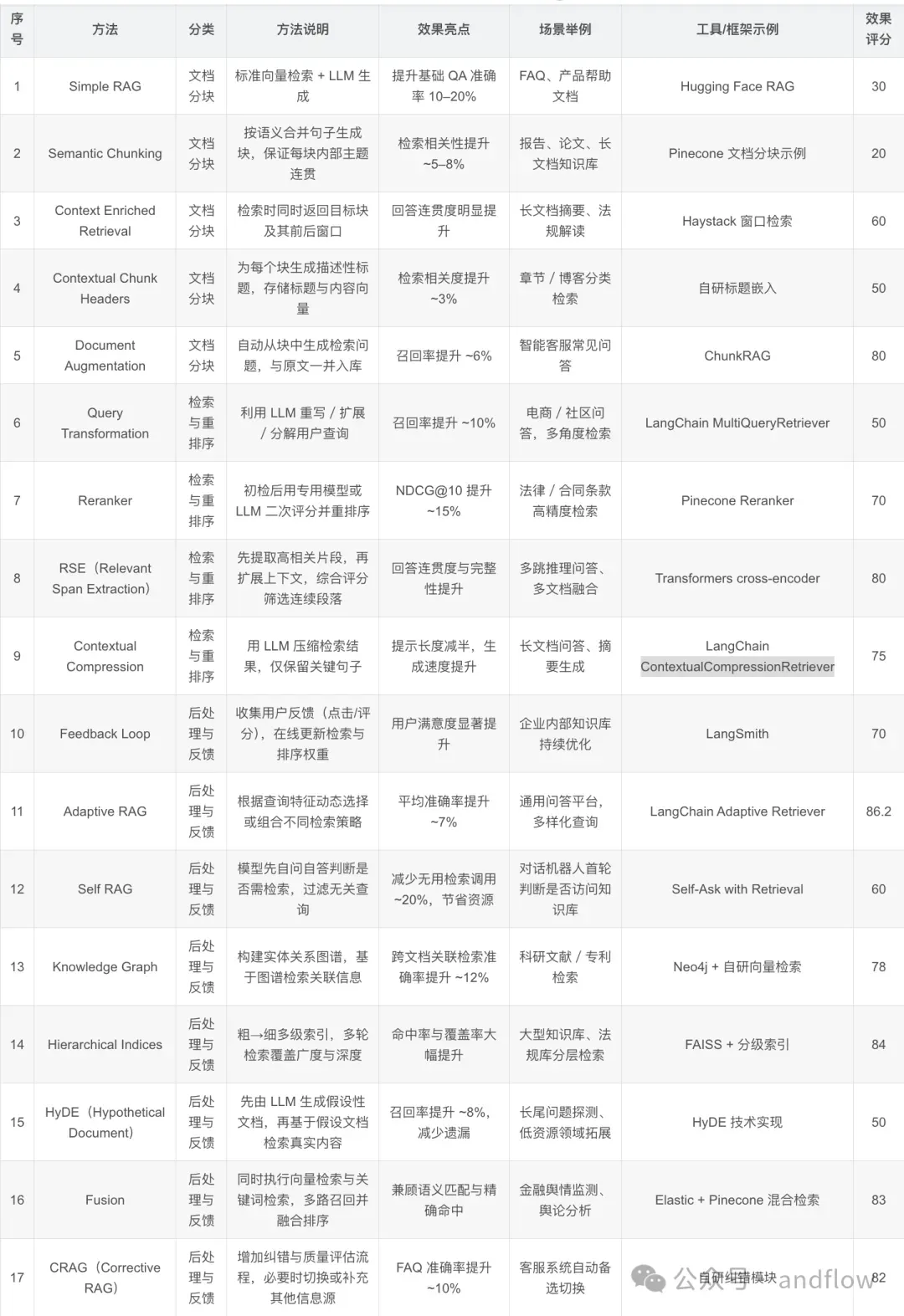
RAG(Retrieval-Augmented Generation)是一种结合外部知识检索与语言模型生成的混合技术架构。它在大型语言模型(如 GPT)生成能力的基础上,通过外部知识库提高了准确性、时效性和可控性,广泛用于企业问答、搜索增强、智能客服、代码辅助、知识图谱等场景。
然而,RAG不是一个固定结构,也没有固定的套路,而是一套可以灵活演化的系统。
本文将结合当前主流实践,分析三类策略,17种 RAG 实现方法的技术原理,帮助你选择最适合业务场景的方案。

一、文档分块策略(方法1~5)
1. Simple RAG(基础版)
原理:将问题向量化 → 检索向量库中的文档片段 → 拼接后交给LLM生成。
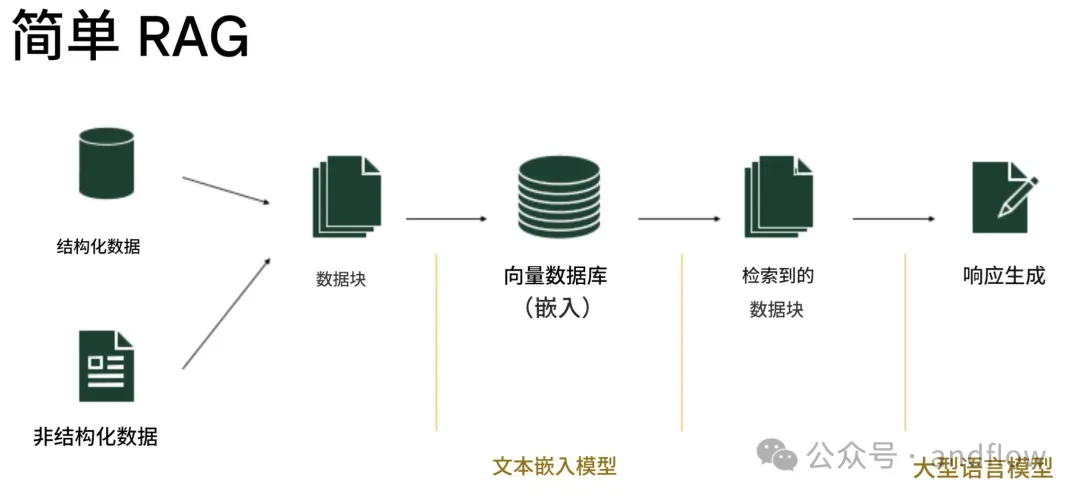
2. Semantic Chunking(语义分块)
原理:
- 使用语言模型或句法树对文档进行语义切分,而非按字符或固定长度分块。
- 保证块的完整语义。
- 提高召回质量。
技术方案:NLTK + Transformer Embedding + 动态窗口切割
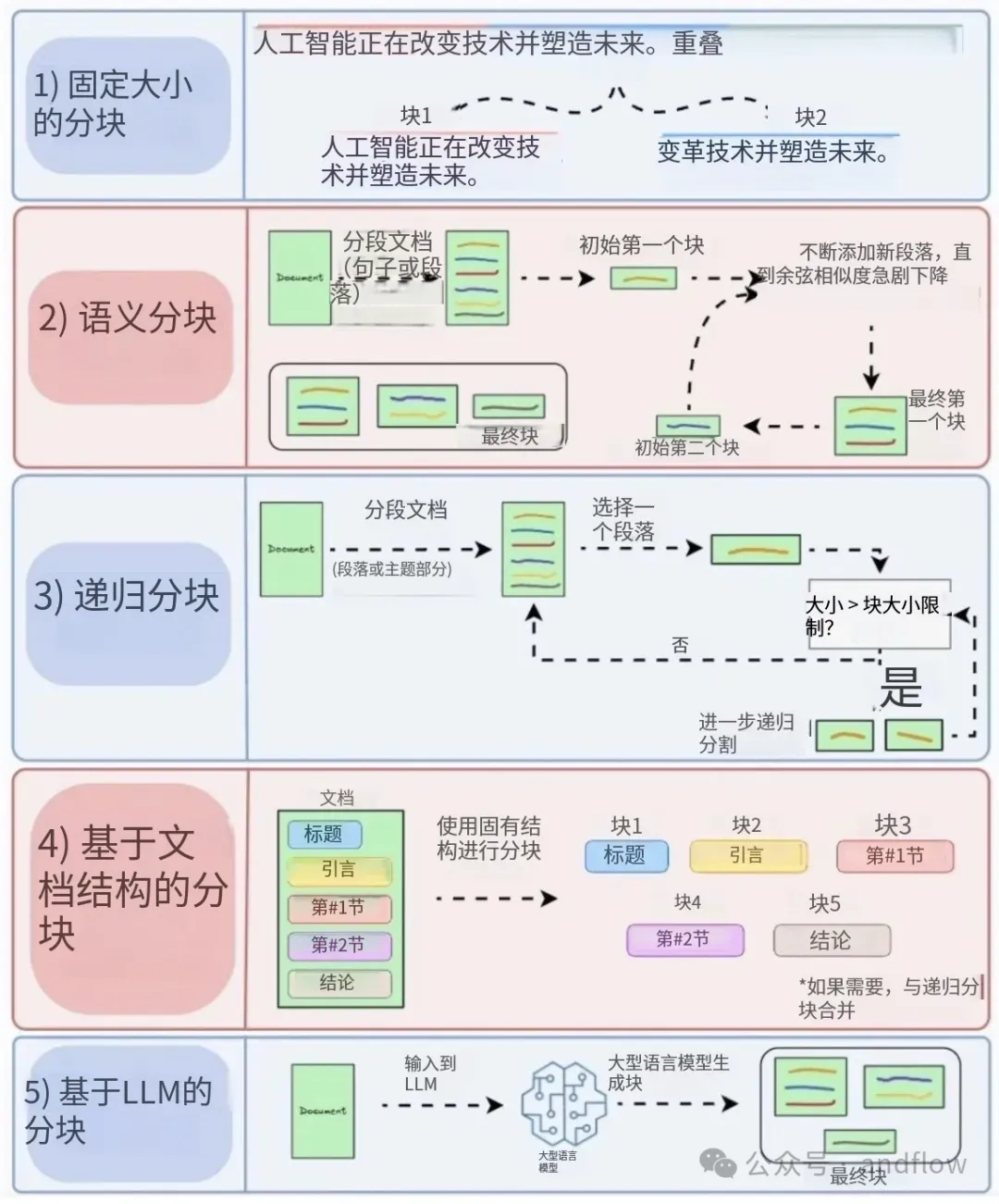
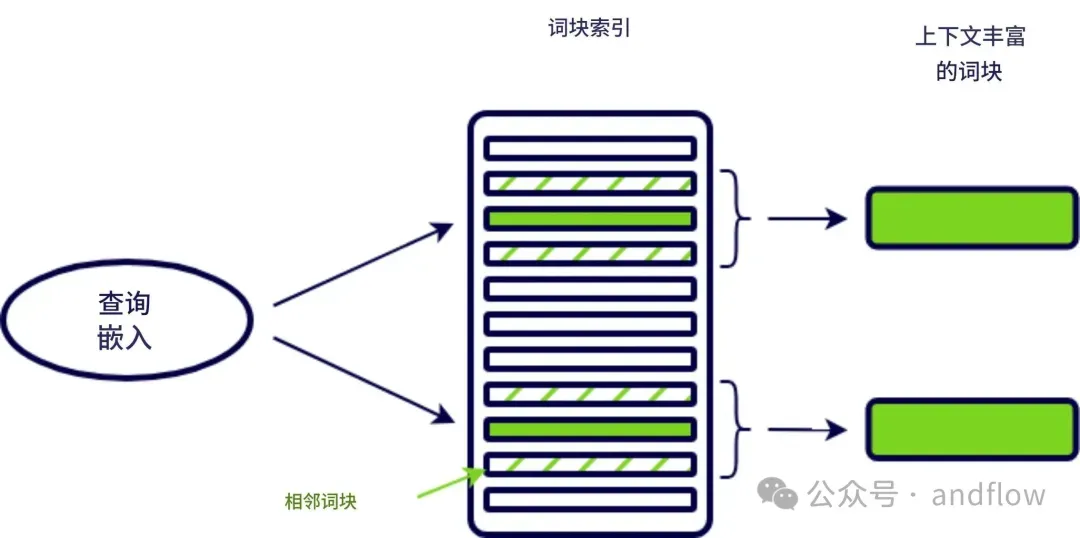
3. Context Enriched Retrieval(上下文增强)
原理:
- 每个块包含其前后邻居段落,实现“块+上下文”的完整语义输入。
- 上下文丰富,回答更准确。
- 支持滑动窗口式切块。
4. Contextual Chunk Headers(块头标签)
原理:
- 提取章节名、标题等结构性标签,与正文一起向量化。
- 增强分类与上下文提示能力。
- 适合结构明确的文档。
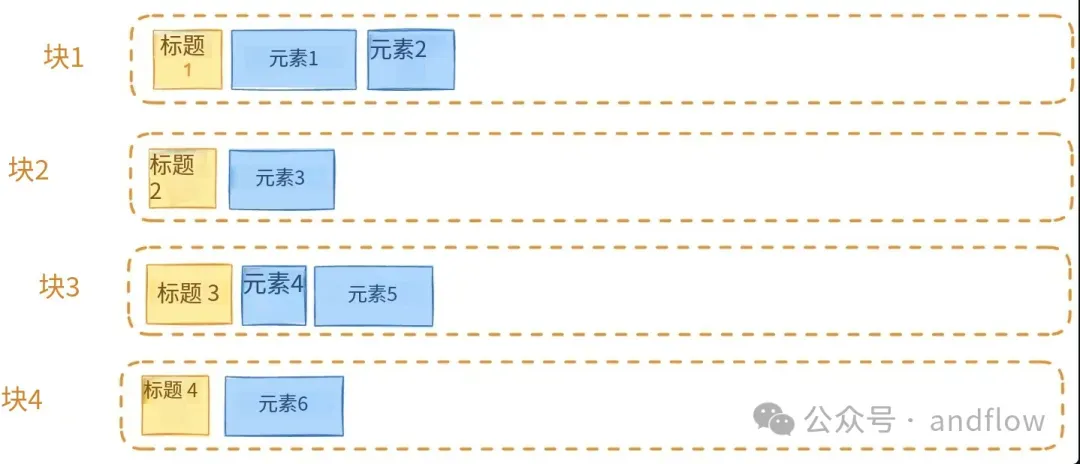
5. Document Augmentation(文档增强)
原理:
- 对每个文档构造多个“视图”:标题、摘要、正文、元数据等,统一入库。
- 多角度增强检索命中率。
工具:ChunkRAG、DocView RAG。
二、检索与排序增强(方法6~9)
6. Query Transformation(查询改写)
原理:
- 用LLM将用户输入的问题生成多个语义等价问法,再分别进行向量检索。
- 提高低质量输入的召回能力。
支持:LangChain MultiQueryRetriever
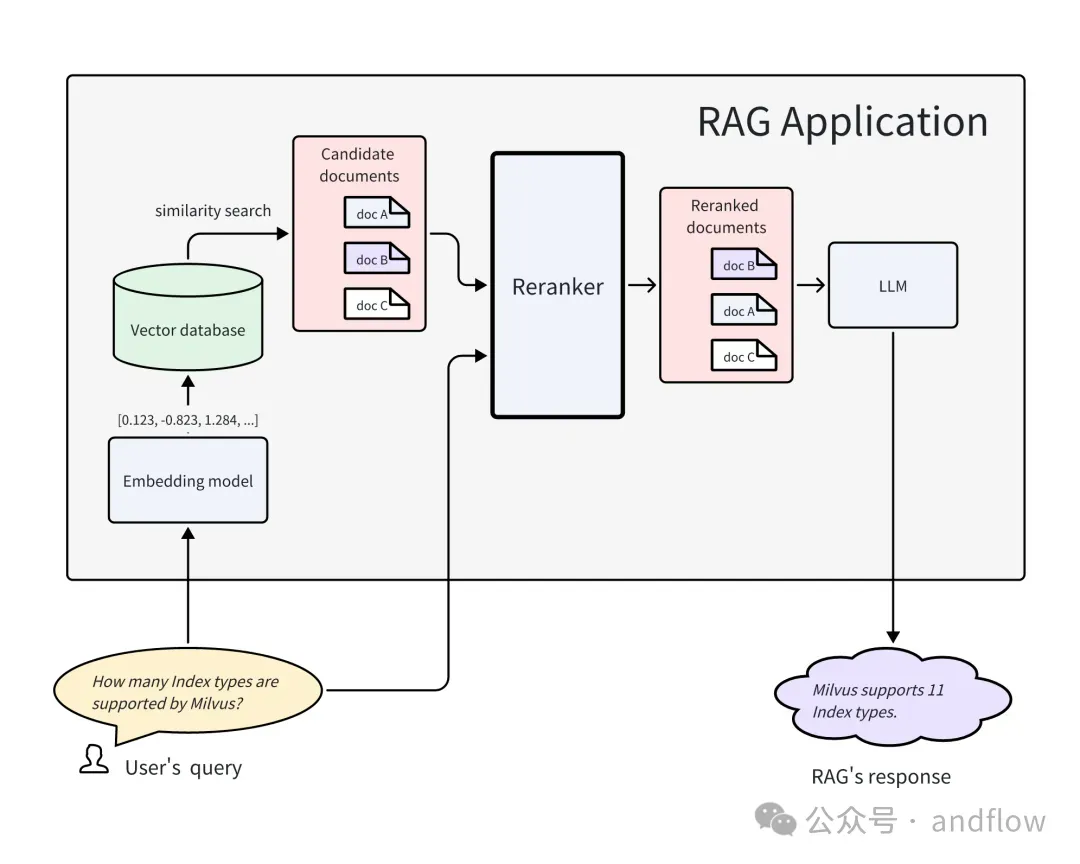
7. Reranker(重排序)
原理:
- 对初步召回的TopK候选文档,使用Cross-Encoder/BERT重新打分并排序。
- 提升最终选中文档的相关性。
模型:MonoT5, Cohere Reranker
8. RSE(Relevant Span Extraction)
原理:在长文档中定位与问题最相关的“片段/句子”,而非整段。
精准回答,提高可控性。
技术:交叉编码器 + Pointer Network
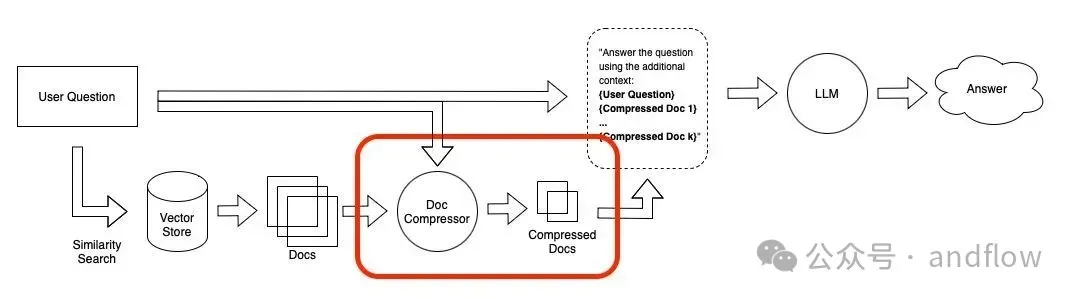
9. Contextual Compression(上下文压缩)
原理:对检索结果执行“信息压缩”,剔除无关内容,保留关键句子或段落。
降低Token成本,提高输入效率。
工具:LangChain Compression Retriever
三、后处理与反馈优化(方法10~17)
10. Feedback Loop(反馈回流)
原理:将用户点击、满意度等行为数据用于排序模型优化,形成“人反馈 → 系统进化”的闭环。
常见于智能客服、企业知识图谱。
11. Adaptive RAG(自适应检索)
原理:使用小模型或规则识别问题类型,动态选择检索策略(如:是否用rerank?是否多Query?)。
强适配多业务场景。
技术组合:LangChain Router + MultiVector Retriever
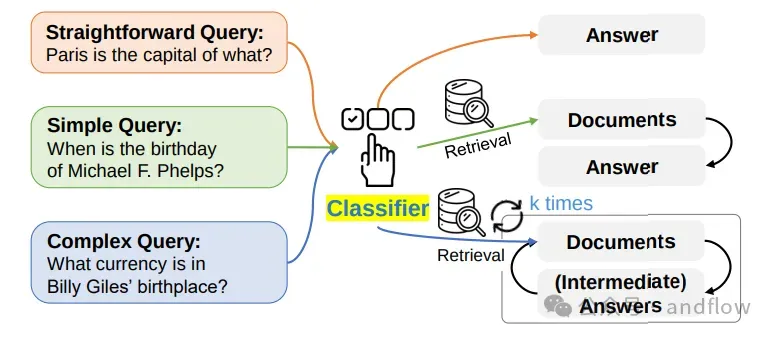
12. Self RAG(自我决策RAG)
原理:模型判断是否需要外部知识支持;若能直接回答,则跳过检索流程。
提升效率,节省资源。
Prompt示例:“你是否可以直接回答该问题?若不能,请说明所需信息。”
13. Knowledge Graph(知识图谱)
原理:将文档转为结构化的三元组图谱,进行图谱检索或路径推理。
支持语义联想、实体关系解释。
工具:Neo4j、KGLM + 图谱嵌入模型
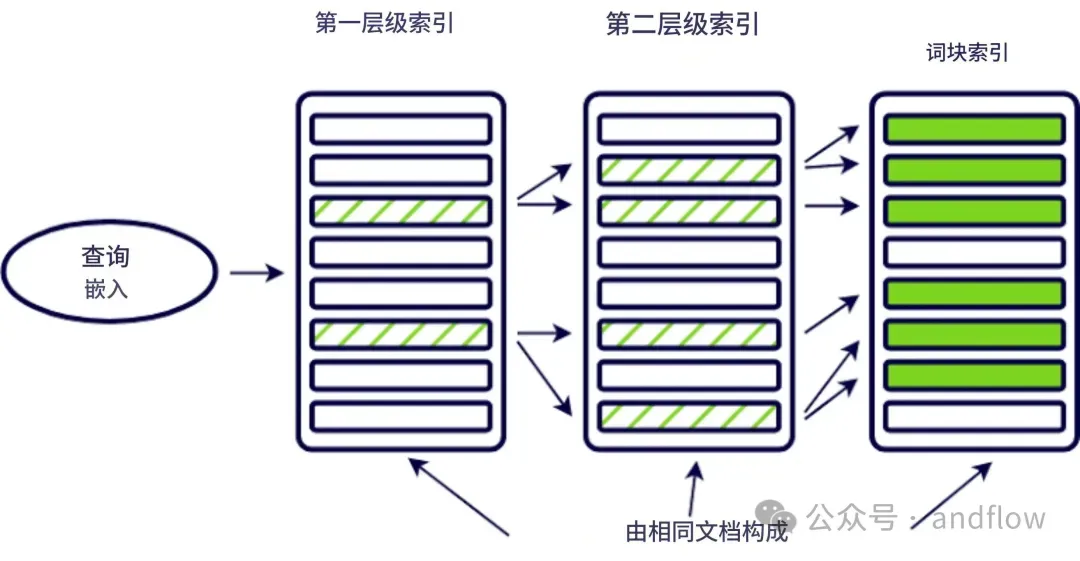
14. Hierarchical Indices(多级索引)
原理:对文档构建目录级别的分层索引结构,按层检索节省计算开销。
类似“分区检索”。
技术:Nested FAISS / TreeIndex
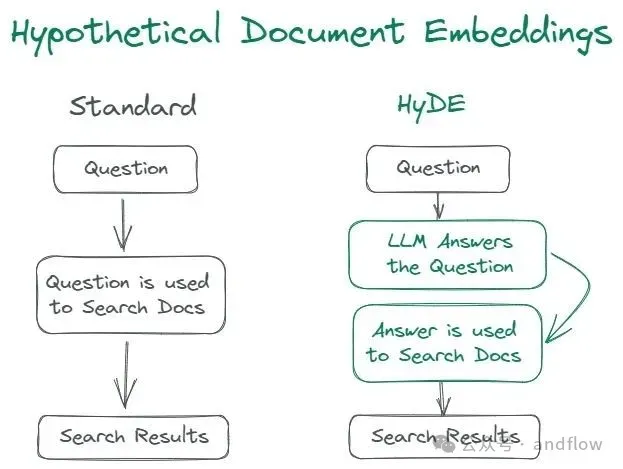
15. HyDE(Hypothetical Document Embedding)
原理:模型先尝试生成“理想答案”,再基于该答案反向检索可能支持材料。
特别适合文档碎片化严重或长问句。
实现:LLM + 向量化再检索
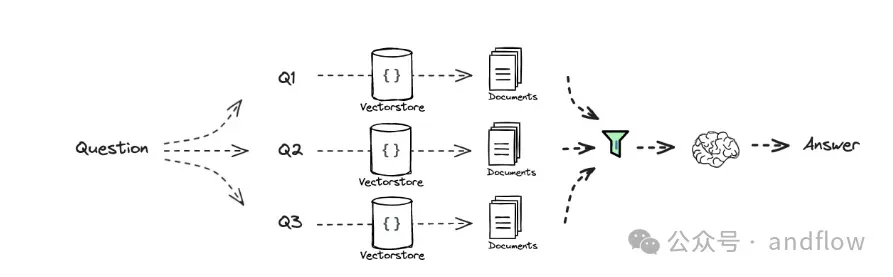
16. Fusion(结果融合检索)
原理:同时使用多个检索通道(如语义+关键词),合并得分后进行排序。
平衡精确度与召回率。
工具组合:Pinecone + Elastic
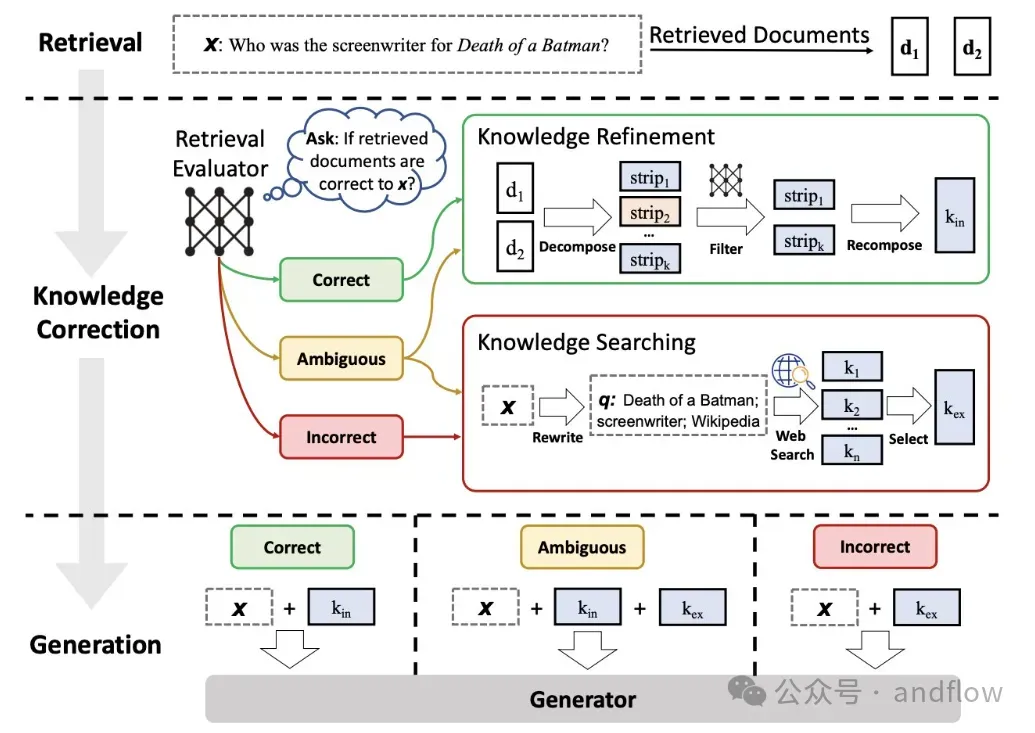
17. CRAG(纠错式RAG)
原理:在检索前使用纠错模块改写用户提问,修复错别字、语法错误或上下文缺失。
提高“非专业提问”的识别能力。
工具:SpellCheck + Query Rewriter + Prompt Template
最后
如何选择合适的 RAG 架构?下面是一组选型推荐,但凡事也没有绝对,需要结合实际场景进行设计。
应用目标 | 推荐方法 |
快速上线 | Simple RAG、Semantic Chunking |
提高准确性 | Reranker、RSE、Context Enriched Retrieval |
提升召回与覆盖 | Query Transformation、Fusion、Augmentation |
优化成本或效率 | Self RAG、Contextual Compression |
结构化场景支持 | Knowledge Graph、Hierarchical Indices |
用户行为优化 | Feedback Loop、Adaptive RAG |
容错性强、问题补全 | CRAG、HyDE |
总之,在实际生产运行中,RAG 不是一个简单的“检索+拼接”套路,而是一整套可定制、可演进的系统架构。从文档处理、检索策略,到后处理优化,每个环节都能独立优化与组合。
以下是17种方法的汇总表: