从数学竞赛、编程到自然语言处理,通过大规模的强化学习的模型正不断提升其推理能力。但传统的Transformer架构由于其注意力机制的二次计算复杂度,在处理长文本和复杂推理任务时面临着效率瓶颈。
尽管有研究提出了多种改进方法,如稀疏注意力、线性注意力等,但这些方法在大规模推理模型中的应用效果尚未得到充分验证,大多数领先的模型仍然依赖于传统的注意力设计。
所以,MiniMax开源了基于闪电注意力机制的专家混合模型Minimax。

开源地址:https://github.com/MiniMax-AI/MiniMax-M1
在架构方面,MiniMax-M1总参数为4560亿,459亿参数处于激活状态,包含32个专家。其注意力设计采用混合模式,每七个配备闪电注意力机制的Transnormer块后跟随一个带有Softmax注意力的Transformer块。
这种设计从理论上支持推理长度高效扩展至数十万token,例如,在生成长度为10万token时,相比DeepSeek R1仅消耗25%的FLOPs,显著降低了计算成本。同时,模型原生支持100万token的上下文长度,是DeepSeek R1的8倍,远超当前所有开源权重的大型推理模型,为长文本处理和深度推理提供了基础。
创新模块方面,MiniMax-M1的核心突破体现在注意力机制和强化学习算法的优化。闪电注意力机制作为线性注意力的一种I/O感知实现,通过减少传统softmax注意力的二次计算复杂度,实现了测试时计算的高效扩展。
该机制不仅在推理阶段提升效率,还为强化学习训练提供了天然优势,配合混合MoE架构,使得模型在处理长序列时的计算量增长更接近线性,而非传统架构的指数级增长。
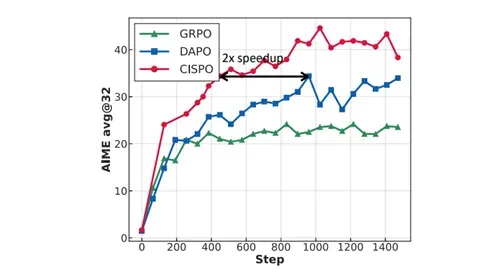
另一关键创新是CISPO算法,这是一种专为提升强化学习效率设计的新型算法。CISPO放弃了信任区域约束,转而对重要性采样权重进行裁剪,确保所有token都能参与梯度计算,避免了传统PPO/GRPO中因裁剪token更新导致的关键推理节点丢失问题。
例如,在基于Qwen2.5-32B模型的对照实验中,CISPO相比DAPO实现了2倍的速度提升,且在相同训练步数下性能优于GRPO和DAPO,有效稳定了训练过程并加速了模型收敛。
在训练框架上,MiniMax-M1结合混合注意力与CISPO算法,实现了高效的强化学习扩展。模型在512块H800 GPU上仅用三周完成全RL训练,租赁成本约53.47万美元。
训练数据涵盖从传统数学推理到基于沙盒的现实软件工程环境等多元任务,其中可验证问题通过规则验证,非可验证问题则借助生成式奖励模型提供反馈。此外,模型还通过持续预训练和监督微调强化基础推理能力,注入链状思维模式,为后续RL阶段奠定基础。
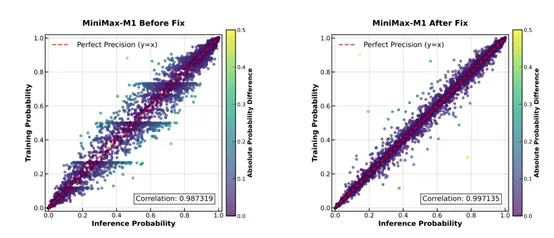
在处理长上下文训练时,MiniMax-M1采用分阶段平滑扩展上下文长度的策略,从32K逐步扩展至100万token,解决了混合Lightning架构下训练长度激进扩展导致的梯度爆炸问题。同时,针对训练与推理内核的精度不匹配问题,通过将LM输出头精度提升至FP32,使训练与推理概率的相关性从0.9左右提升至0.99以上,确保了奖励增长的稳定性。
针对优化器超参数敏感性,调整AdamW的β₁、β₂和ε值,适应模型训练中梯度幅度跨度大、相邻迭代梯度相关性弱的特点,避免了训练不收敛的问题。
模型还引入基于token概率的重复检测早期截断机制,当连续3000个token的概率均高于0.99时终止生成,防止长序列生成中的重复循环导致模型不稳定,提升了生成吞吐量。这些创新模块的协同作用,使MiniMax-M1在复杂软件工程、工具利用和长上下文任务中表现突出,成为下一代语言模型代理处理现实挑战的坚实基础。


