英伟达提出「描述一切」模型 (DAM),这是一个强大的多模态大型语言模型,可以生成图像或视频中特定区域的详细描述。用户可以使用点、框、涂鸦或蒙版来指定区域,DAM 将提供这些区域的丰富且符合上下文的描述。


相关链接
- 论文:https://arxiv.org/pdf/2504.16072
- 主页:https://describe-anything.github.io
- 试用:https://huggingface.co/spaces/nvidia/describe-anything-model-demo
论文介绍
 描述任何事物:详细的本地化图像和视频字幕
描述任何事物:详细的本地化图像和视频字幕
详细本地化字幕 (DLC)
详细局部字幕 (DLC) 的任务是生成图像中特定区域的全面且情境感知的描述。与传统的图像字幕(仅粗略概括整个场景)不同,DLC 会深入挖掘用户指定区域的更精细细节。其目标不仅在于捕捉物体的名称或类别,还在于捕捉细微的属性,例如纹理、颜色模式、形状、显著部分以及任何视觉上独特的特征。 DLC 可以自然地扩展到视频,描述特定区域的外观和上下文如何随时间变化。模型必须跨帧跟踪目标,捕捉不断变化的属性、交互和细微的变化。
DLC 可以自然地扩展到视频,描述特定区域的外观和上下文如何随时间变化。模型必须跨帧跟踪目标,捕捉不断变化的属性、交互和细微的变化。

高度详细的图像和视频字幕
该方法擅长生成图像和视频中物体的详细描述。通过平衡焦点区域的清晰度和全局上下文,该模型可以突出细微的特征(例如复杂的图案或变化的纹理),这远远超出了一般图像级字幕所能提供的范围。
指令控制的字幕
用户可以引导我们的模型生成不同细节和风格的描述。无论是简短的摘要,还是冗长复杂的叙述,模型都能调整输出。这种灵活性使其适用于各种用例,从快速标记任务到深入的专家分析。

零样本区域 QA
除了描述之外,我们的模型无需额外的训练数据即可回答有关特定区域的问题。用户可以询问该区域的属性,模型会利用其对本地区域的理解,提供准确的、基于情境的答案。此功能增强了自然、交互式的用例。

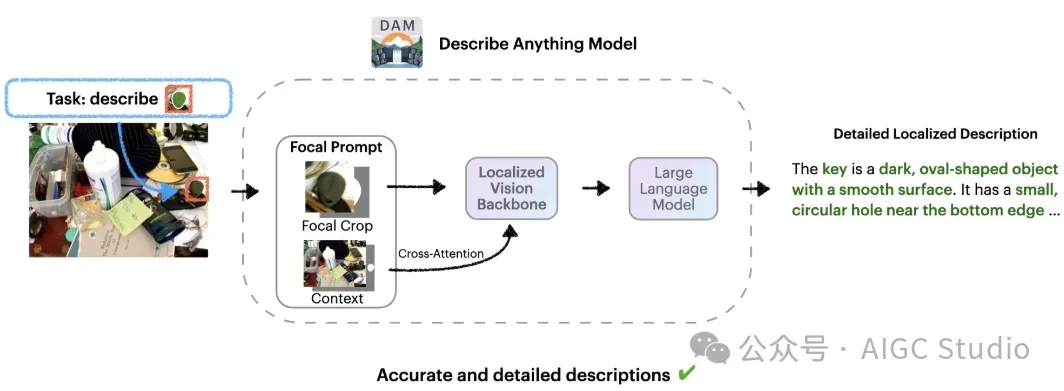
描述任何事物模型 (DAM) 的架构
架构采用“焦点提示”技术,提供完整图像和目标区域的放大视图。这种方法确保模型能够捕捉精细细节,同时保留全局背景。最终呈现的字幕细致准确,既能反映全局,又能捕捉细微之处。
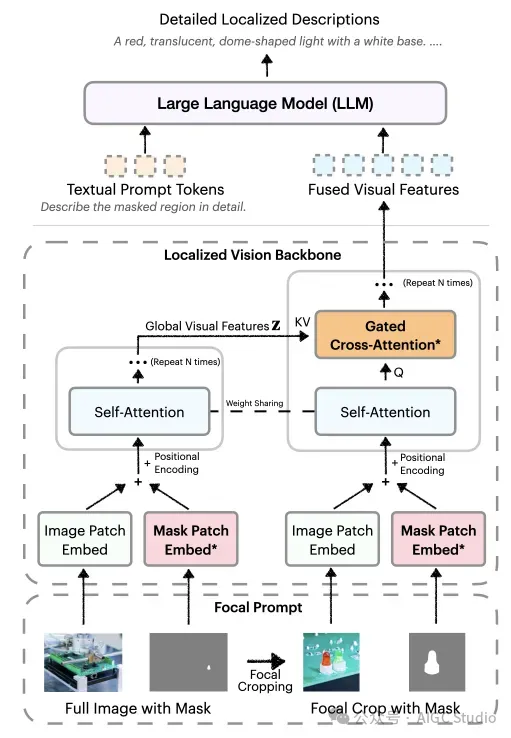
 该方法引入了一个集成全局特征和焦点特征的局部视觉主干网络。图像和掩码在空间上对齐,门控交叉注意力层将局部细节线索与全局上下文融合。新参数初始化为零,保留预先训练的能力。这种设计能够产生更丰富、更具有上下文感知能力的描述。
该方法引入了一个集成全局特征和焦点特征的局部视觉主干网络。图像和掩码在空间上对齐,门控交叉注意力层将局部细节线索与全局上下文融合。新参数初始化为零,保留预先训练的能力。这种设计能够产生更丰富、更具有上下文感知能力的描述。
用于详细本地化字幕的半监督数据管道(DLC-SDP)
由于现有数据集缺乏详细的局部描述,我们设计了一个两阶段流程。首先,我们使用可变长度语言 (VLM) 将分割数据集中的短类标签扩展为丰富的描述。其次,我们将自训练作为一种半监督学习的形式应用于未标记图像,使用我们的模型生成和优化新的标题。这种可扩展的方法无需依赖大量的人工注释即可构建大量高质量的训练数据。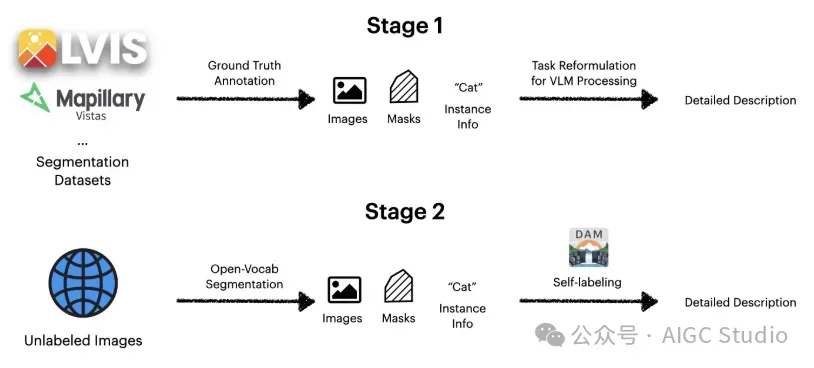
DLC-Bench:详细本地化字幕的基准
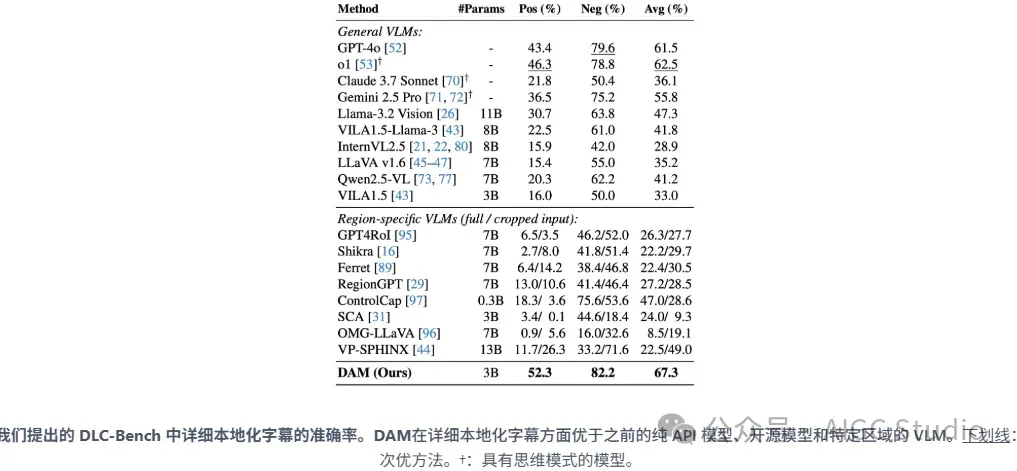
我们推出了 DLC-Bench,这是一个使用基于 LLM 的判断器来评估模型区域描述的基准测试。DLC-Bench 不再依赖简单的文本重叠,而是检查细节是否正确以及是否存在错误。这为衡量 DLC 性能提供了一个更准确、更人性化的指标。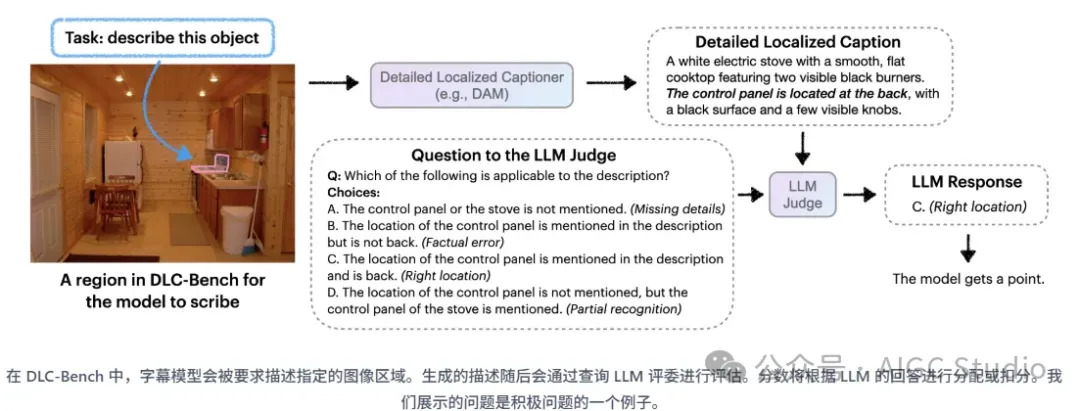
DAM、DLC-SDP 和 DLC-Bench 的优势

比较
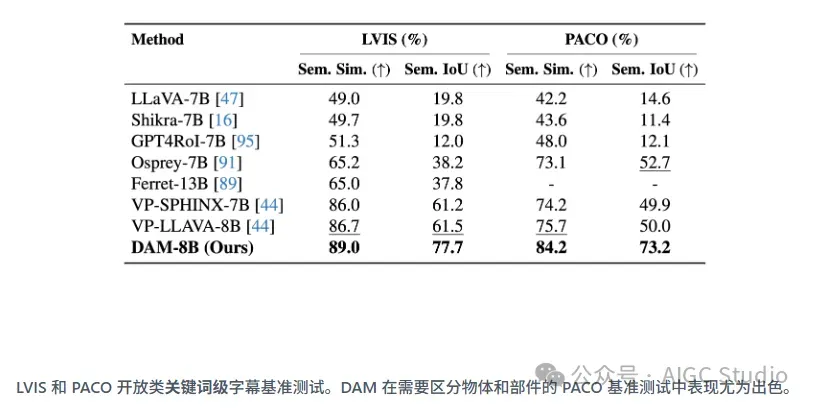
在 DLC-Bench 上,我们的模型能够生成更详细、更准确的局部描述,并减少幻觉,从而超越现有解决方案。它超越了针对一般图像级任务训练的模型以及专为局部推理设计的模型,为详细且语境丰富的字幕生成树立了新的标准。
结论
“描述任何内容”模型 (DAM)能够为图像和视频中的特定区域生成详细的描述,可用于各种应用,从数据标注到作为下游任务的中间组件。


