近期,Kimi在语音交互领域发布了Kimi-Audio模型,这是一个开源音频基础模型,在音频理解、生成和对话方面表现出色。

AI让机器不仅 “听到” 声音,更能 “听懂” 语言背后的情感、意图和语境。Kimi-Audio 的核心突破,在于构建了一个全流程端到端的实时语音对话系统。能够在一个统一的框架内处理各种音频处理任务。主要功能包括:
- 通用功能:处理各种任务,如自动语音识别 (ASR)、音频问答 (AQA)、自动音频字幕 (AAC)、语音情感识别 (SER)、声音事件/场景分类 (SEC/ASC) 和端到端语音对话。
- 最先进的性能:在众多音频基准测试中取得 SOTA 结果(参见评估和技术报告)。
- 大规模预训练:对超过 1300 万小时的不同音频数据(语音、音乐、声音)和文本数据进行预训练,实现强大的音频推理和语言理解。
- 新颖的架构:采用混合音频输入(连续声学向量+离散语义标记)和具有并行头的 LLM 核心来生成文本和音频标记。
- 高效推理:采用基于流匹配的分块流式去标记器,实现低延迟音频生成。
- 开源:发布预训练和指令微调的代码和模型检查点,并发布全面的评估工具包以促进社区研究和开发。
相关链接
- 论文:
- 模型:https://huggingface.co/moonshotai/Kimi-Audio-7B
- 代码:https://github.com/MoonshotAI/Kimi-Audio
论文介绍
 Kimi-Audio是一个在音频理解、生成和对话方面表现卓越的开源音频基础模型。论文介绍了 Kimi-Audio 的构建实践,包括模型架构、数据整理、训练方案、推理部署和评估。
Kimi-Audio是一个在音频理解、生成和对话方面表现卓越的开源音频基础模型。论文介绍了 Kimi-Audio 的构建实践,包括模型架构、数据整理、训练方案、推理部署和评估。
具体而言,我们利用 12.5Hz 音频分词器,设计了一种基于 LLM 的新型架构,以连续特征作为输入,以离散分词作为输出,并开发了一个基于流匹配的分块式流式去分词器。作者整理了一个包含超过 1300 万小时音频数据的预训练数据集,涵盖语音、声音和音乐等多种模态,并构建了用于构建高质量且多样化的训练后数据的流水线。Kimi-Audio 基于预训练的 LLM 进行初始化,并通过多个精心设计的任务,在音频和文本数据上进行持续预训练,然后进行微调以支持各种音频相关任务。
广泛的评估表明,Kimi-Audio 在一系列音频基准测试中均达到了最佳性能,包括语音识别、音频理解、音频问答和语音对话。
架构概述
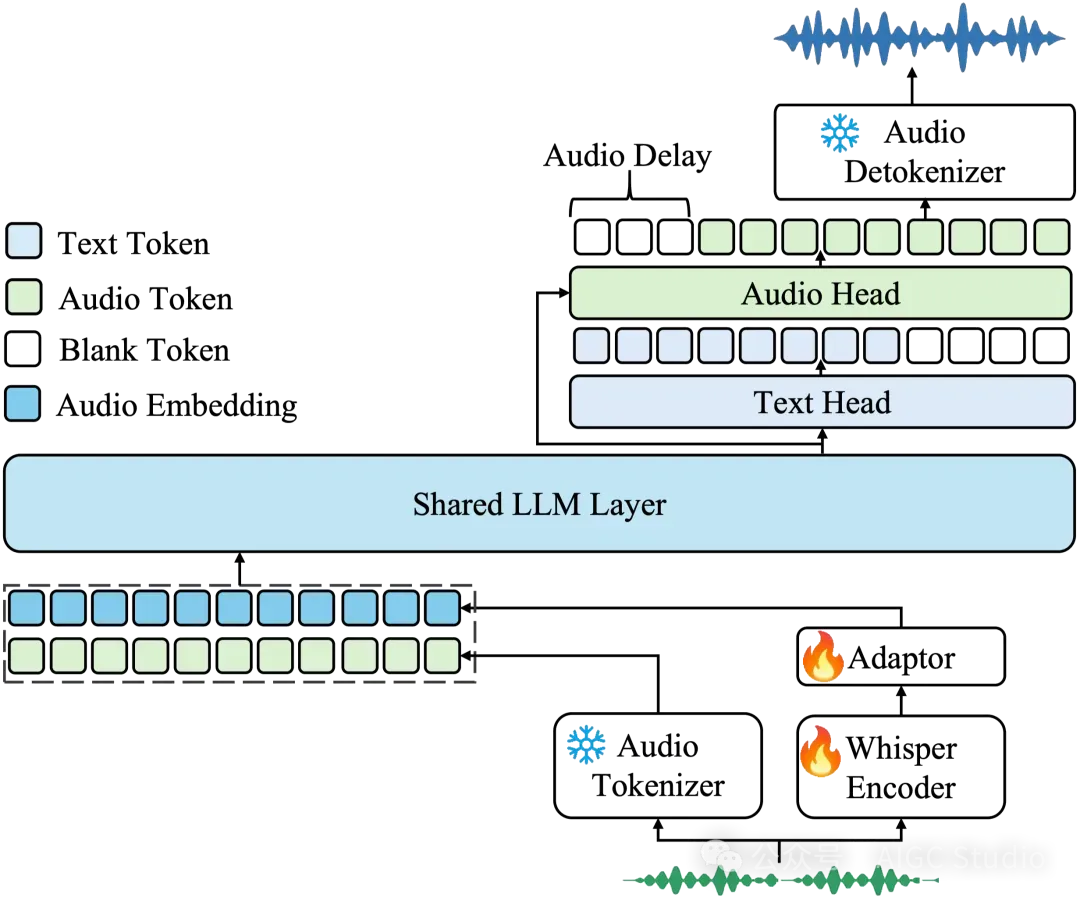 Kimi-Audio 由三个主要组件组成:
Kimi-Audio 由三个主要组件组成:
- 音频标记器:将输入音频转换为:使用矢量量化的离散语义标记(12.5Hz)。来自 Whisper 编码器的连续声学特征(下采样至 12.5Hz)。
- 音频 LLM:基于转换器的模型(由预训练的文本 LLM(如 Qwen 2.5 7B)初始化),具有处理多模态输入的共享层,然后是并行头,用于自回归生成文本标记和离散音频语义标记。
- 音频解析器:使用流匹配模型和声码器(BigVGAN)将预测的离散语义音频标记转换回高保真波形,支持分块流传输,并采用前瞻机制实现低延迟。
评估
Kimi-Audio 在广泛的音频基准测试中实现了最先进的 (SOTA) 性能。
以下是整体表现:
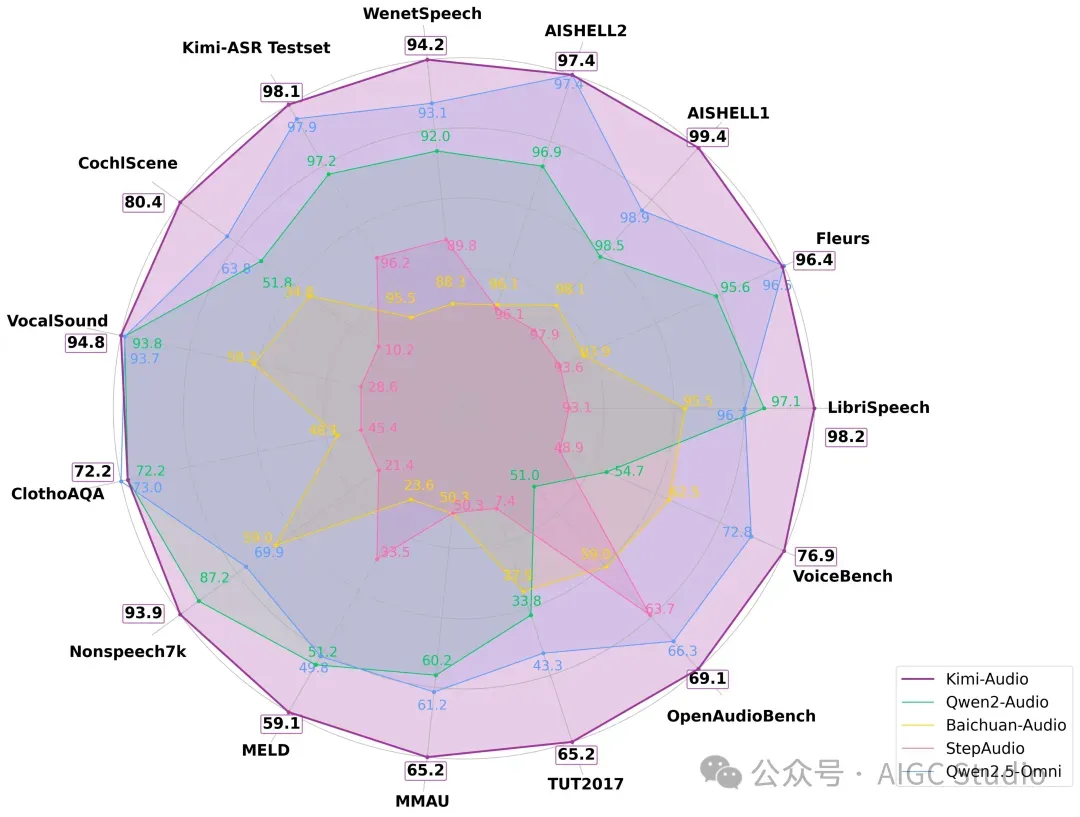 Kimi-Audio 与之前的音频语言模型(包括 Qwen2-Audio、Baichuan Audio、Step-Audio 和 Qwen2.5-Omni)在各种基准测试中的表现。
Kimi-Audio 与之前的音频语言模型(包括 Qwen2-Audio、Baichuan Audio、Step-Audio 和 Qwen2.5-Omni)在各种基准测试中的表现。
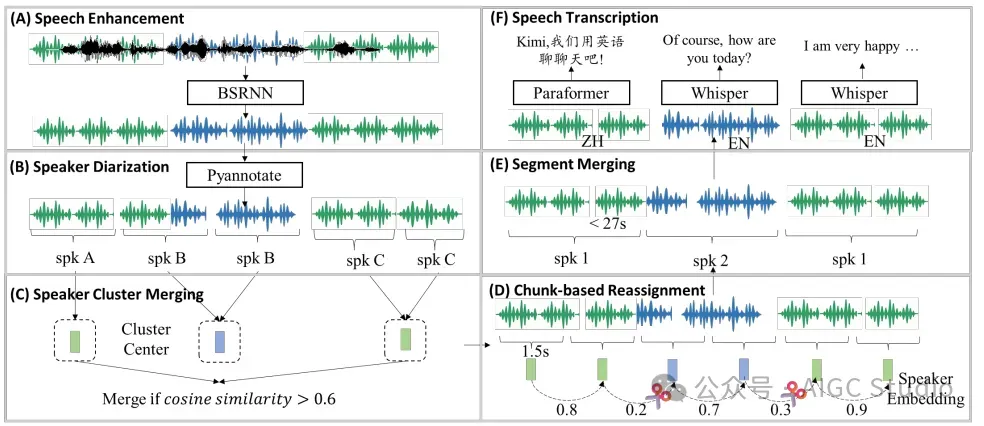
音频预训练数据的处理流程
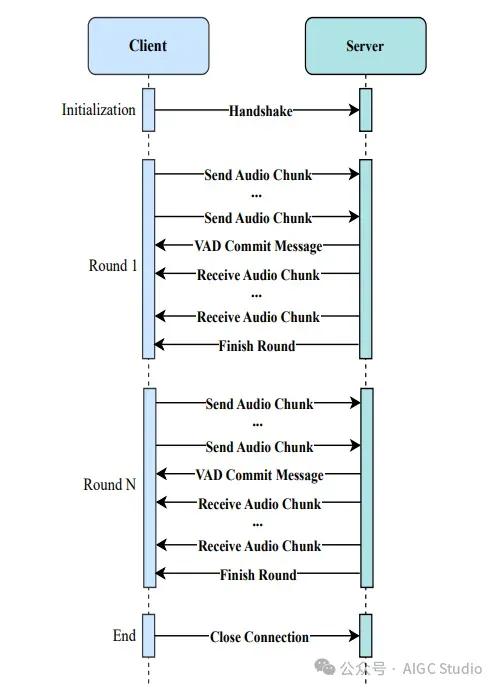
Kimi-Audio 中用于实时语音对话的客户端-服务器通信。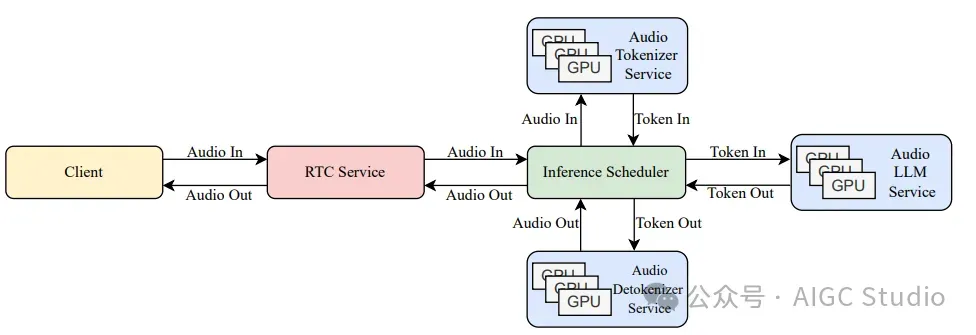 Kimi-Audio 实时语音对话生产部署流程
Kimi-Audio 实时语音对话生产部署流程


