
大家好,我是肆〇柒。因为与合作伙伴项目的需要,最近对 RL 方面的论文关注的多了一些。这两天,我翻出一篇去年的论文来复习。这篇是来自字节跳动研究团队(ByteDance Research)的 ACL 2024 论文《ReFT: Reasoning with Reinforced Fine-Tuning》。这篇论文发表在《Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)》上。
在人工智能领域,提升大语言模型(LLM)的数学推理能力一直是研究热点。然而,现有的监督微调(SFT)方法结合思维链(CoT)注释在泛化能力上存在明显瓶颈。为解决这一问题,字节跳动研究团队提出了一种名为 ReFT(Reasoning with Reinforced Fine-Tuning)的创新方法,通过强化学习机制,使模型能够探索多种推理路径,从而显著提升其在数学问题求解任务中的推理能力和泛化性能。
传统 SFT 方法仅依赖单一正确的推理路径进行训练,导致模型在面对多样化问题时泛化能力不足。例如,在 GSM8K 数据集上,基于 SFT 的模型在某些复杂问题上表现不佳,准确率难以突破瓶颈。这种局限性促使研究者探索新的微调范式,以充分挖掘模型的推理潜力。
下图展示了 GSM8K 数据集中的一道示例题目及其 CoT 和答案,清晰地说明了监督微调和强化微调的对比。通过这种对比,我们可以更好地理解 ReFT 如何在训练过程中利用多种推理路径来提升模型的性能。
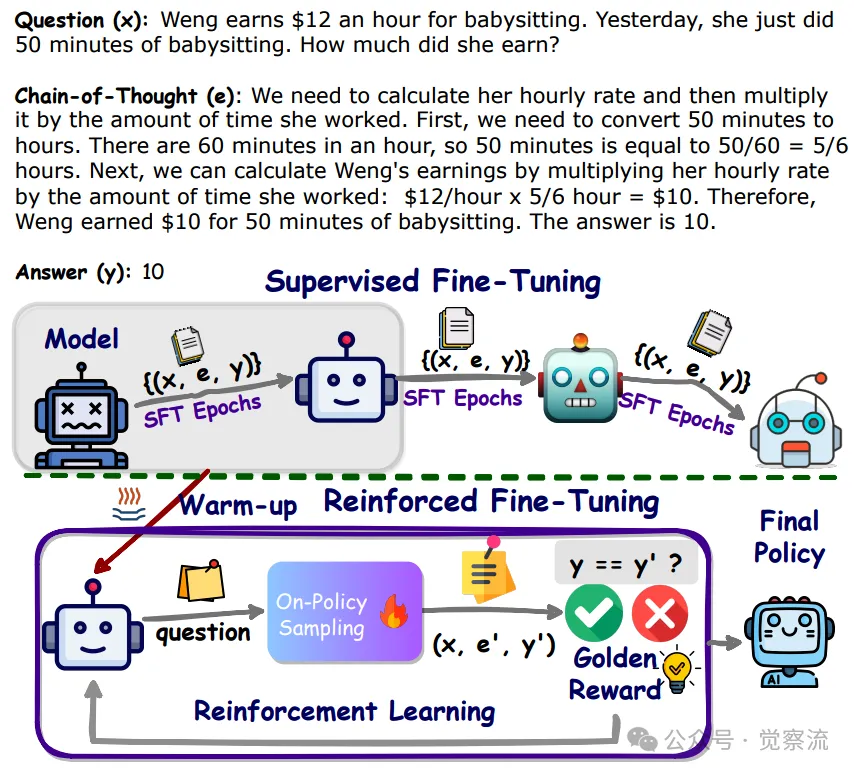
GSM8K 数据集示例题目及其 CoT 和答案
数学问题解决中,单一正确推理路径的依赖,成为模型泛化的主要障碍。实际上,许多数学问题存在多种有效的推理路径,模型若能学习这些路径,将大幅提升其泛化能力。ReFT 方法被提出,它突破了传统微调范式的限制,通过强化学习机制,使模型能够探索多种推理路径,从而增强其推理深度与准确性。
ReFT 方法概述
ReFT 的核心在于两阶段训练框架。
首先,通过监督微调(SFT)对模型进行初始化,使其具备基本的数学问题求解能力。接着,利用强化学习(特别是 PPO 算法)对模型进行进一步优化。在强化学习阶段,模型能够自动采样多种推理路径,并基于真实答案获得奖励信号,从而不断调整策略,提升推理能力。相比传统 SFT,ReFT 预期在泛化能力上实现显著提升,同时优化模型的推理深度与准确性。
下图对比了 SFT 和 ReFT 在存在 CoT 替代方案时的表现,直观地展示了 ReFT 如何通过探索多种推理路径来提升模型的性能。
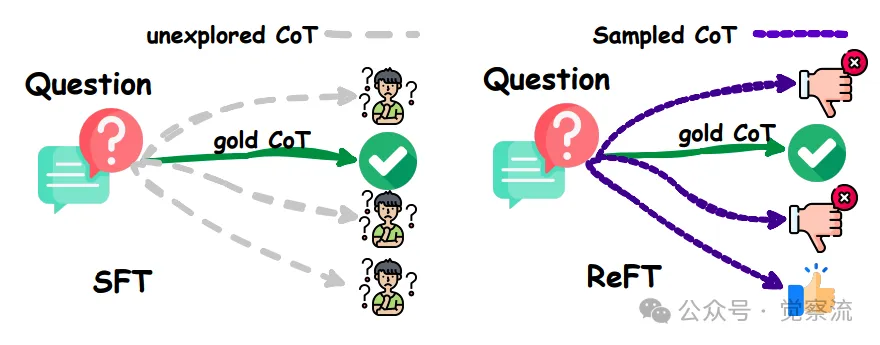
SFT 和 ReFT 在 CoT 替代方案上的对比
ReFT 方法论
监督微调(SFT)准备阶段
在 SFT 阶段,数据集的选择与标注质量至关重要。GSM8K、SVAMP、MathQA 数据集因其题目类型的多样性和标注的规范性,成为理想的训练数据源。以 GSM8K 数据集为例,其包含 8K 道数学应用题,每道题都配有详细的思维链(CoT)注释,涵盖从简单算术到复杂代数的多种类型,为模型训练提供了丰富的样本。
模型预训练基础的选择同样关键。研究团队将 CodeLLAMA 和 Galactica 作为基础模型,其预训练特性与数学推理任务高度契合。CodeLLAMA 在代码生成任务上的优势,使其能够更好地理解数学问题中的逻辑结构;而 Galactica 在科学文献处理上的专长,则有助于模型对数学问题中专业术语的理解。SFT 初始化策略,如学习率的设置、预训练权重的加载方式等,对后续强化学习阶段的学习效果有着深远影响。
SFT 的训练目标函数基于交叉熵损失,通过最小化模型预测与真实 CoT 标注之间的差异,使模型逐步掌握数学问题的基本解题思路。训练过程中的收敛性判断标准,如连续多个 epoch 验证损失不再下降,则表明模型在当前数据集上已达到较好的拟合效果,可进入强化学习阶段。
ReFT 强化学习阶段
ReFT 强化学习阶段采用 PPO(Proximal Policy Optimization)算法,这是一种在策略梯度方法基础上改进的强化学习算法,具有稳定性和高效性优势。PPO 算法通过限制策略更新的幅度,避免了策略梯度方法中常见的训练不稳定问题。在 ReFT 的应用场景下,PPO 算法的参数调整需根据数学问题的特点进行优化,例如学习率的设置、折扣因子 γ 的选择等。
PPO 算法的具体运算过程如下:
1. 策略网络构建:策略网络采用多层感知机(MLP)结构,输入为问题状态,输出为动作概率分布。例如,对于一个数学问题求解任务,策略网络的输入可以是问题的文本编码,输出则是下一步推理动作的概率分布。
2. 价值函数估计:价值函数用于估计当前状态下的期望累计奖励。通过训练一个价值网络,使用均方误差损失函数来拟合真实价值函数。价值网络的输入与策略网络相同,输出为一个标量值,表示当前状态的价值。
3. 优势函数计算:优势函数衡量在当前状态下采取特定动作相对于平均策略的优劣。计算公式为:

4. 策略更新:根据采样的轨迹计算优势函数估计值,使用 PPO 的裁剪目标函数更新策略网络参数。裁剪目标函数为:
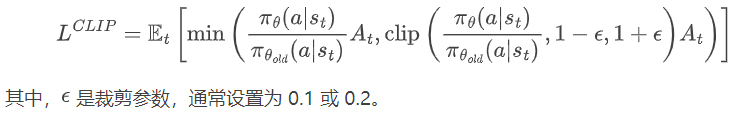
从单一问题中采样多种推理路径是 ReFT 的关键创新之一。基于策略梯度的路径探索机制,模型能够在给定问题时生成多种可能的推理路径。通过多样性采样技术,如温度调节(temperature scaling)、核采样(top-k sampling)等,模型能够生成具有多样性的路径集合。随后,利用筛选机制,如基于答案正确性的过滤、基于路径相似度的去重等,保留有效的推理路径,从而丰富模型的学习样本。
奖励信号的设计直接关系到模型的学习效果。ReFT 的奖励函数以真实答案为核心,当模型生成的推理路径得出正确答案时,给予正向奖励;否则,给予惩罚。部分奖励策略在稀疏反馈环境中发挥着重要作用,例如在数学问题的中间步骤给予一定奖励,引导模型逐步接近正确答案,从而缓解了强化学习中常见的稀疏奖励问题。
下图展示了 MathQAMCQ 数据集中的一个示例预测,展示了奖励欺骗现象。当模型生成错误的推理路径却得出正确答案时,会获得不当奖励,误导模型的学习方向。这种现象在多选题场景下尤为突出,严重时可能导致模型性能下降。ReFT 通过合理设计奖励函数和采样策略,在一定程度上缓解了奖励欺骗问题,确保了训练过程的可靠性。

MathQAMCQ 数据集示例预测,揭示奖励欺骗现象
ReFT 关键机制深度解析
线上强化学习与自监督学习在 ReFT 中相辅相成。线上强化学习使模型能够实时根据环境反馈调整策略,而自监督学习则利用模型自身生成的数据进行进一步学习,两种范式的协同作用显著提升了模型的泛化能力。例如,在处理复杂的代数问题时,模型通过线上强化学习不断尝试不同的解题思路,同时借助自监督学习对生成的推理路径进行自我评估与优化,从而逐步掌握问题的解题规律。
部分奖励策略与 KL 散度约束的平衡机制是 ReFT 的另一关键。部分奖励在不同推理阶段的合理应用,如在问题初期给予较高的探索奖励,随着推理深入逐步增加开发奖励,能够引导模型在探索与利用之间取得平衡。KL 散度约束则通过限制新旧策略之间的差异,防止模型在强化学习过程中偏离初始策略过远,从而保证了训练的稳定性。这种平衡机制的动态调整,使模型能够在复杂多变的数学问题中保持稳定的性能提升。
ReFT 支持自然语言 CoT 与程序基 CoT 的双重处理框架。自然语言 CoT 以自然语言形式描述推理过程,易于人类理解和解释;而程序基 CoT 则以编程语言形式表达,具有更高的精确性和可执行性。ReFT 的融合处理框架能够充分利用两种 CoT 形式的优点,增强模型在不同场景下的适用性与鲁棒性。例如,在处理涉及逻辑判断与循环操作的数学问题时,程序基 CoT 能够提供更清晰的执行步骤,而自然语言 CoT 则有助于模型理解问题背景与上下文信息。
与离线自训练和在线自训练方法相比,ReFT 具有显著优势。离线自训练受限于初始采样数据的质量与多样性,难以动态调整训练策略;在线自训练则存在反馈延迟问题,影响模型的实时学习效果。ReFT 的即时反馈与动态调整机制使其能够在训练过程中快速适应问题的复杂性,从而实现更高效的性能提升。
SFT 方法在数学问题求解中的局限性主要体现在其对单一正确推理路径的依赖。例如,当面对具有多种解题方法的数学问题时,SFT 模型往往只能学习到其中一种方法,导致其在面对其他解题思路时泛化能力不足。ReFT 通过强化学习机制,使模型能够探索多种推理路径。例如,在 GSM8K 数据集上,ReFT 能够通过采样不同的推理路径,逐步学习到多种解题方法,从而克服 SFT 方法的局限性,提升模型的泛化能力和推理深度。
实验设计与结果评估
实验环境与配置
实验基于 GSM8K、SVAMP 和 MathQA 三大数据集展开,这些数据集在数学问题求解研究中具有代表性,涵盖了从基础算术到高级代数的广泛问题类型。例如,SVAMP 数据集包含 3,000 多道经过严格筛选的数学题,题目难度适中且具有良好的代表性。下表提供了训练集和测试集的统计信息,展示了数据集的规模和特性。
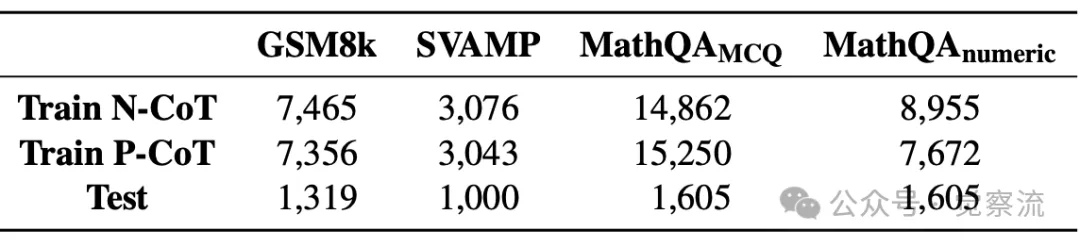
训练集和测试集的统计信息
基础模型选择 CodeLLAMA 和 Galactica,主要考虑其架构特点与数学推理任务的适配性。CodeLLAMA 的 decoder-only 架构使其在生成任务上具有高效性,而 Galactica 的 large context window 特性能够处理较长的数学问题描述。训练硬件环境采用 8 块 A100-80GB GPU,配合 DeepSpeed Zero stage 2 和 HuggingFace Accelerate,确保了训练过程的高效性与稳定性。
在实验中,ReFT 方法与多种基线方法进行了对比,包括 SFT、离线自训练和在线自训练。SFT 作为传统方法,直接利用标注数据进行监督训练;离线自训练通过初始模型生成额外样本进行训练;在线自训练则在训练过程中动态生成样本。为确保公平比较,所有基线方法均采用相同的超参数调整策略,如学习率、批次大小等,并通过交叉验证评估性能稳定性。
实验结果呈现与分析
下表展示了 ReFT 和基线方法在所有数据集上的价值准确率。在 GSM8K 数据集上,ReFT 的自然语言 CoT 准确率达到 75.28%,程序基 CoT 准确率更是高达 81.2%,相比 SFT 方法分别提升了近 12 个百分点和 17 个百分点。在 SVAMP 数据集上,ReFT 的准确率提升了约 10 个百分点。这些结果表明 ReFT 在不同数据集上均能显著超越基线方法,展现出卓越的推理性能。
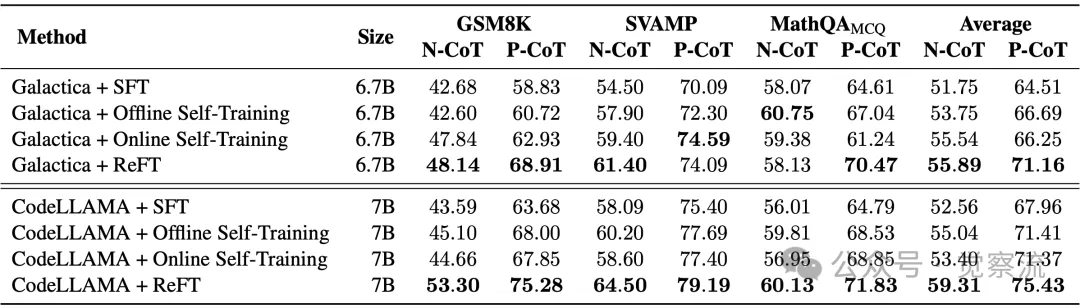
ReFT 和基线方法在所有数据集上的价值准确率
下表针对 MathQAnumeric 基准测试,进一步验证了 ReFT 的鲁棒性。ReFT 在该变种数据集上的准确率达到 78.0%,相比 SFT 提升了近 15 个百分点。这表明 ReFT 在处理数值型答案的数学问题时,能够有效避免奖励欺骗问题,保持稳定的性能表现。
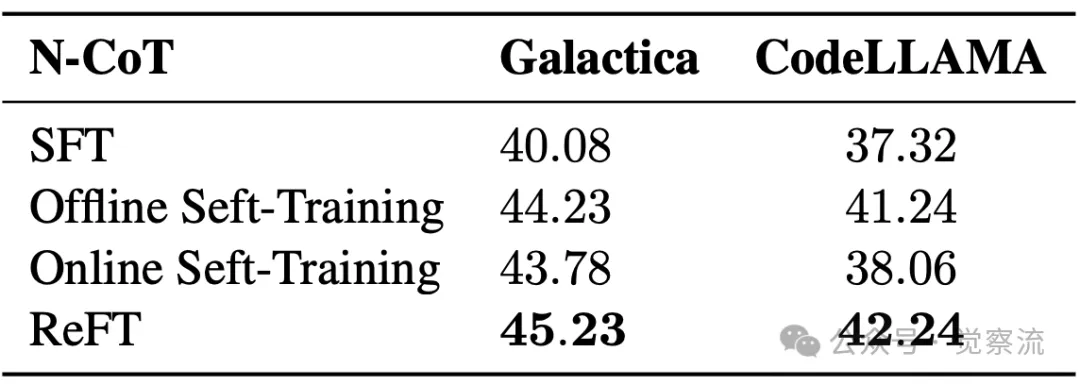
ReFT 和基线方法在 MathQAnumeric 基准测试上的价值准确率
下表则凸显了多数投票与重排序技术对 ReFT 性能的显著增益效果。结合多数投票策略后,ReFT 在 GSM8K 数据集上的准确率提升了 8.6 个百分点;而在重排序技术的助力下,准确率提升了超过 3 个百分点。这些结果充分证明了 ReFT 与这些技术的兼容性,能够通过集成方法进一步提升模型的性能。
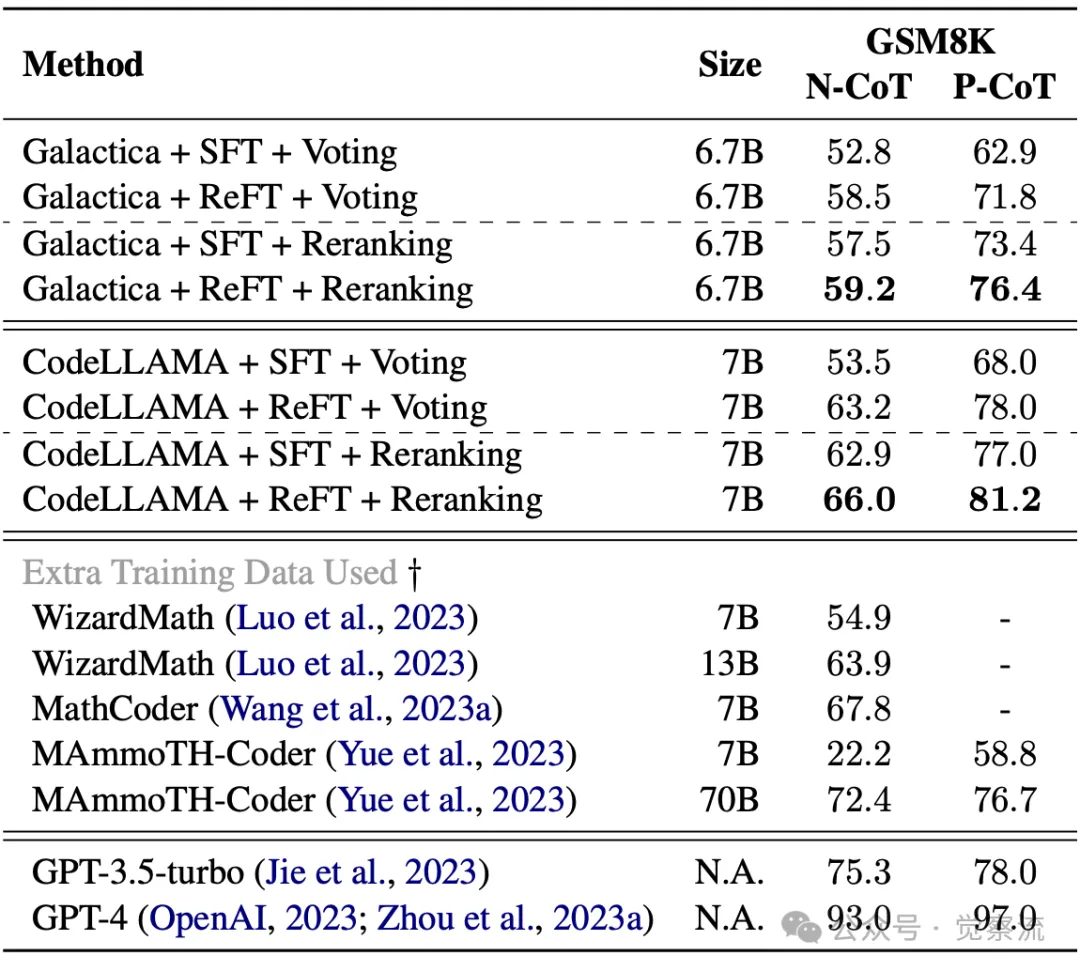
多数投票和重排序技术对 SFT 和 ReFT 在 GSM8K 数据集上的解题准确率影响
下图展示了 ReFT 在 GSM8K P-CoT 数据集上的训练奖励、评估准确率和 KL 散度随训练周期的变化情况。从图中可以看出,随着训练的进行,ReFT 的评估准确率稳步提升,同时 KL 散度逐渐趋于稳定,反映了 ReFT 在强化学习阶段的训练动态过程和稳定性。
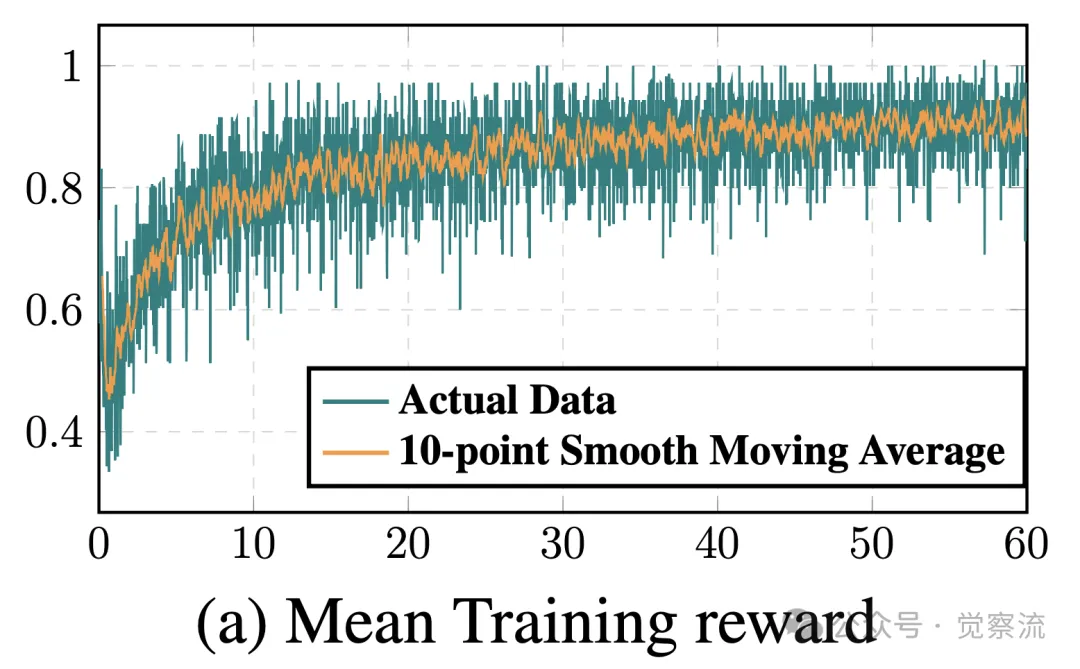
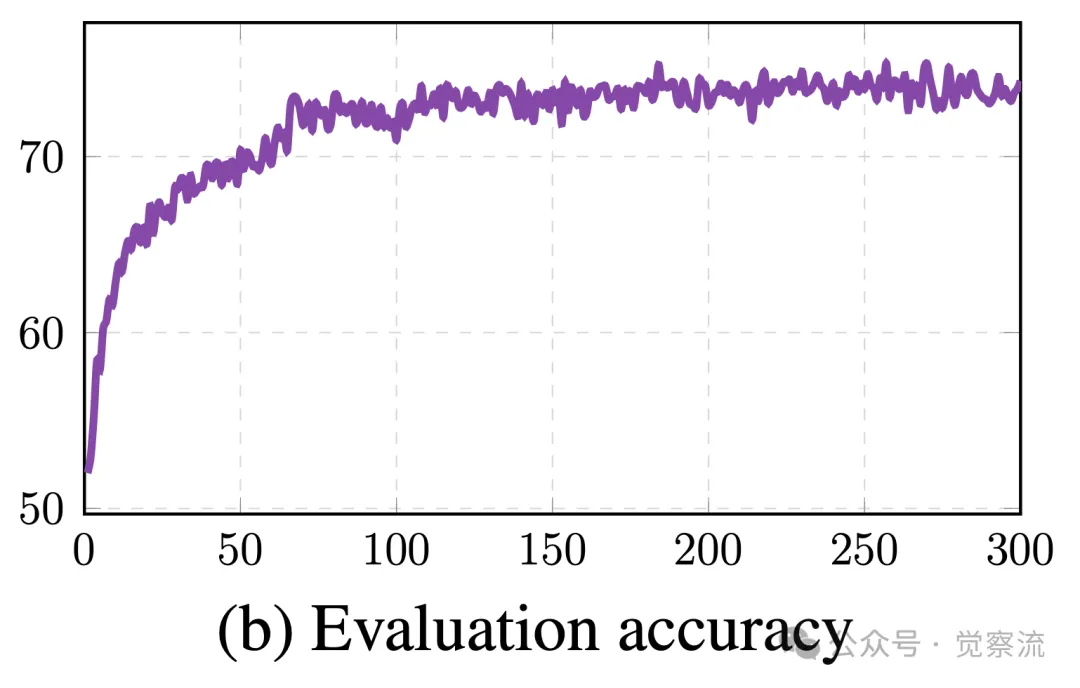
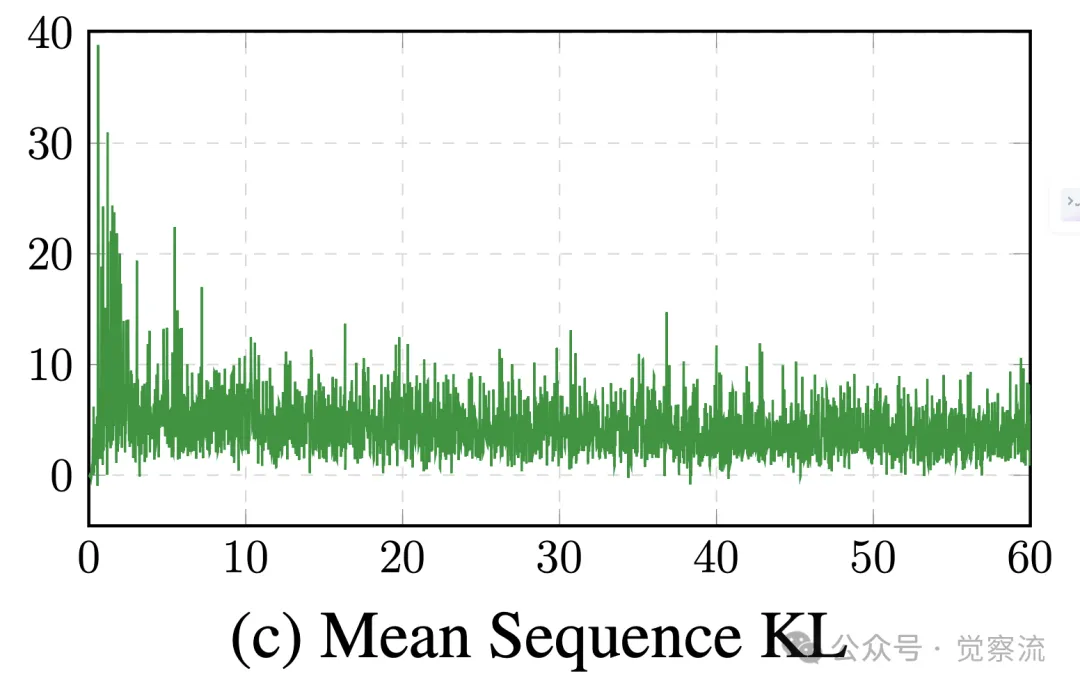
ReFT 在 GSM8K P-CoT 数据集上的训练奖励、评估准确率和 KL 散度变化情况
下表的消融研究结果进一步量化了 ReFT 各个关键组件的贡献。例如,当移除部分奖励策略时,ReFT 在 GSM8K P-CoT 任务上的准确率从 81.2% 下降至 80.2%;而将 KL 系数 β 设置为 0 时,模型性能出现严重退化,准确率几乎降为 0。这些结果凸显了部分奖励策略和 KL 散度约束在维持 ReFT 稳定性和性能方面的重要作用。

消融研究结果
下图比较了 SFT 和 ReFT 在不同预热 epoch 数下的准确率。结果显示,ReFT 在经过适当的预热步骤后,性能显著优于 SFT,尤其是在预热 epoch 为 3 和 5 时,ReFT 的准确率提升最为明显。
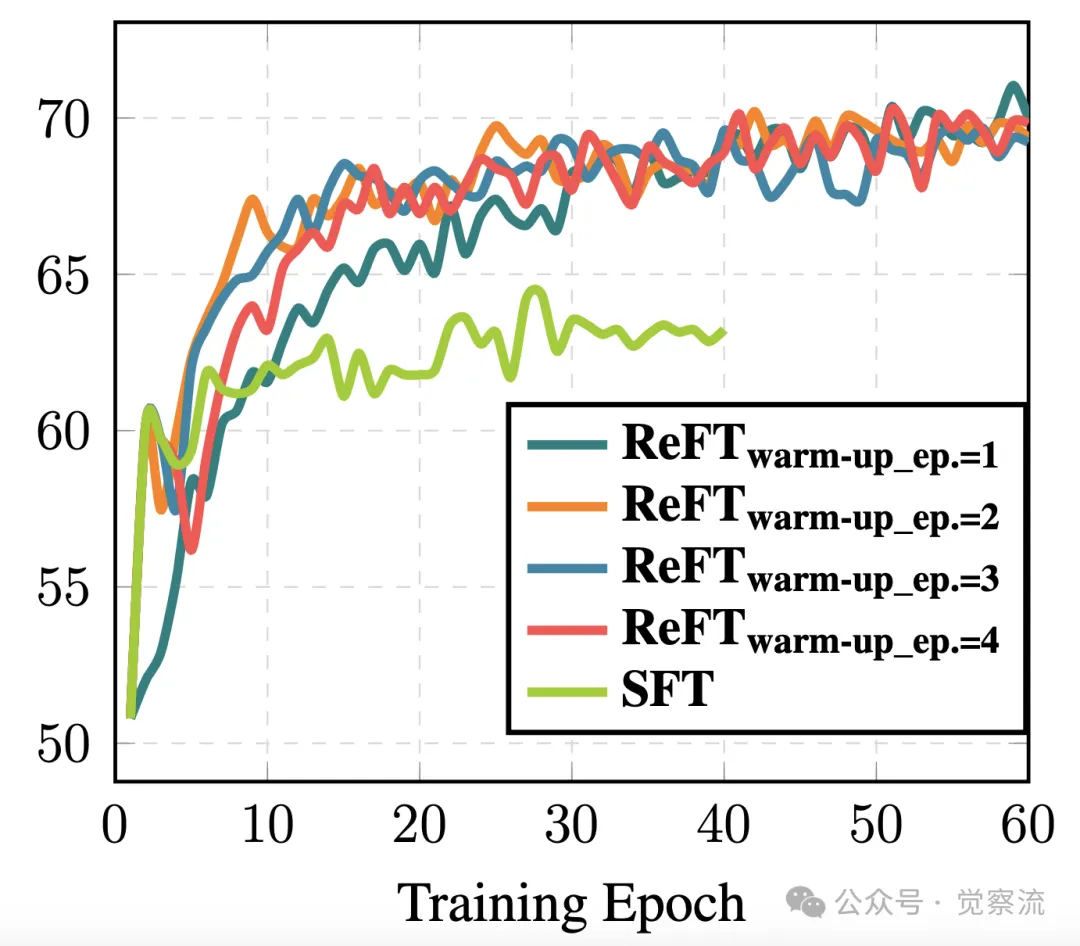
不同预热 epoch 数下 SFT 和 ReFT 的准确率对比
下图展示了 SFT 和 ReFT 模型在 GSM8K 数据集上同一问题的不同训练周期的 P-CoT 响应。绿色框架表示正确的响应,红色框架表示错误的响应。从图中可以看出,ReFT 在训练过程中逐渐收敛到正确的解题路径,而 SFT 则在多个训练周期中表现不稳定。
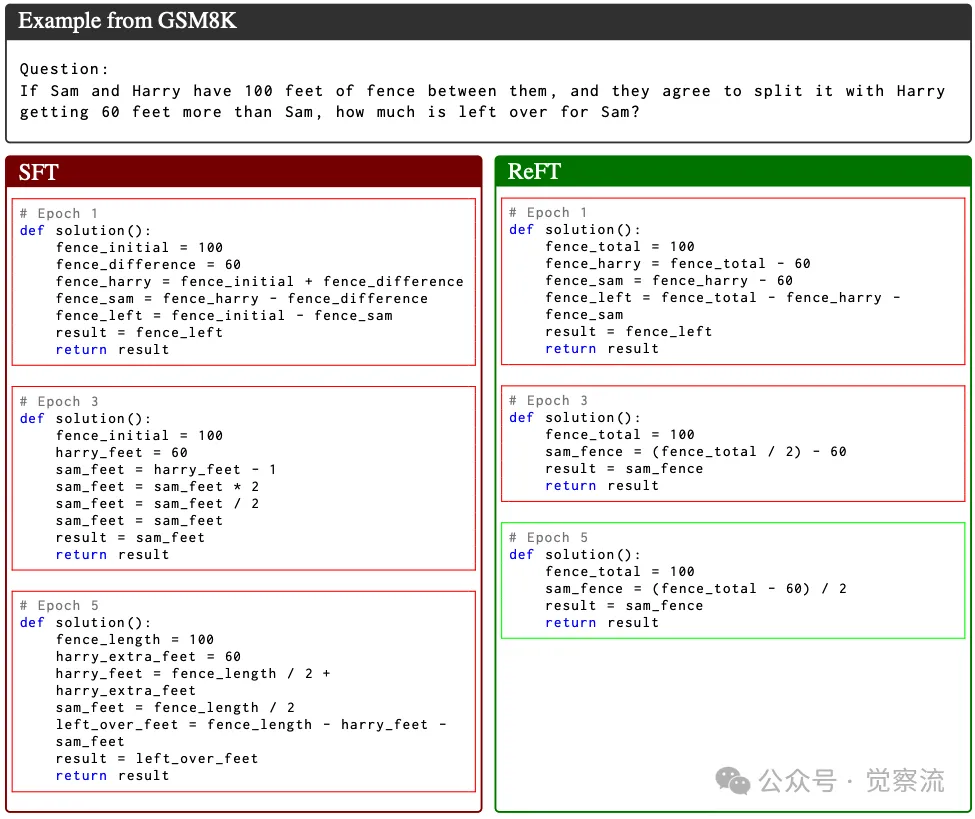
GSM8K 数据集上同一问题在不同训练周期的 P-CoT 响应对比
结果分析与洞察
ReFT 在不同数据集上的性能提升呈现出一些共性规律。例如,在涉及多步推理的复杂问题上,ReFT 的性能提升更为显著,这归因于其能够探索多种推理路径,从而更好地应对问题的复杂性。同时,数据集的特性也对性能提升产生影响。在 GSM8K 数据集上,由于问题类型的多样性,ReFT 能够充分利用其路径探索能力,实现显著的性能提升。而在 SVAMP 数据集上,由于部分问题存在固定的解题模板,ReFT 的提升幅度相对较小,但仍优于基线方法。
小模型实验进一步验证了 ReFT 的泛化能力。即使在参数量较少的模型上,ReFT 仍能取得优于 SFT 的结果。例如,在 Galactica-125M 模型上,ReFT 在 GSM8K 数据集上的准确率相比 SFT 提升了近 6 个百分点。这表明 ReFT 方法具有良好的普适性,能够适应不同规模的模型。
总体而言,实验结果充分证明了 ReFT 方法在提升大语言模型数学推理能力方面的显著优势,为未来推理任务的研究和实践提供了新的方向和思路。
实践指南与代码实现
环境搭建步骤
搭建 ReFT 的运行环境,首先需安装依赖库,包括 transformers、torch、accelerate 等。各库的版本需满足兼容性要求,例如 transformers 版本应与基础模型的实现相匹配。以下是具体的安装命令:
复制pip install transformers==4.28.0 torch==1.13.1 accelerate==0.16.0
数据预处理流程涉及将原始数据集转换为模型可接受的格式,如将 GSM8K 数据集中的问题、CoT 和答案整理为 JSON 格式。数据格式规范对模型训练至关重要,不正确的格式可能导致训练过程中的错误。
SFT 实现详解
train_sft_model.py 脚本是 SFT 的核心实现。其关键参数包括学习率、批次大小、训练 epoch 数等。例如,学习率设置为 1e-5,批次大小为 48,训练 epoch 数为 40。这些参数的选择基于实验经验和数据集特性,对 SFT 的训练效果有着直接的影响。
在训练过程中,需监控损失变化和验证集准确率等关键指标。可以通过 TensorBoard 进行可视化,具体命令如下:
复制tensorboard --logdir=./logs
当验证集准确率 plateau 时,可以尝试调整学习率或增加正则化。例如,将学习率降低一个数量级:
复制optimizer = AdamW(model.parameters(), lr=1e-6)
ReFT 代码实战
train_rl_reft.py 脚本实现了 ReFT 的强化学习流程。以下是 PPO 算法的关键代码片段:
复制import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
classPPO:
def__init__(self, model, lr, gamma, epsilon, device):
self.model = model
self.optimizer = optim.Adam(model.parameters(), lr=lr)
self.gamma = gamma
self.epsilon = epsilon
self.device = device
defcompute_advantages(self, rewards, values):
advantages = []
gae = 0
for t inreversed(range(len(rewards))):
delta = rewards[t] + self.gamma * values[t+1] - values[t]
gae = delta + self.gamma * gae
advantages.insert(0, gae)
return advantages
defupdate(self, states, actions, rewards, log_probs_old):
states = torch.tensor(states, dtype=torch.float32).to(self.device)
actions = torch.tensor(actions, dtype=torch.int64).to(self.device)
rewards = torch.tensor(rewards, dtype=torch.float32).to(self.device)
log_probs_old = torch.tensor(log_probs_old, dtype=torch.float32).to(self.device)
# 计算价值函数
values = self.model.value(states)
# 计算优势函数
advantages = self.compute_advantages(rewards, values)
advantages = torch.tensor(advantages, dtype=torch.float32).to(self.device)
# 计算新策略的概率分布
logits = self.model.policy(states)
dist = Categorical(logits=logits)
log_probs_new = dist.log_prob(actions)
# 计算 PPO 裁剪目标函数
ratio = torch.exp(log_probs_new - log_probs_old)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1.0 - self.epsilon, 1.0 + self.epsilon) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 计算价值函数损失
value_loss = nn.MSELoss()(values, rewards)
# 更新模型
self.optimizer.zero_grad()
policy_loss.backward()
value_loss.backward()
self.optimizer.step()在强化学习训练过程中,调试技巧至关重要。例如,通过打印中间策略分布、奖励值等信息,诊断采样多样性不足、奖励稀疏等问题,并据此调整采样温度、奖励函数参数等。常用的调试工具有 TensorBoard(用于可视化训练指标)、PyTorch 的断点调试功能等。
采样与评估实践
sampling.py 提供了多种采样策略配置,如温度采样、核采样、束搜索等。以下是一个温度采样的实现示例:
复制def temperature_sampling(logits, temperature):
logits = logits / temperature
probs = torch.softmax(logits, dim=-1)
return probs不同采样策略适用于不同场景,例如,在探索阶段可采用较高的温度值以增加采样多样性;而在开发阶段则可降低温度值以聚焦于高概率路径。采样参数的调整对结果多样性有显著影响,较高的温度值会产生更多样化的路径,但也可能引入更多噪声。
重排序模型的训练基于生成的多个 CoT 样本,通过训练二分类器判断样本的正确性,从而实现对 CoT 的重排序。模型集成策略,如将多个重排序模型的预测结果进行加权平均,能够进一步提升最终性能。例如,在 GSM8K 数据集上,结合重排序模型后,ReFT 的准确率提升了超过 3 个百分点。
性能优化
为提升训练效率,可采用多种工程实践。例如,利用混合精度训练(mixed precision training)减少内存占用并加速计算;采用梯度累积技术,在有限 GPU 内存下模拟大批次训练效果;优化数据加载流程,减少 I/O 瓶颈等。以下是一个混合精度训练的实现示例:
复制scaler = torch.cuda.amp.GradScaler()
for epoch in range(num_epochs):
for batch in dataloader:
with torch.cuda.amp.autocast():
outputs = model(batch)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()奖励欺骗问题的缓解方案包括设计更精细的奖励函数,如根据中间步骤的正确性给予部分奖励;引入专家示范数据,在训练初期引导模型学习正确的推理路径;实时监控训练过程中的奖励分布,及时发现并纠正异常的奖励模式。
总结
ReFT 方法在数学推理任务上取得了显著的性能提升。在 GSM8K 数据集上,相比 SFT 方法,ReFT 的自然语言 CoT 准确率提升了 12 个百分点,程序基 CoT 准确率提升了 17 个百分点;在 SVAMP 数据集上,准确率提升了 10 个百分点。这些量化评估结果充分证明了 ReFT 对模型推理能力边界的扩展作用,使其能够应对更复杂的数学问题。
ReFT 对 LLM 微调范式的创新拓展价值不容忽视。它为现有微调技术体系引入了强化学习机制,丰富了模型的学习方式。这一创新不仅提升了模型在数学推理任务上的性能,还为未来微调方法的研究提供了新的思路与方向,推动了微调技术的进一步发展。
局限性分析
尽管 ReFT 取得了显著成果,但在训练效率方面仍存在瓶颈。强化学习阶段的训练收敛速度较慢,尤其是在处理大规模数据集时,训练时间成倍增长。这主要归因于强化学习的试错特性,模型需通过大量采样与反馈逐步优化策略。潜在的解决方案包括采用更高效的强化学习算法,如基于模型的强化学习(Model-Based RL),通过学习环境模型减少采样需求;优化采样策略,提高采样效率,如采用优先经验回放(Prioritized Experience Replay)技术,聚焦于信息量大的样本。
奖励欺骗问题是 ReFT 面临的另一挑战。其深层成因在于奖励信号的不完全性,当模型生成的推理路径得出正确答案但过程错误时,仍可能获得奖励,误导模型学习方向。应对思路包括设计更全面的奖励函数,综合考虑路径的中间结果、逻辑合理性等多维度信息;引入辅助监督信号,如基于中间步骤正确性的奖励,引导模型学习正确的推理过程;在训练过程中增加人类反馈环节,及时纠正模型的错误推理模式。
未来方向
我们在未来的探索中,可以探索将离线强化学习技术与 ReFT 方法进行整合。离线强化学习技术利用预先收集的数据进行训练,避免了在线强化学习中与环境交互的高成本和高风险。然而,离线强化学习也面临着数据分布偏移、策略退化等挑战。通过将离线强化学习的优势与 ReFT 的在线探索能力相结合,有望开发出更加高效、稳定的强化学习方法。
此外,开发过程导向的奖励模型也是一个重要的研究方向。与传统的基于最终结果的奖励模型不同,过程导向的奖励模型更加关注推理过程的质量和合理性。例如,可以通过对推理路径的中间步骤进行评估,给予相应的奖励信号,从而引导模型生成更高质量的推理路径。这需要设计更加精细的奖励模型结构和训练方法,同时也对数据标注和特征提取提出了更高的要求。
探索 ReFT 在其他推理任务领域的迁移应用前景也具有重要意义。例如,在逻辑推理、文本蕴含、知识问答等领域,ReFT 的强化微调思路和方法可能同样能够发挥重要作用。通过针对这些任务的特点和需求,对 ReFT 方法进行适当的改造和优化,有望进一步提升模型在这些领域的推理能力和性能。
记得当时我读完这篇论文,我深感 ReFT 方法为大语言模型的推理能力提升开辟了全新的路径。通过强化学习机制,ReFT 使模型能够摆脱对单一正确推理路径的依赖,大胆探索多样化的解题思路。这种创新的微调范式不仅显著提升了模型在数学问题求解任务上的性能,还为未来微调技术的发展提供了宝贵的借鉴,要知道高效微调对 Agent 有多么重要!在去年年底,OpenAI 就推出了相似的 RFT 方法,并于今年 5 月初,RFT 初步落地。感慨,AI 行业太快了!
总体而言,ReFT 不仅是一项技术进步,更是对大语言模型推理能力边界的一次勇敢探索。它让我看到了强化学习在提升模型智能水平方面的巨大潜力,也让我对 AI 的未来发展充满期待。


