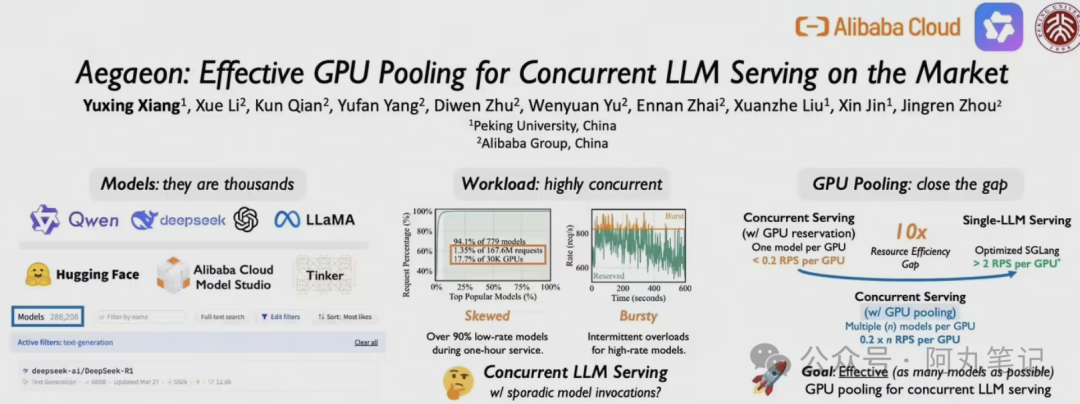
在阿里云模型市场的真实数据中,有17.7%的GPU算力只用来处理1.35%的用户请求。这就像是一个大型停车场,80%的车位都被长期闲置的车辆占着,而真正需要停车的人却找不到位置。
造成这种浪费的根本原因是传统的"一个模型绑定一个GPU"模式。每个AI模型都要独占一张或多张GPU卡,不管用户请求多少,GPU都得24小时待命。热门模型像Qwen这种,一天到晚忙得不行;而那些长尾模型,可能一小时才来几个请求,但GPU还是得老老实实等着。
这就好比每个员工都要配一个专属办公室,不管他一天工作8小时还是1小时,房租都得照付。
Aegaeon是怎么做到的?
阿里云的解决思路其实挺巧妙的:既然GPU闲着也是闲着,为什么不让它同时服务多个模型?
但这里面有个技术难点:AI模型生成文本是一个token一个token往外蹦的,每生成一个词,都需要基于前面所有内容进行计算。如果要在多个模型之间切换,就得保存和恢复大量的中间状态,这个开销可能比收益还大。
Aegaeon的核心创新就是Token级调度。简单说,就是每生成一个token后,系统会动态判断:是继续用当前模型,还是切换到其他有请求等待的模型?
为了让这种频繁切换变得可行,他们做了几个关键优化:
• 组件复用 - 不同模型的相同组件可以共享,减少重复加载
• 显存精细化管理 - 更智能的内存分配和回收机制
• KV缓存同步优化 - 加速模型状态的保存和恢复
最终的效果是,模型切换开销降低了97%,可以做到亚秒级响应。用户基本感觉不到延迟,但GPU的利用率却大幅提升了。
这个技术有多重要?
说实话,我觉得这可能是今年AI基础设施领域最重要的突破之一。
首先是成本层面。现在训练和部署大模型的成本高得离谱,动不动就是几千万美元的GPU采购。如果能把硬件需求砍掉80%,那对整个行业的影响是巨大的。
更重要的是,这降低了AI服务的门槛。以前可能只有大厂才玩得起大模型服务,现在中小公司也有机会用更少的资源提供更多样化的AI服务。
而且这个技术已经不是纸上谈兵了。Aegaeon的论文被SOSP 2025接收,这是系统软件领域的顶级会议。核心技术也已经在阿里云百炼平台上线运行。
阿里云CEO吴泳铭在云栖大会上说:"大模型是下一代操作系统,AI云是下一代计算机。"从这个角度看,Aegaeon更像是给这台"下一代计算机"装了一个更高效的资源调度器。
当然,这个技术也不是万能的。它主要解决的是多模型并发服务的场景,对于单一模型的大规模推理,效果可能没那么明显。而且Token级调度虽然开销很小,但在极高并发的情况下,调度本身也可能成为瓶颈。
不过总的来说,我觉得这是一个很有价值的技术方向。随着AI模型越来越多样化,如何更高效地利用计算资源,肯定会成为一个越来越重要的问题。
阿里云这次算是给出了一个不错的答案。82%的资源节省,听起来确实挺震撼的。


