你一生中可能已经多次听说过糖尿病。它如此普遍地流行。根据国际糖尿病联合会的数据,2024年有超过340万人死于糖尿病。这相当于全球各类死亡人数的9.3%。2024年,20-79岁成年人糖尿病患者最多的国家是中国、印度和美国。世界卫生组织(WHO)进一步指出,这种严重的疾病是2021年女性死亡的主要原因之一(具体而言,位列第八)。
那么,糖尿病到底是什么呢?糖尿病并非像常见的误区所说的那样,只是吃太多糖或碳水化合物而引起的疾病。
糖尿病是一种严重的慢性疾病,当人体无法产生足够的胰岛素或无法有效利用已产生的胰岛素时,就会引发血糖升高。糖尿病的主要类型包括1型糖尿病、2型糖尿病和妊娠期糖尿病。1型糖尿病是一种自身免疫性疾病,会导致胰腺中胰岛素分泌细胞的破坏,而2型糖尿病主要与胰岛素抵抗有关。妊娠期糖尿病发生在怀孕期间,通常在分娩后消退。
在本文中,我们将深入探讨一个专注于预测患者糖尿病的机器学习项目。该项目的主要目标是利用患者健康指标准确预测罹患糖尿病的可能性,从而促进早期发现并改善患者预后。
我们在执行此项目时采取的步骤如下:
- 理解数据
- 收集数据
- 数据清洗和验证
- 探索性数据分析
- 特征预处理
- 模型训练
- 模型评估
- 特征重要性
- 测试虚拟数据
理解数据
我必须戴上我的侦探眼镜,深入医疗保健领域——不仅以学生和专业人士的身份,也以患者的身份。对我来说,这才是数据科学的真正意义所在:从微观和宏观两个层面,全面理解你正在解决的问题。它还需要深厚的同理心——将人置于你构建的每一个解决方案的核心。
背景:一家流动医疗诊所希望使用基本健康指标对糖尿病患者进行预筛查,以减少医院拥挤并关注高危人群。
问题描述:使用 EDA 发现显著影响糖尿病风险的因素。开发一个分类模型,根据 BMI、血糖水平、胰岛素水平和年龄等属性预测一个人是否患有糖尿病。
收集数据
一旦确定了最终目标,下一步就是收集与该目标相符的标记数据。[因版面限制,只展示部分代码,本项目的数据集和完整代码获取:@公众号:数据STUDIO 原文《机器学习实战:糖尿病预测分析及可视化》 文末打赏任意金额便可获取]。该数据集最初来自美国国家糖尿病、消化和肾脏疾病研究所。需要特别指出的是,这里的所有患者均为至少 21 岁的皮马印第安血统女性。
工作流程的第一步是导入必要的库。我们首先导入进行分析所需的模块和库。
复制# 用于数值运算、数据操作和数组处理 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns # 用于导入规范化和分类器特征 from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import RandomizedSearchCV from sklearn.neighbors import KNeighborsClassifier from scipy.stats import randint, uniform !pip install xgboost import xgboost as xgb # 用于评估模型指标 from sklearn.metrics import accuracy_score, classified_report, confusion_matrix, ConfusionMatrixDisplay, roc_curve, roc_auc_score # 用于清除所有警告对话框 import warnings warnings.filterwarnings( 'ignore' )
然后将数据加载到notebook中
复制df = pd.read_csv("diabetes.csv")
# 本项目的数据集和代码获取:@公众号:数据STUDIO 原文《机器学习实战:糖尿病预测及可视化分析》 文末打赏任意金额便可获取
df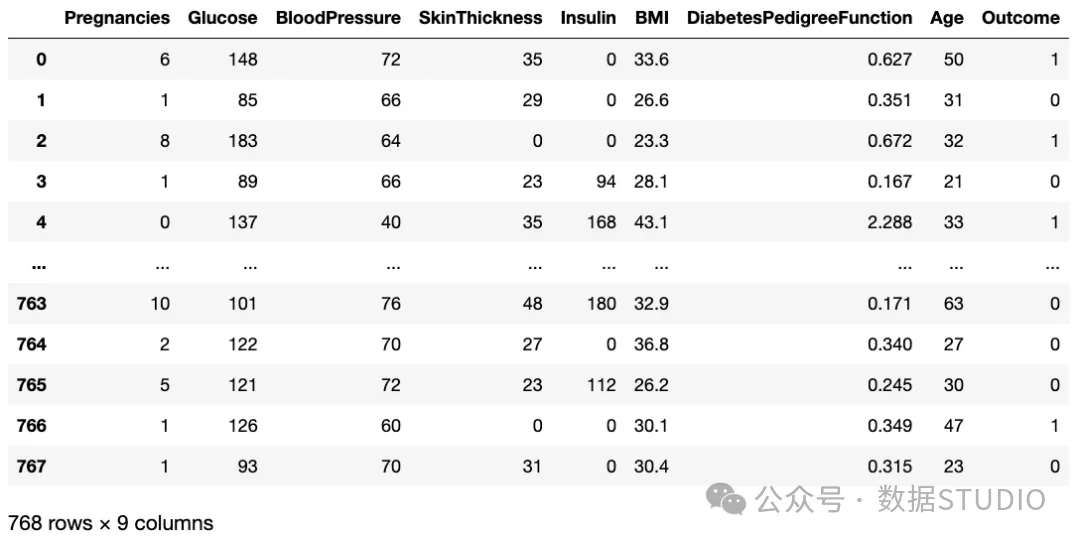 图片
图片
数据集中字段含义:
- Pregnancies:怀孕次数
- Glucose:口服葡萄糖耐量试验(OGTT)中2小时血浆葡萄糖浓度
- BloodPressure:舒张压(毫米汞柱)
- SkinThickness:三头肌皮褶厚度(毫米)
- Insulin:2小时血清胰岛素(μU/ml)。
- BMI:(体重(公斤)/(身高(米)²)
- DiabetesPedigreeFunction:根据家族史,对个人糖尿病遗传易感性进行数值估计。范围从 0.08 到 2.42。
- Age:数据集中患者的年龄
- Outcome:类别变量(0 或 1)指示患者是非糖尿病患者(0)还是糖尿病患者(1)
我们从数据集的形状中获得了 768 个观测值(行)和 9 个属性(列)
数据清洗和验证
在开始任何建模或分析之前,必须仔细验证和清理数据——这是数据科学中经常被低估的关键步骤。首先,我们用放大镜检查是否存在空值或缺失值、重复值或异常值。
复制df.info()复制
<class 'pandas.core.frame.DataFrame'> RangeIndex: 768 entries, 0 to 767 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pregnancies 768 non-null int64 1 Glucose 768 non-null int64 2 BloodPressure 768 non-null int64 3 SkinThickness 768 non-null int64 4 Insulin 768 non-null int64 5 BMI 768 non-null float64 6 DiabetesPedigreeFunction 768 non-null float64 7 Age 768 non-null int64 8 Outcome 768 non-null int64 dtypes: float64(2), int64(7) memory usage: 54.1 KB
乍一看,所有 768 行数据在所有属性上都显示为非空。然而,这并不一定意味着数据集是干净的。它仅仅意味着没有表示为NaN的缺失值。在类似的医学数据集中,可以使用诸如 之类的占位符值0来表示缺失数据,尤其是在葡萄糖、胰岛素或 BMI 等领域,因为 的值0在生理学上是不可信的。
我们已经在数据集中观察到了一些异常零,为了确认这一点,我们做了以下操作:
复制df.describe().T
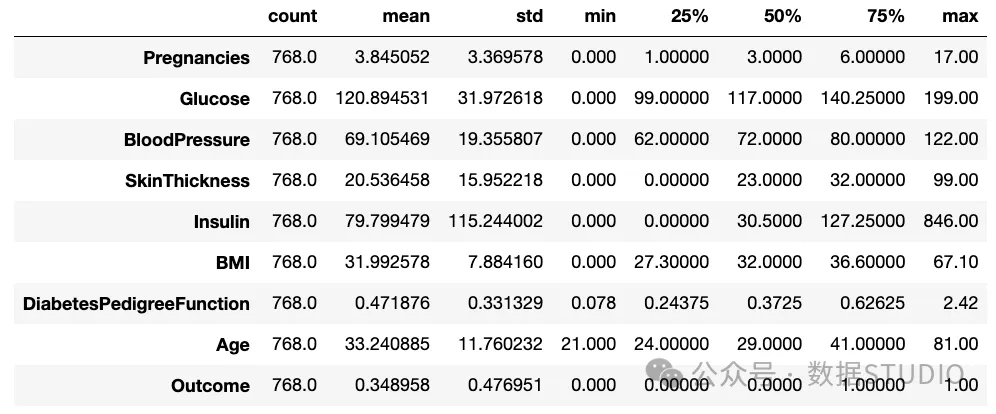 图片
图片
数据集中数值属性的统计分析
我们可以看到,尽管患者0怀孕的可能性很大,但情况不应该如此,尤其是在血糖、胰岛素或BMI、血压和皮肤厚度等领域。
进一步探究,我们制作了一个汇总表,显示了这些异常值的频率
复制# 制作一个 DataFrame 来让我对数值有更多的了解
summary_table = pd.DataFrame({
'Dtype': df.dtypes, # 字典在内部
'Count': df.count(),
'Unique': df.nunique(),
'Null Values': df.isnull().sum (),
'Zero Values': [
(df[col] == 0 ).sum() for col in df.columns],
'Frequent Value (and number of appearences)' : [
f"{df[col].mode()[0]} ({df[col].value_counts().max ()})"for col in df.columns
]
})
summary_table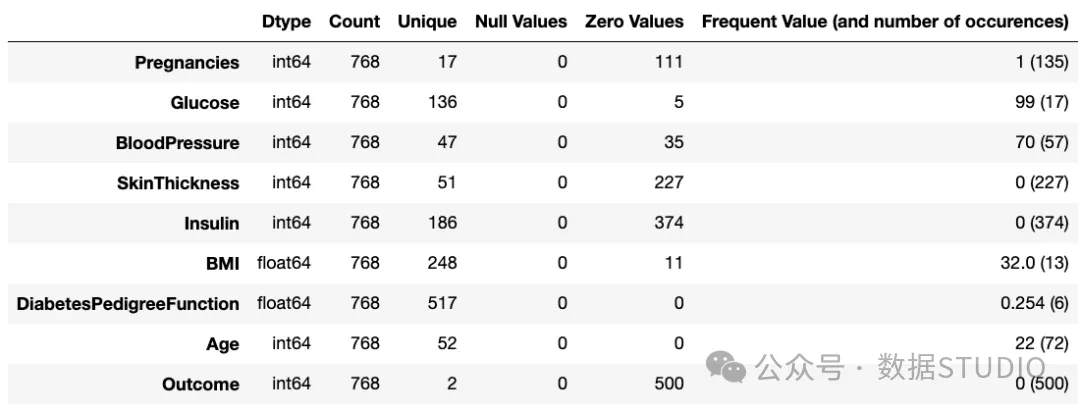 汇总表
汇总表
这些0值在 SkinThickness 和 Insulin 等属性中出现很多次,并且可能极大地影响其数据分布
 检查重复行
检查重复行
我们的数据集中没有重复的行
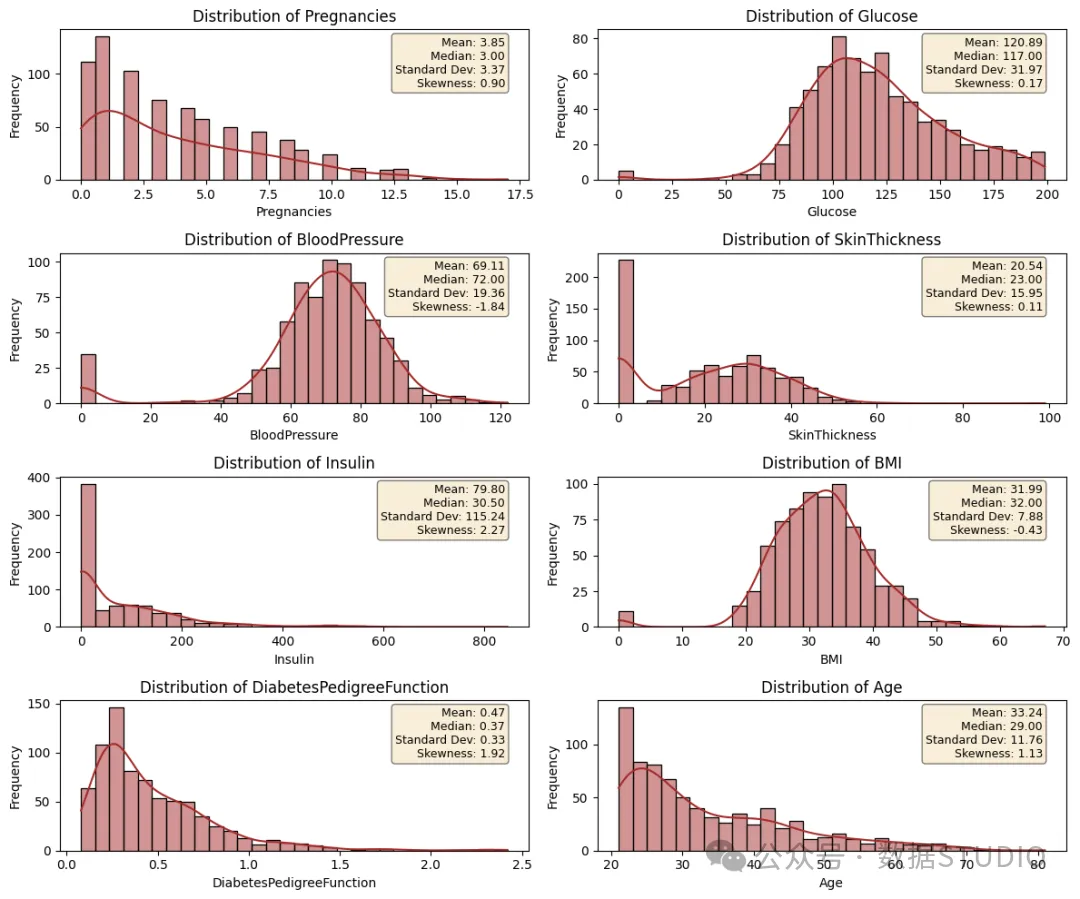 属性的直方图分布
属性的直方图分布
上图旨在检查每个属性分布的偏度,以确定用什么统计量来填充这些0值。对于对称分布(例如,SkinThickness & Glucose),我们稍后会用平均值替换这些缺失值NaN,然后再用平均值填充这些空值;而对于偏斜分布(例如,Insulin, BloodPressure 和 BMI),我们使用中位数来最小化误差。
左偏(负偏): 如果低端(左侧)的尾部比右侧长或更长,则该分布被视为左偏分布。在这种情况下,大多数数据值会向高端(右侧)聚集,而少数低异常值会使均值向下倾斜。因此,平均值通常小于中位数。
右偏(正偏): 右偏分布的尾部(右侧)较长或拉伸。这表明大多数数据点都集中在低端(左侧),而一些高离群值会将平均值向上拉高。在这种情况下,平均值通常大于中位数。
正态分布:关于均值对称的概率分布
还可以用以下图表示:
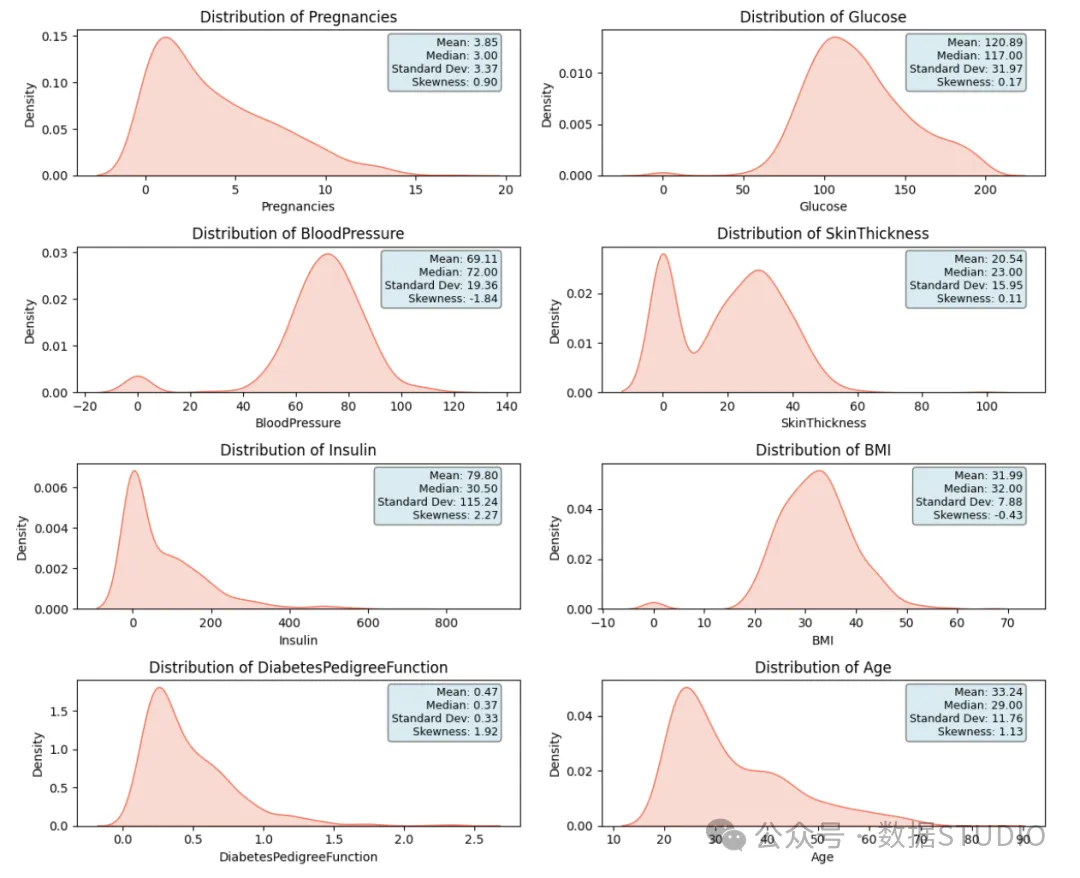
- 怀孕高峰期约为 1-2 次。平均怀孕次数约为 3.85 次,标准差为 3.37 次。这一特征表现为正偏度,偏度为 0.90。
- 葡萄糖水平大多在 100 至 125 毫克/分升之间,平均值约为 120 毫克/分升,标准差为 32。分布接近对称,偏度为 0.17。
- 舒张压的中心倾向接近 60-80mmHg,平均值为 69mmHg,分布(标准差)约为 。它显示出负偏度,其偏度值为 -1.84
- 皮肤厚度平均值约为 20.54 毫米,标准偏差为 。数据接近对称,偏度值为 0.11
- 胰岛素水平主要集中在 0 左右,但平均值上升到 79.80 左右,表明数据呈正偏度分布。偏度值为 2.27,标准偏差为 115.24,相对较高。
- 体重指数值集中在 30-40 附近,平均体重指数为 32,标准差为 7.88。根据-0.43的偏度值,分布呈现轻微的负偏斜
- 糖尿病谱系系数 在 0.3-0.4 附近最为常见,平均值为 0.47,标准差为 0.33。
- 年龄在 20-30 岁左右达到峰值,平均年龄约为 33.27 岁,标准偏差为 11.76。数据分布呈右偏态,偏度值为 1.13。
columns_with_zeros = ['Glucose', 'BMI', 'Insulin', 'SkinThickness', 'BloodPressure'] #将不可能的零值替换为它们的空值 for column in columns_with_zeros: df[column] = df[column].replace(0, np.nan) binomial_columns_with_zeros = ['Glucose', 'SkinThickness'] #用空值替换不可能为零的值 - 平均值(近似对称) for column in binomial_columns_with_zeros: df[column] = df[column].fillna(df[column].mean()) skewed_columns_with_zeros = ['BloodPressure', 'Insulin', 'BMI'] #用空值替换不可能为零的值 - 中位数(偏态) for column in skewed_columns_with_zeros: df[column] = df[column].fillna(df[column].median()) df
探索性数据分析
探索性数据分析 (EDA) 就像拼图游戏一样——数据科学家需要运用他们的分析直觉。在这个阶段,我们开始使用可视化、汇总和统计工具来解答数据背后的what, how, where以及why。在这个阶段,我分析了数据集的结构、分布和关系,以发现有意义的模式并识别糖尿病的潜在预测因子。
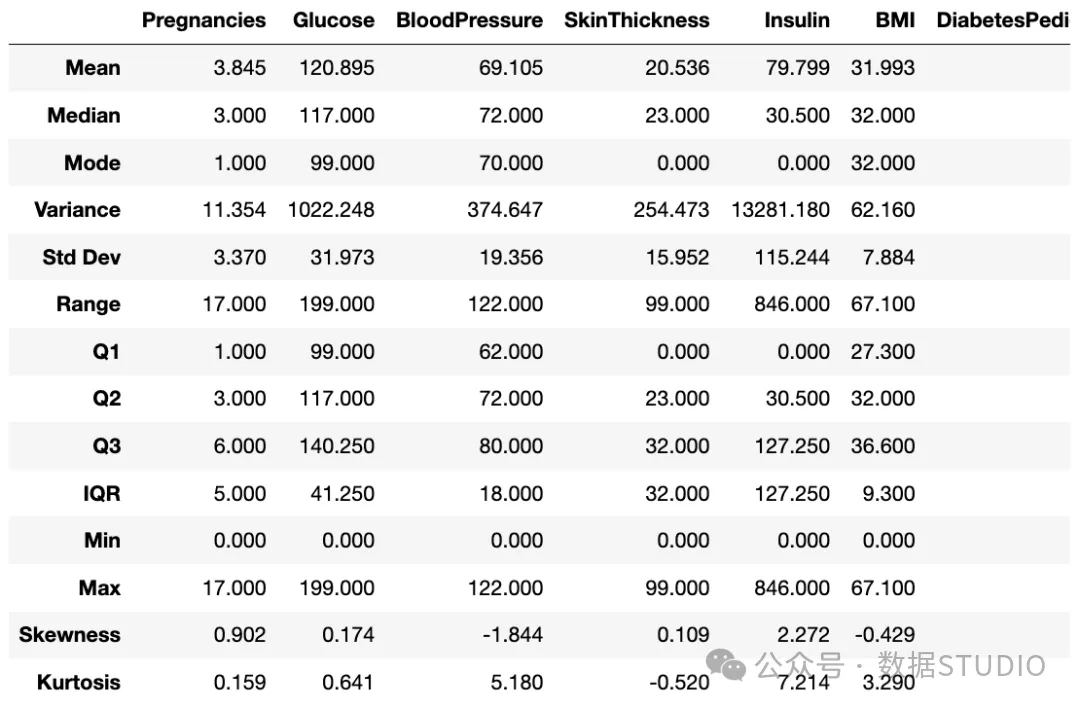 图片
图片
- 怀孕: 怀孕次数的平均值约为 4 次,中位数为 3 次,模式为 1 次,数值范围为 0 至 17 次,标准差为 3.37 次。
- 葡萄糖: 葡萄糖水平平均约为 120.89 mg/dl,中位数为 117.00 mg/dl,模式为 99.00 mg/dl。数值范围从 0 到 199 mg/dl,标准差为 31.97 mg/dl。
- 血压:平均血压约为 69.105 毫米汞柱,中位数为 72.00 毫米汞柱,模式为 70.00 毫米汞柱。测量范围为 0 至 122 mmHg,标准差为 19.356 mmHg。
- 皮肤厚度: 皮肤厚度的平均值为 20.536 毫米,中位数为 23.00 毫米,模式为 0.00 毫米。范围为 0 至 99 毫米,标准差为 15.95 毫米。
- 胰岛素:胰岛素水平平均约为 79.80 单位,中位数为 30.50 单位,模式为 0.00 单位。范围为 0 至 846 单位,标准差为 115.24 单位。
- 体重指数: 平均体重指数(BMI)为 31.993,中位数和模式均为 32.00。数值范围从 0 到 67.10,标准差为 7.884。
- 糖尿病谱系函数: 糖尿病血统函数的平均值为 0.472,中位数为 0.372,模式为 0.254。数值介于 0.08 和 2.42 之间,标准差为 0.331。
- 年龄:平均年龄为 33.24 岁,中位数为 29.00 岁,模式为 22.00 岁。年龄范围在 21 至 81 岁之间,标准差为 11.76 岁。
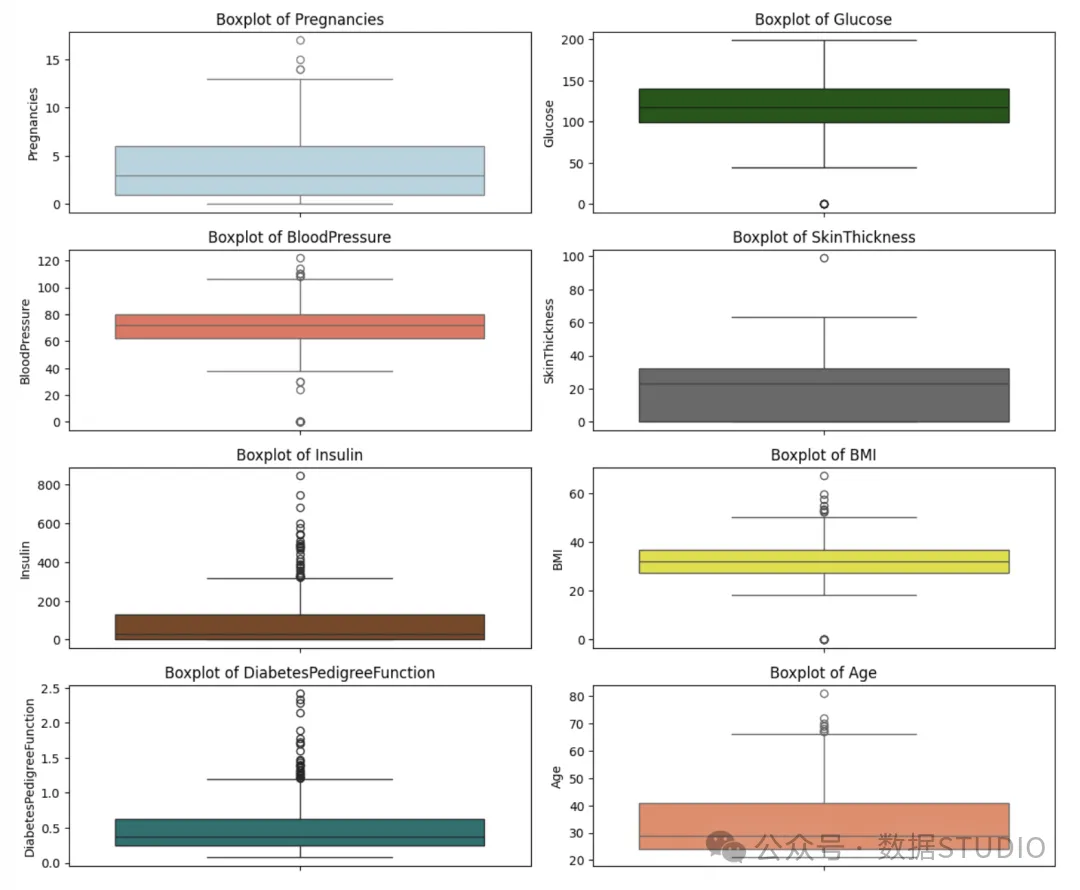 图片
图片
- 怀孕次数中位数约为 3-4,有几个较高的离群值(如 15+ 怀孕)。0 这样的值不是离群值,这是合乎逻辑的。
- 葡萄糖中位数约为 110-120。由于数值较高(高达约 200),出现了明显的右斜。包括 0 在内的极低值为异常值--在医学上难以置信,可能是数据缺失或错误。
- 血压中位数约为 70-75 mmHg。有几个值为 0,明显是异常值,不符合生理学原理。血压分布比较对称,但这些 0 值需要清理。
- 皮肤厚度中值约为 23-25 mm。0 的数量非常多--强烈表明数据缺失或有误。也有一些上限离群值(约 100),但主要问题是 0。
- 胰岛素极度右偏。数值差异巨大,有许多离群值(高达 800+)。0 很常见,可能表示数据缺失--在现实世界的数据集中,胰岛素经常缺失。
- 体重指数中位数约为 32。0 值也是异常值--不太可能对体重指数有效。其他方面呈右偏分布,但分布相当紧凑。
- 糖尿病谱系系数中位数约为 0.4。右偏,有许多轻度和极端异常值(>1.5)。没有明显的无效值,但该属性的差异很大。
- 年龄中位数约为 29-30。右偏,尾部延伸至 80 岁。没有明显的无效异常值;分布看起来很自然。
- 怀孕糖尿病患者的怀孕次数往往较多。结果 = 1 的怀孕次数中位数更高。糖尿病患者的分布范围更广。
- 血糖明显区别:糖尿病患者的血糖水平明显更高。在该数据集中,葡萄糖是一个强有力的指标--IQR 的重叠极少。两组中都有异常值,但非糖尿病组的异常值更大。
- 血压中位数相当接近,但糖尿病患者的数值略高。非糖尿病组的异常值较低。总体而言,血压可能不是一个强有力的区分指标。
- 皮肤厚度糖尿病患者和非糖尿病患者之间的差异很微妙。两组的中位数和均方根值相似。糖尿病患者的几个异常值延伸得更远,但这一特征似乎不那么具有决定性。
- 胰岛素两组的差异都很大,都有很多异常值。糖尿病患者的中位数似乎略高,但重叠程度较大。
- 体重指数糖尿病患者的体重指数普遍较高。两组之间的中位数有明显变化。分布略偏右,有一些异常值,但这是一个有用的特征。
- 糖尿病谱系系数糖尿病组的平均值较高。糖尿病患者中有许多高值异常值,表明遗传风险更大。虽然分布有所重叠,但这一特征有助于预测。
- 年龄糖尿病患者往往年龄较大。中位数和 IQRs 有明显差异,糖尿病组的高端值更多。这一特征似乎非常相关。
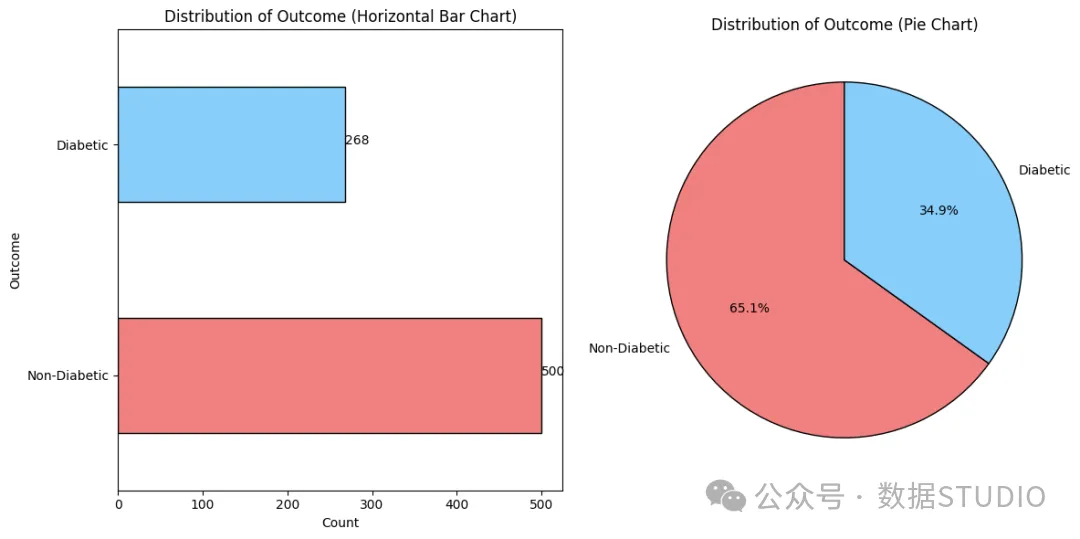 皮马印第安人数据集中的结果分布
皮马印第安人数据集中的结果分布
从上图可以看出,我们有 500 名非糖尿病患者和 268 名糖尿病患者。这使得分布不平衡(即数据集中的目标变量或类别没有被平等地表示出来),如果处理不当,可能会导致潜在的偏差或泛化能力差。
每个属性的平均分布(按结果着色)
上方的条形图显示了每个数值特征的平均值,并以Outcome变量(指示一个人是否患有糖尿病)分隔开。这有助于理解两组之间每个健康指标的平均值有何差异。我们注意到,糖尿病
患者和非糖尿病患者的胰岛素、血糖、年龄和BMI水平之间存在明显的一致性。这表明上述指标是患者患糖尿病的明确指标。妊娠期的一致性表明,有过多次妊娠的女性患妊娠期糖尿病的风险更高。
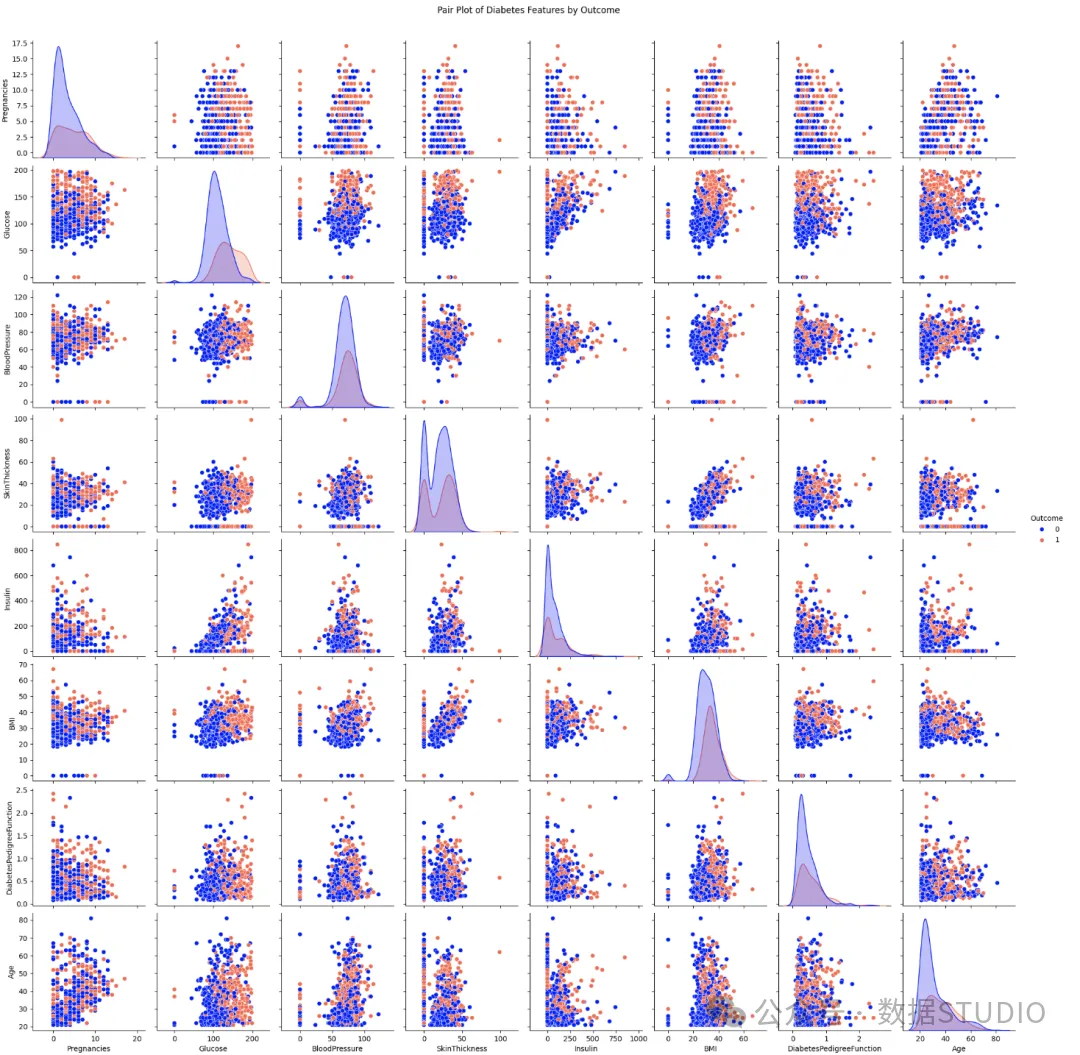 图片
图片
从非对角线(散点图)中发现:
- 葡萄糖似乎是一个非常重要的特征。在大多数涉及葡萄糖的散点图中,两个结果类别有明显的分离,橙色/红色(可能是 “糖尿病”)点一般出现在葡萄糖值较高的地方
- 葡萄糖与胰岛素:存在正相关。随着葡萄糖的增加,胰岛素也会增加。糖尿病 "组通常显示较高的葡萄糖和胰岛素值。
- 葡萄糖与体重指数: 呈正相关。较高的葡萄糖通常与较高的体重指数相关。糖尿病 "组的血糖和体重指数通常较高。
- 葡萄糖与年龄的关系:总体趋势是,葡萄糖水平越高,年龄就越大,尤其是 “糖尿病” 结果。
- 体重指数似乎也是一个很好的区分特征。
- 体重指数与血压:存在正相关关系,体重指数越高,血压越高。
- 体重指数与年龄: 可能存在微弱的正相关。
- 怀孕次数与年龄:存在正相关,正如预期的那样,年龄越大的人怀孕次数越多。
- 胰岛素及其分布:涉及胰岛素的散点图突显了其奇特的分布。许多点聚集在零点附近,这是用零值计算的缺失数据。对于非零胰岛素值,与葡萄糖呈正相关,这表明随着葡萄糖水平的升高,人体会分泌更多的胰岛素来控制葡萄糖水平,但对于糖尿病患者来说,这种反应可能不足或无效。
- 皮肤厚度与体重指数: 皮肤厚度与体重指数之间有很强的正相关性,这在生理学上是意料之中的,因为两者都与身体脂肪有关。
- 血压及其影响:虽然血压显示了一些趋势,但它本身似乎并不像葡萄糖或体重指数那样具有强烈的区分作用。
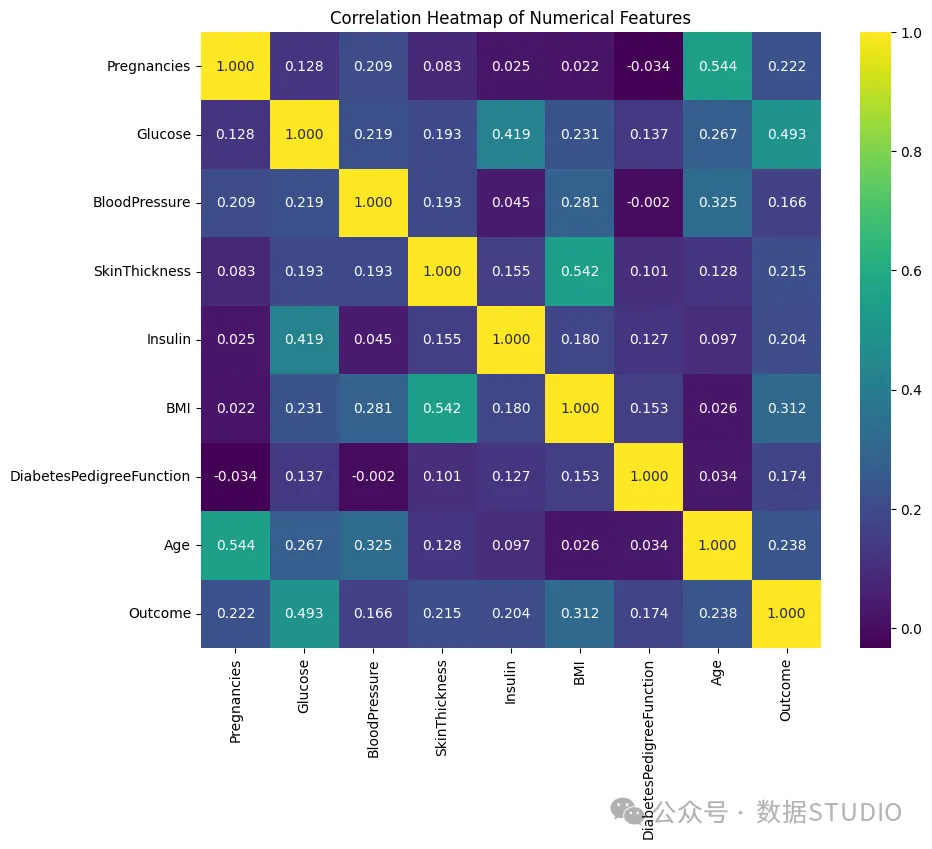 相关性热图
相关性热图
上图给出了属性之间的相关性矩阵,范围从 -1(强负相关性)、0(无相关性)和+1(强正相关性)。
与结果的相关性:
- Glucose和Outcome之间存在中等强度的正相关性。这是完全可以预料到的,因为高血糖水平是糖尿病的主要指标。这表明,随着血糖水平的升高,出现积极结果(糖尿病)的可能性也会增大。
- BMI和Outcome之间存在中等强度的正相关性。
- BMI较高通常意味着患糖尿病的风险较高。
- Age和Outcome之间存在微弱的正相关性。患糖尿病的风险通常会随着年龄的增长而增加。
- Pregnancies和Outcome之间存在微弱的正相关性,这可能与妊娠期糖尿病或多胎妊娠可能与以后患 2 型糖尿病的风险较高有关。
# 根据可靠的健康分类分层,对年龄、BMI、血压进行分类属性
# 本项目的数据集和代码获取:@公众号:数据STUDIO 原文《机器学习实战:糖尿病预测分析及可视化》 文末打赏任意金额便可获取
df['AgeGroup'] = pd.cut(df['Age'], bins=[20, 30, 40, 50, 60, 100], labels= ['Young Adult', 'Early Middle Age', 'Late Middle Age', 'Early Senior', 'Senior'])
df['BMI_Group'] = pd.cut(df['BMI'], bins=[0, 18.5, 25, 30, 100], labels=['Underweight', 'Normal', 'Overweight', 'Obese'])
df['BloodPressure_Group'] = pd.cut(df['BloodPressure'], bins=[0, 60, 80, 90, 120, 200], labels=['Low', 'Normal', 'Pre-hypertension', 'Stage 1 Hypertension', 'Stage 2 Hypertension'])
df['Outcome_Group'] = df['Outcome'].map({0: 'No Diabetes', 1: 'Diabetes'})
df['Glucose_Category'] = pd.cut(df['Glucose'], bins=[0, 140, 200], labels=['Normal', 'Impaired glucose tolerance'])
df[['Glucose', 'Glucose_Category']]
# 根据提供的范围定义胰岛素类别
df['Insulin_Category'] = pd.cut(df['Insulin'],
bins=[0, 30, 100, 150, 1000], # Increased upper bound to include high values
labels=['< 30 (Possible Deficiency)', '30-100 (Normal)', '100-150 (Early Resistance)', '> 150 (Significant Resistance)'],
right=False) # 使用 right=False 使箱体不包括右边缘,与描述相匹配
# 定义 DiabetesPedigreeFunction 的箱
bins = [0, 0.5, 1.0, 1.5, df['DiabetesPedigreeFunction'].max()]
labels = ['0-0.5', '0.5-1.0', '1.0-1.5', '>1.5']
# 为 DPF 箱体创建新列
df['Pedigree_Bin'] = pd.cut(df['DiabetesPedigreeFunction'], bins=bins, labels=labels, right=False)为了增强可解释性并揭示数据中更深层次的模式,我根据既定的医疗保健分层,将几个连续的健康指标转化为具有临床意义的类别。这一步骤可以实现更直观的分析和可视化,尤其是在比较不同人群的糖尿病结果时。
- Age按照生命阶段分为以下几个组:青年(21-30 岁)、中年早期(31-40 岁)、中年晚期(41-50 岁)、老年早期(51-60 岁)和老年(61 岁以上)。
- BMI使用 WHO 标准分类对值进行分组:体重过轻(<18.5)、正常(18.5–24.9)、超重(25–29.9)和肥胖(30+)。
- 根据Blood Pressure舒张压截断值,将血压分为临床范围:低血压、正常血压、高血压前期和1-2 期高血压。
- 二元变量Outcome被映射到更易读的标签——糖尿病和非糖尿病,以便图表和表格更加清晰。
- Glucose分为两个主要诊断范围:
正常(<140mg/dL)
糖耐量受损(140-199mg/dL)。这些阈值反映了 2 小时口服葡萄糖耐量测试 (OGTT) 中使用的标准指南,有助于识别可能处于糖尿病前期的个体。
- 根据Insulin胰岛素敏感性和抵抗性的临床解释,将水平分为四类:
< 30 μU/mL — 可能存在胰岛素缺乏,
30–100 μU/mL — 正常2小时血清胰岛素反应
100–150 μU/mL — 胰岛素抵抗的早期迹象
150 μU/mL — 严重的胰岛素抵抗。定义的分箱既反映了诊断范围,也反映了数据集中观察到的分布。使用right=False确保每个类别的上限不重叠
虽然这DiabetesPedigreeFunction并非传统意义上的临床指标,但它有助于根据家族史了解患者的糖尿病遗传易感性。为了更直观地分析这一特征,我将连续的DPF值划分为四个分类箱。这些分类箱有助于突出显示遗传风险的增加与数据集中糖尿病患病率之间的关联。
现在,进入分类图表:
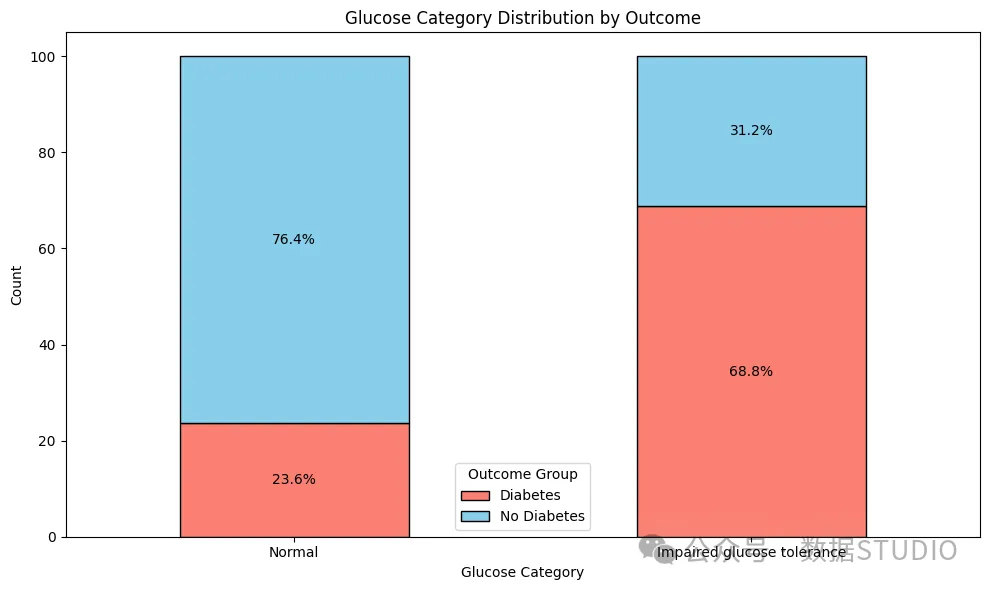 按结果对葡萄糖进行分类
按结果对葡萄糖进行分类
这张堆叠条形图显示了两组血糖类别中糖尿病阳性和阴性结果的百分比。它告诉我们,血糖受损的糖尿病患者比例要高得多。因此,这再次印证了我们的假设:血糖是最终糖尿病结果的关键决定因素。所有年龄段的人都应定期进行血糖检测,即使患者尚未患糖尿病。
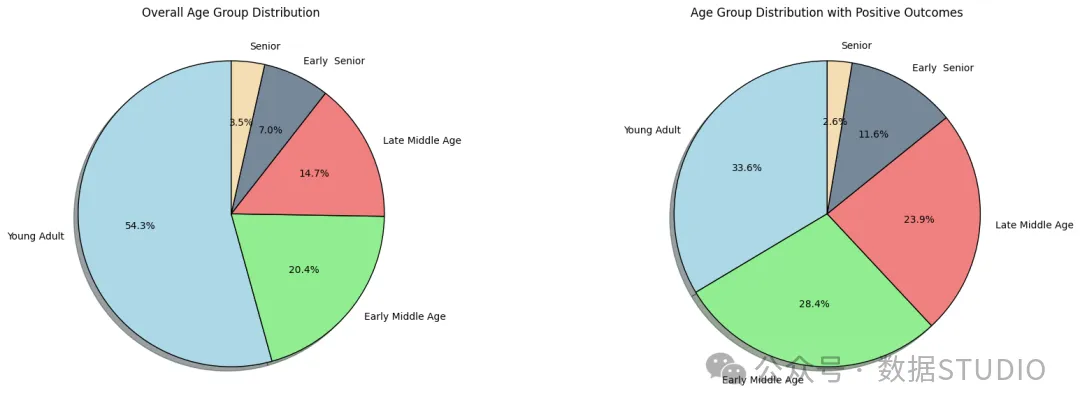 年龄分布——饼图
年龄分布——饼图
从两个饼图来看,老年人在我们的数据集中没有得到充分体现,因此我们可以对这个年龄段的分析持保留态度。
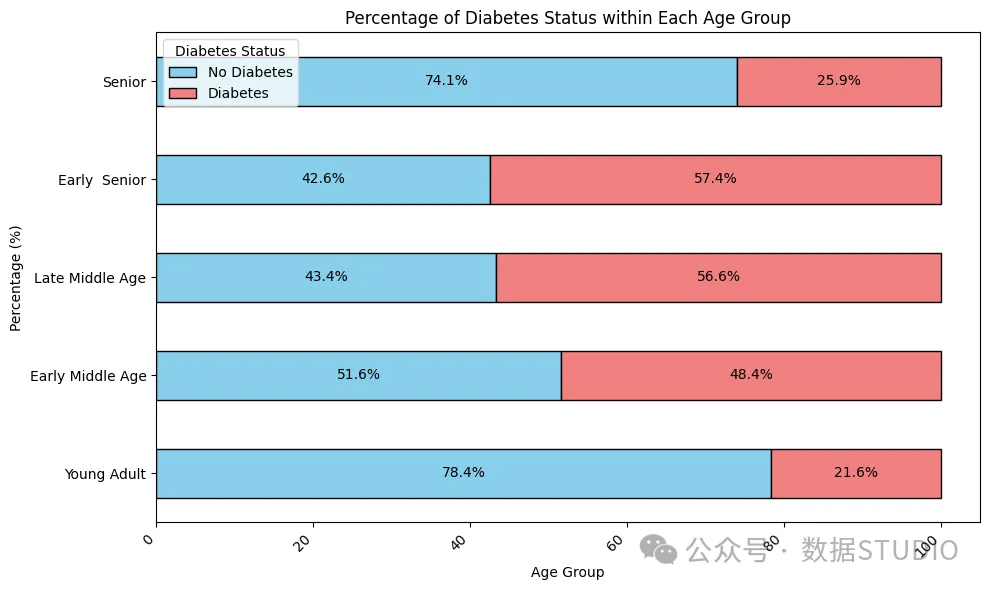 结果分布——年龄组
结果分布——年龄组
这张水平条形图展示了各年龄段糖尿病状况的分布情况。由此可见,患糖尿病的风险较高的人群是中年早期(31-40岁)和老年早期(51-60岁)。因此,强烈建议在40岁这个门槛上进行早期检测和监测。
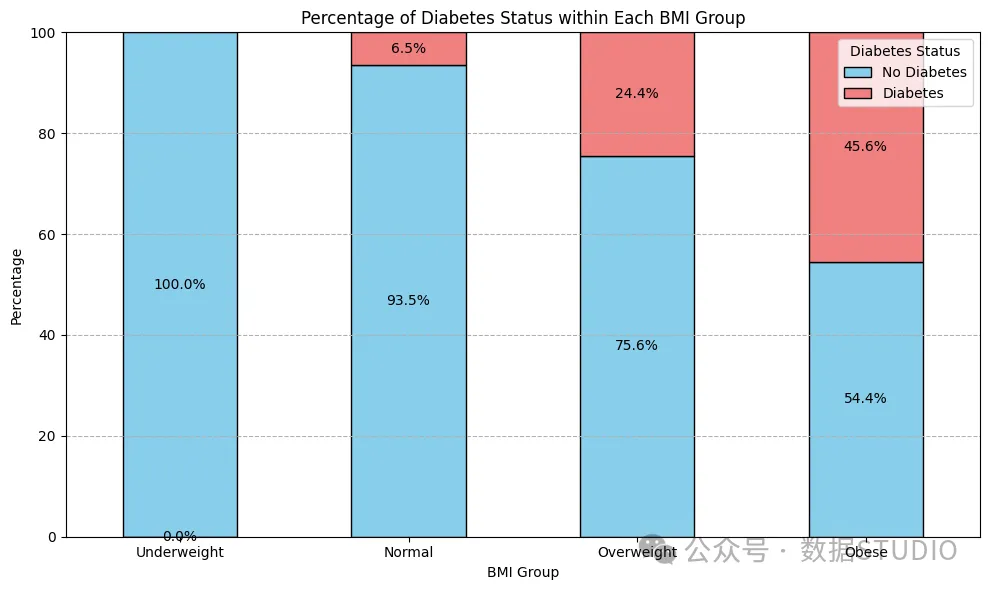 结果分布 — bmi 集团
结果分布 — bmi 集团
由此可见,BMI 肥胖人群最容易患糖尿病。因此,对患者采取积极的体重管理策略是最可行的解决方案。
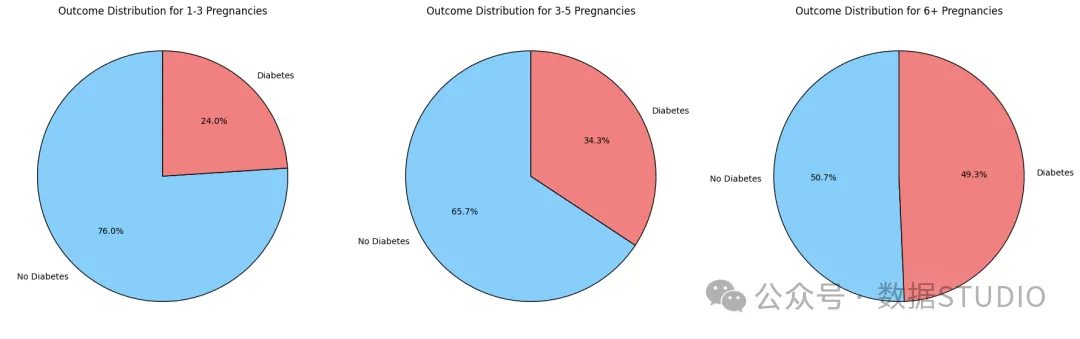 结果分布——分级妊娠
结果分布——分级妊娠
妊娠次数与糖尿病患病率之间似乎存在某种关联。随着妊娠次数的增加,确诊患有糖尿病的女性比例也显著增加。这进一步表明,多次妊娠的女性患妊娠期糖尿病的风险可能更大。
 结果分布——dpf
结果分布——dpf
从上面的多条形图中可以看出,在谱系功能较高的人群中,糖尿病患者的相对比例往往较高。这也表明遗传易感性可能是一个影响因素。
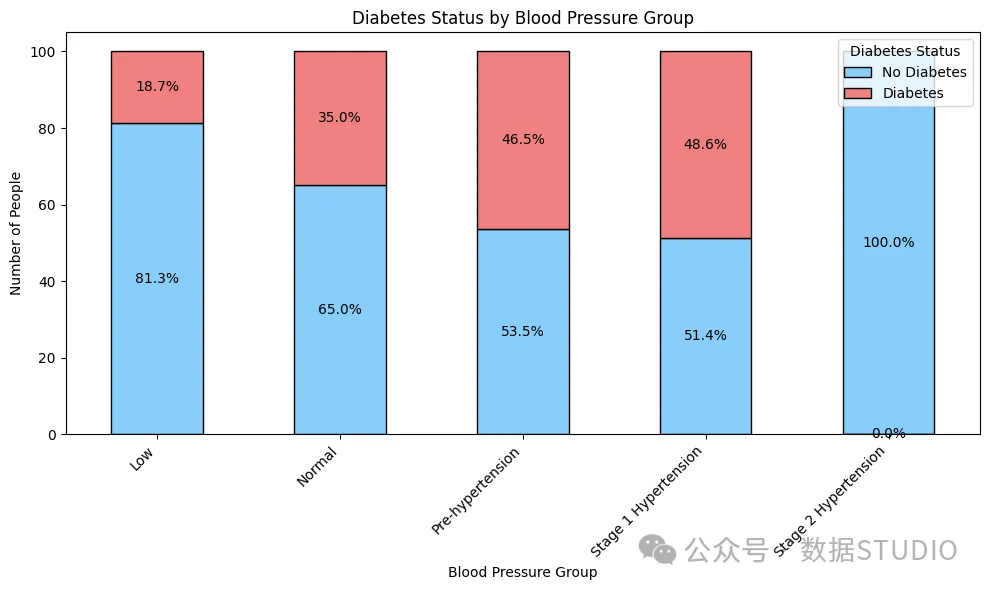 仅有一次观察结果显示患有 2 期高血压(数据不足)
仅有一次观察结果显示患有 2 期高血压(数据不足)
从我理解数据的背景来看,糖尿病患者患高血压的可能性是普通人的两倍。这更像是糖尿病的后遗症,而非病因。糖尿病会损伤肾脏,导致水盐潴留,进而导致血压升高。因此,糖尿病对高血压前期和一期高血压患者的影响更为显著。
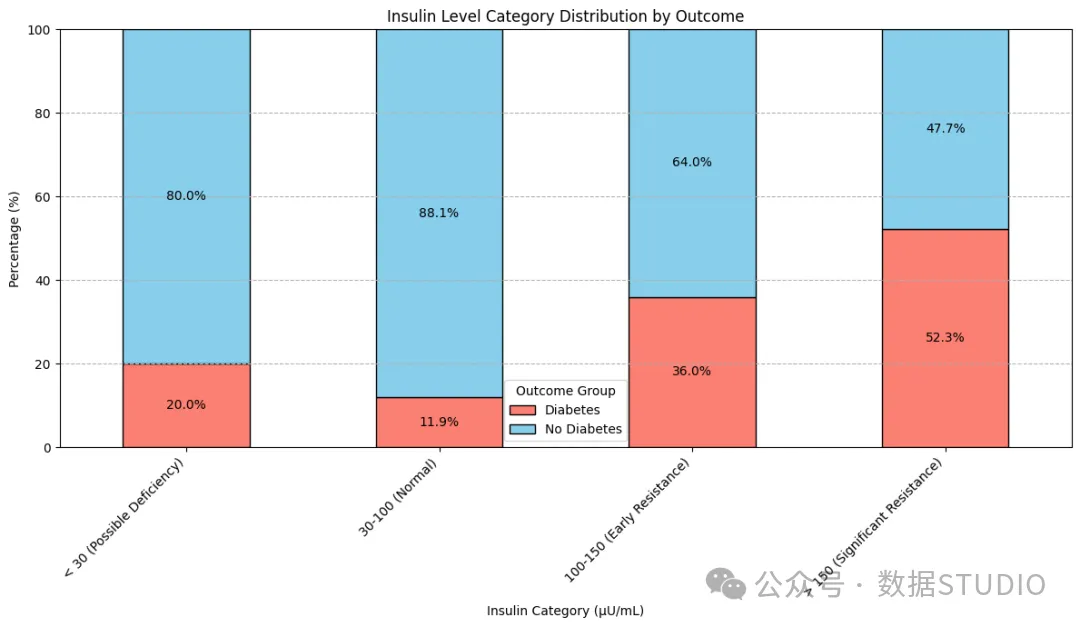 结果分布——胰岛素
结果分布——胰岛素
胰岛素抵抗通常是血糖水平受损的先兆。这意味着抵抗力显著的个体最容易患糖尿病,超过一半的严重抵抗女性患有糖尿病。这个问题可以通过定期检测患者的胰岛素水平来解决。100mU/mL 应作为进一步监测和采取早期预防措施的标志。
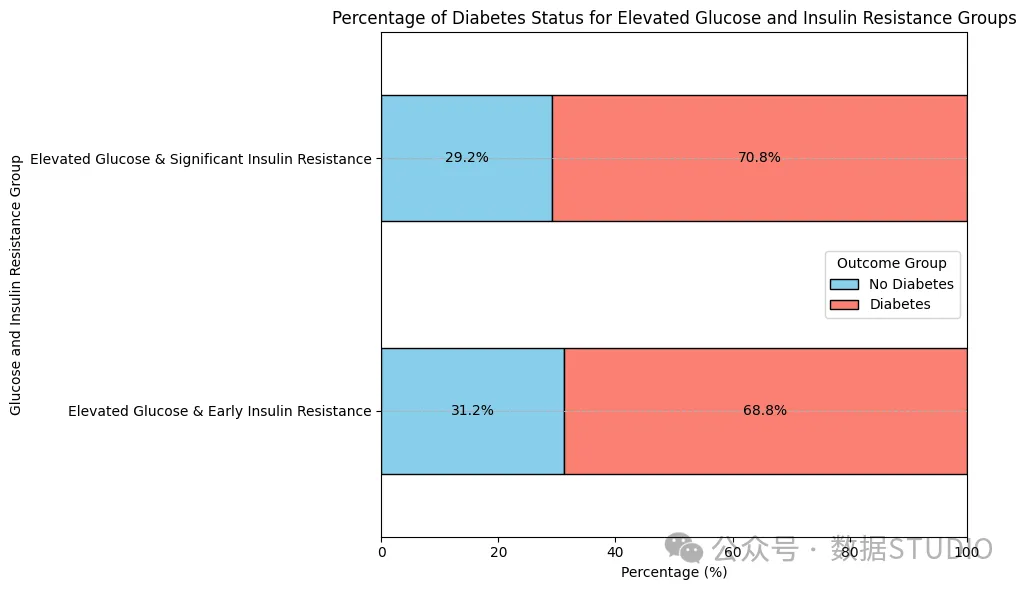 结果分布——胰岛素和葡萄糖
结果分布——胰岛素和葡萄糖
由于血糖和胰岛素是手动设置的属性,我们使用了屏蔽函数、运算符和位置寻址来整合先前创建的Glucose_Category和Insulin_Category列中的信息。这可以根据患者的血糖和胰岛素水平识别特定的亚组,并仅关注属于这些定义的高血糖和胰岛素抵抗组的患者。
这里的数字高得惊人,如果病人的血糖水平处于这些高值范围之间,那么他们患糖尿病的可能性就很大
特征预处理
完成整个 EDA 后,需要准备用于建模的数据。首先,我们准备用于训练机器学习模型的特征(自变量)。在监督学习中,我们将数据集分为特征(用于进行预测的数据)和目标变量(我们想要预测的内容)。
复制X = df.drop(columns=df.select_dtypes(exclude=np.number)) X.drop(columns=['Outcome'], inplace=True) X y = df['Outcome'] y
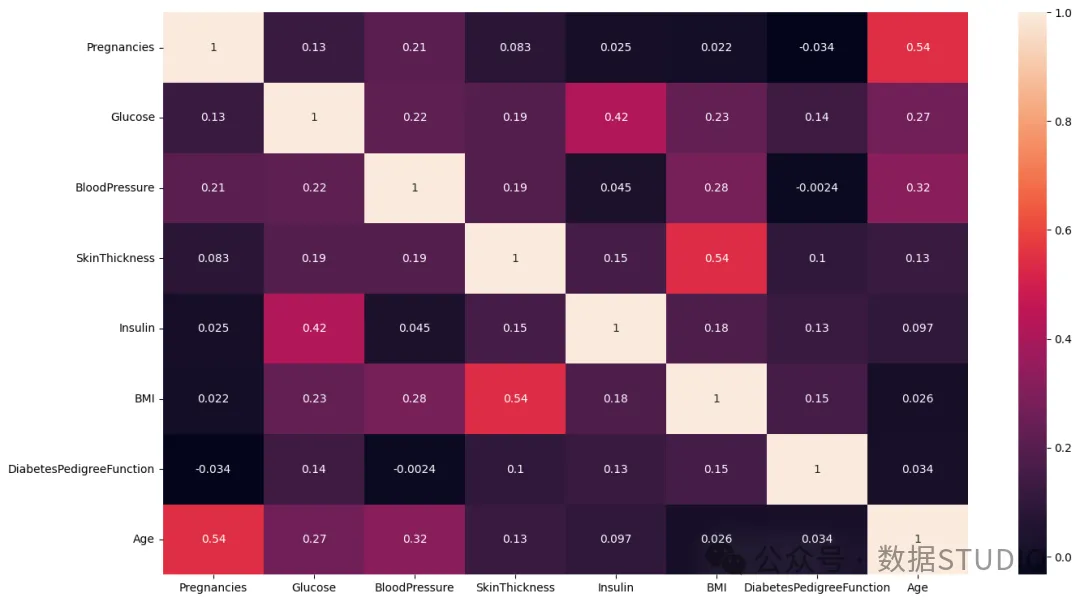 特征相关性
特征相关性
独立特征之间的相关性:Glucose和Insulin之间存在相对较强的正相关性。这在生物学上是合理的,因为胰岛素会根据血糖水平释放以调节血糖水平。SkinThickness和BMI是独立特征之间最强的相关性之一。这很合理,因为皮褶厚度测量值通常用于计算或与BMI相关。Pregnancies和Age也暗示了强烈的正相关性。这是合乎逻辑的,因为女性随着年龄的增长通常会怀孕更多次。
弱/负相关性:注意一些非常弱或接近于零的相关性,例如BloodPressure和Insulin(0.045)或DiabetesPedigreeFunction和BloodPressure(-0.0024)。这些低值表明这些特征在很大程度上以线性方式相互独立(例如Pregnancies和DiabetesPedigreeFunction(0.034))。
特征缩放
复制scaler = StandardScaler() scaledX = scaler.fit_transform(X)
标准化是机器学习中常见的预处理步骤,旨在确保值较大的特征不会对模型造成不成比例的影响。这可以通过将数据变换为平均值为 0、标准差为 1 来实现。
特征指标
 理解混淆矩阵
理解混淆矩阵
再次,你还记得我们说过这个数据集不平衡吗?你的模型可能倾向于多数类,即使你获得了很高的准确率,也可能在关键的地方表现不佳。95% 的准确率可能掩盖了模型从未正确预测少数类(重要的类)的事实——而当它真正重要时,这可能会带来灾难性的后果。因此,我们不应该关注准确率,而是应该评估这些模型的指标:精度、准确率、F-1 分数和 AUC(曲线下面积)。
精确度是:“模型每次说‘糖尿病’时,有多少人实际上是糖尿病患者?”——如果你的模型说有 10 个人是糖尿病患者,但实际上只有 6 个人是糖尿病患者,那么你的精确度就是 0.6(非糖尿病患者也是如此)
召回率是: “在所有实际的糖尿病病例中,模型捕获了多少个?”——这对于非糖尿病类别也存在)
F1 分数是: “精确度和召回率之间的平衡点在哪里?”——这通常是不平衡数据集的最佳指标。它是精确度和召回率的调和平均值。为了获得较高的 F1 分数,你的召回率和精确度也必须很高。
AUC 是: “模型能多好地区分类别(例如,是与否)?”——这个值介于 0 到 1 之间。这往往会对模型的整体性能进行排名
训练-测试拆分验证
为了评估机器学习模型的性能,必须将数据集拆分为两部分:用于训练模型的训练集,以及用于评估模型在未知数据上表现的测试集。我们将数据集的 20% 分配给测试集,80% 分配给训练集。我们使用 Scikit-learn 的训练-测试拆分功能来执行此操作。
复制X_train,X_test,y_train,y_test = train_test_split(scaledX,y,test_size= 0.2,random_state= 42)
模型训练
因为这是一个分类模型,所以我们将使用决策树、随机森林等分类模型。
我们从逻辑回归开始:
复制# 训练模型以使其根据输入进行预测 log = LogisticRegression() log.fit(X_train, y_train) # 使用训练好的对数模型对测试数据集进行预测 log_preds = log.predict(X_test)
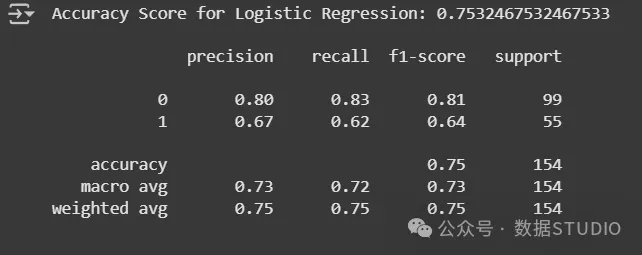 评估:逻辑回归的准确度评分和分类报告
评估:逻辑回归的准确度评分和分类报告
评估:逻辑回归的准确度评分和分类报告
随机森林分类
现在我们尝试随机森林
复制forest = RandomForestClassifier(random_state=56) #为了便于复现 forest.fit(X_train, y_train) #训练模型 forest_preds = forest.predict(X_test) #在未见过的数据上测试模型
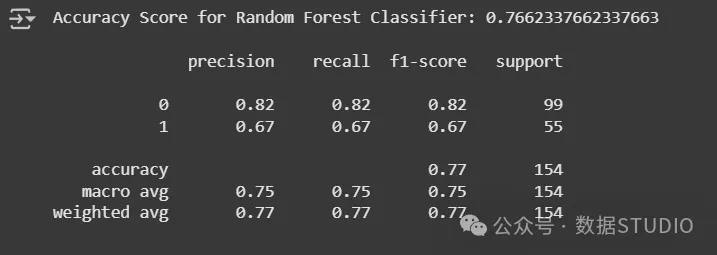 评估:随机森林的准确率得分和分类报告
评估:随机森林的准确率得分和分类报告
评估:随机森林的准确率得分和分类报告
决策树分类器
接下来是决策树:
复制#初始化决策树分类器 tree = DecisionTreeClassifier(random_state= 56 ) # 将模型拟合到训练数据 tree.fit(X_train, y_train) # 对测试数据进行预测 tree_preds = tree.predict(X_test)
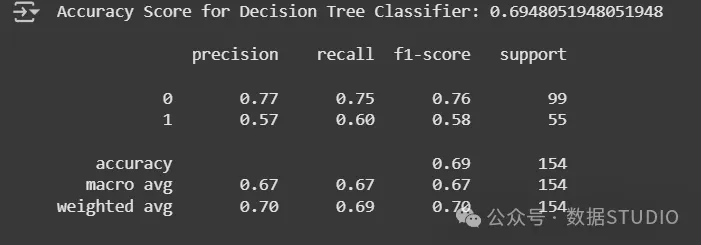 评估:决策树的准确度得分和分类报告
评估:决策树的准确度得分和分类报告
评估:决策树的准确度得分和分类报告
KNN分类器
K最近邻分类器下一步:
复制# 初始化 KNN 分类器 knn = KNeighborsClassifier(n_neighbors= 25 ) # 您可以选择邻居的数量(k) # 将模型拟合到训练数据 knn.fit(X_train, y_train) # 对测试数据进行预测 knn_preds = knn.predict(X_test)
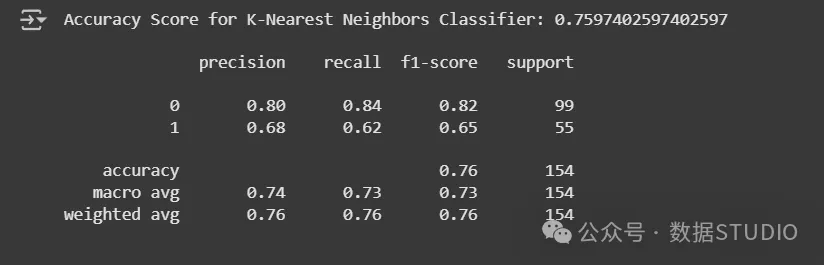 评估:K最近邻分类器的准确率和分类报告
评估:K最近邻分类器的准确率和分类报告
评估:K最近邻分类器的准确率和分类报告
XGBoost分类器
复制# 创建 XGBoost 分类器 xgb_model = xgb.XGBClassifier(random_state= 42 ) # 训练模型 xgb_model.fit(X_train, y_train) # 进行预测 xgb_preds = xgb_model.predict(X_test)
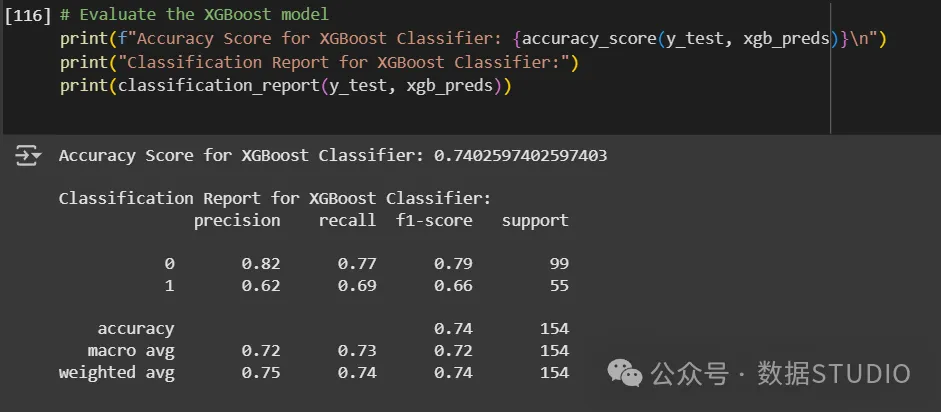 评估:xgbclassifier 的准确率和分类报告
评估:xgbclassifier 的准确率和分类报告
不同模型ROC对比
我们对比了多个模型训练效果如图所示:
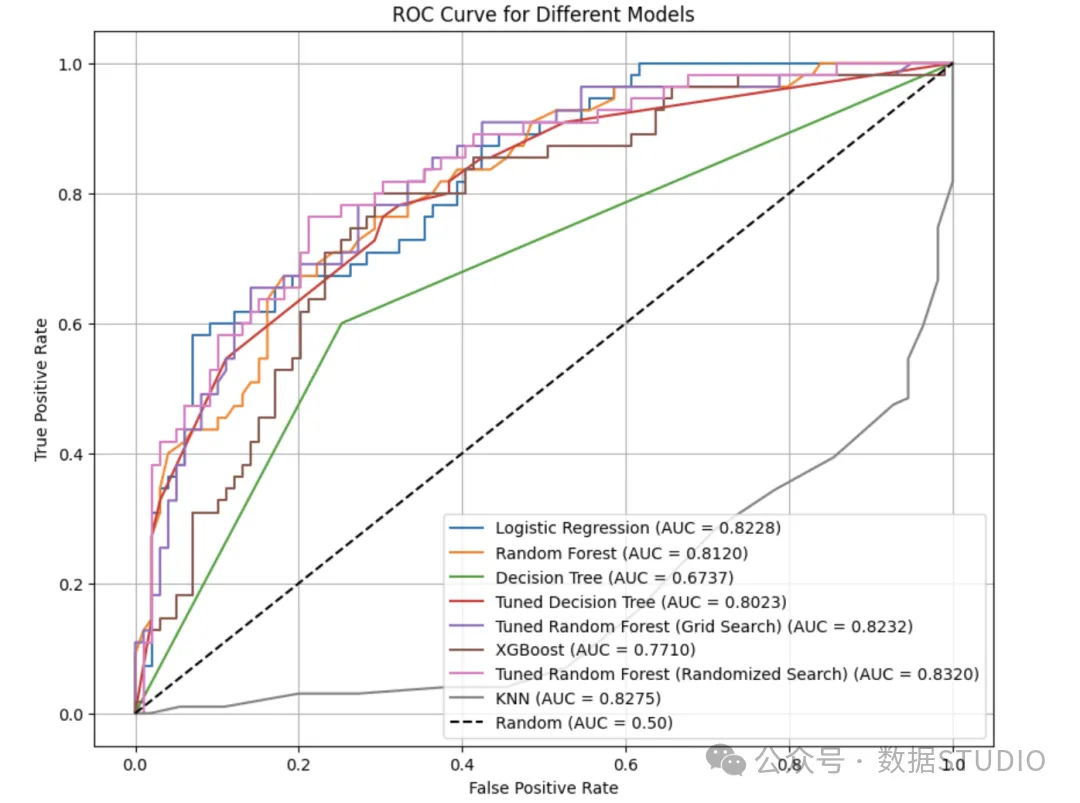 图片
图片
超参数调整
我们对随机森林和决策树模型执行了 GridSearch 和 RandomizedSearchCV,希望在评估期间获得更好的 F1 分数。
以下是所有模型的最终表现:
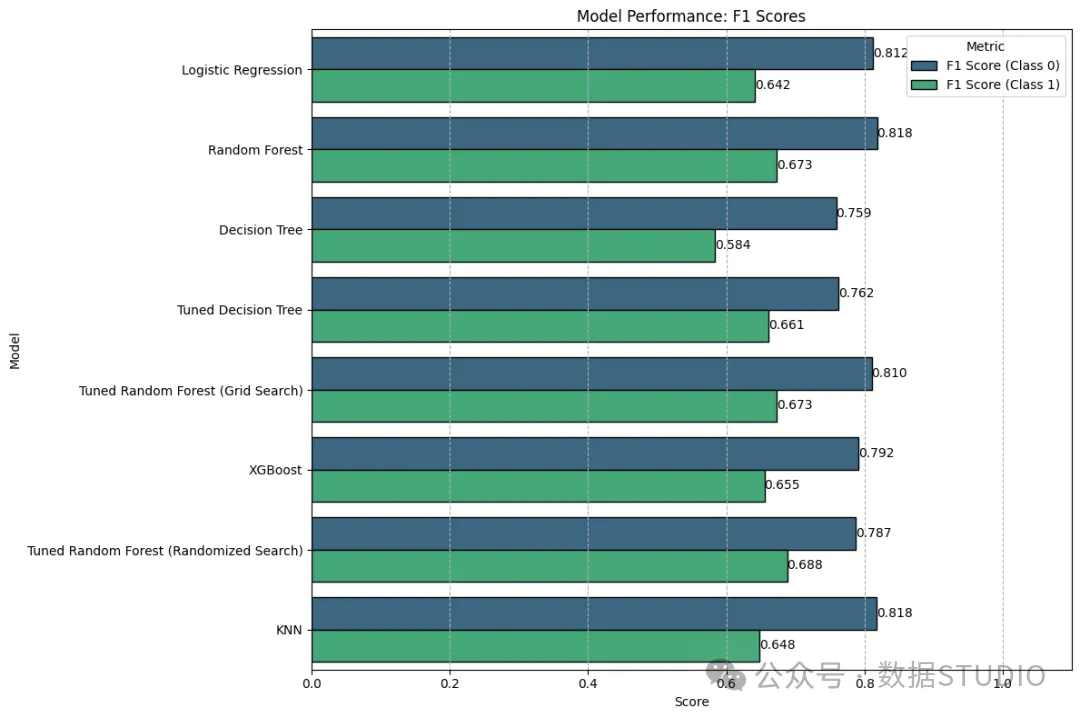 模型性能
模型性能
调整随机森林(随机搜索)在少数结果中表现最佳,而 KNN 在多数结果中表现最佳。我们选择部署调整随机森林来测试我们的虚拟数据,但这还有待观察。
这是所有使用的模型的 2*4 混淆矩阵
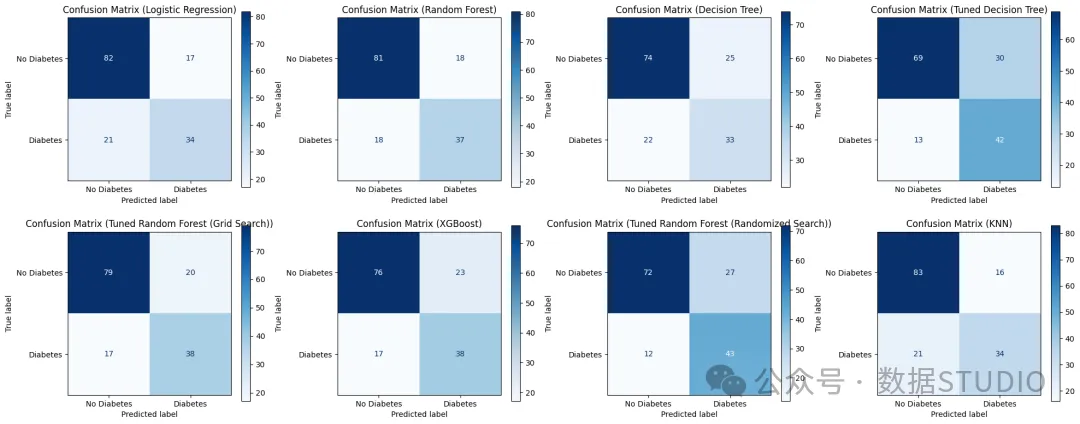 图片
图片
特征重要性
这有助于我们对每个模型在训练和测试中使用的属性进行排名,以确定或选择类别。
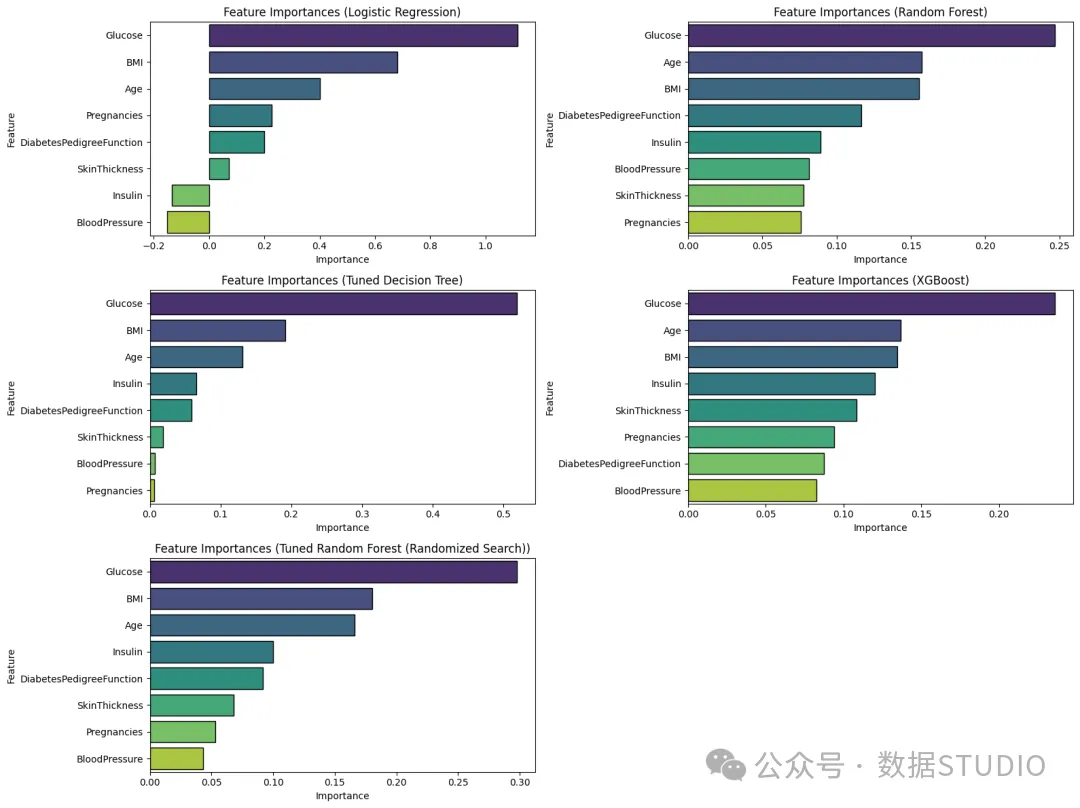 特征重要性
特征重要性
由此可以肯定的是:血糖是预测患者糖尿病的首要决定因素。BMI、年龄和胰岛素也是预测结果的关键属性。
测试一下:
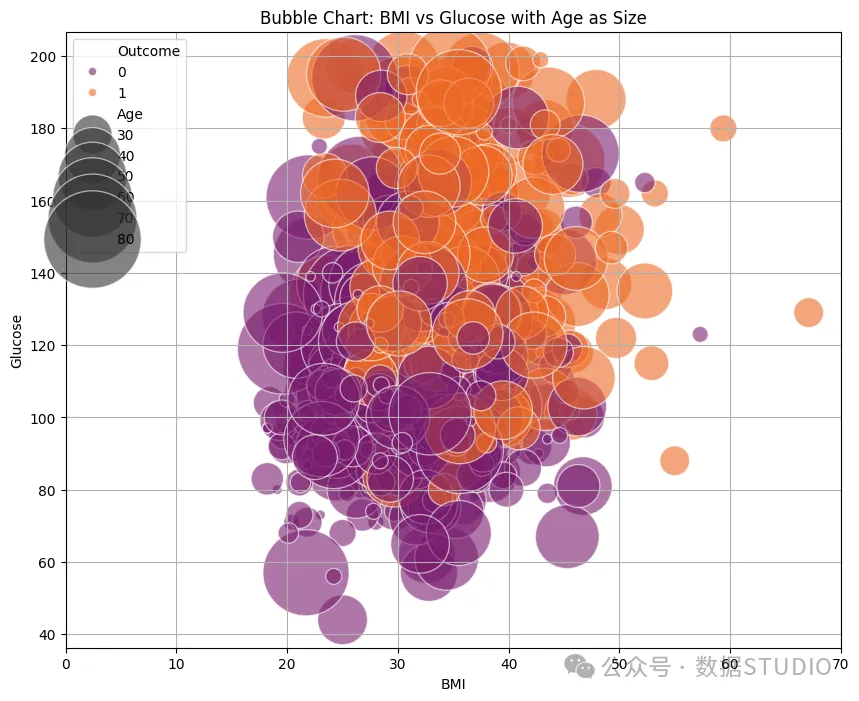 特征气泡图
特征气泡图
你看到这张气泡图了吗?它告诉我们,在血糖和BMI水平较高时,有一簇大的橙色气泡(结果 = 1),这表明BMI和血糖值较高的老年人更有可能获得积极的结果。你会注意到,许多大的紫色圆圈位于血糖轴的下方。这意味着他们可能年龄较大、体重较重——但他们的血糖水平不高,所以他们不是糖尿病患者。
- 大橙色(上图) = 高 BMI + 高血糖 + 年龄较大 = 高风险
- 大紫色(下图) = 可能年纪大或 BMI 高,但血糖正常或有其他保护因素
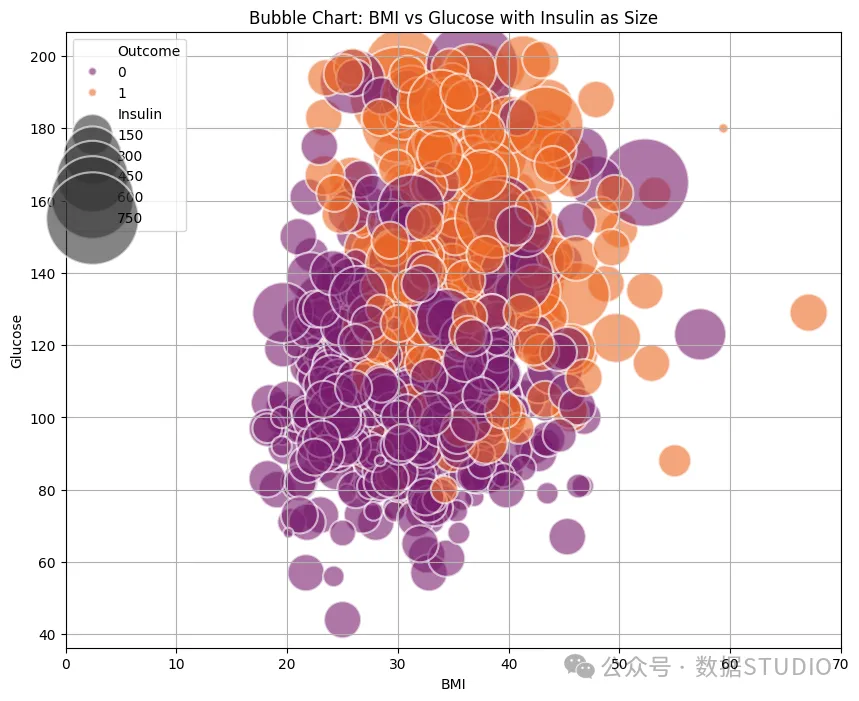 胰岛素抵抗气泡图
胰岛素抵抗气泡图
最上象限的圆圈大多巨大且呈橙色。这告诉我们,胰岛素抵抗和血糖升高(见上图)的情况不容乐观。这几乎肯定会导致糖尿病,或者至少是定时炸弹。这里大多数负面结果的血糖和胰岛素水平都正常。
现在,令人瞠目结舌的事情发生了!因为我喜欢风险分析,所以我们喜欢用几率来衡量概率。我们建立了一个简单的风险评分系统,如果BMI > 30,则+1;如果血糖 > 140,则+1;如果年龄 > 40,则+1;如果胰岛素 > 150,则+1;如果怀孕次数 > 3,则+1。我们计算了每个分数对应的糖尿病发病率,并将其列在0-1范围内的热图上(根据符合的属性,分数越接近1,患者患糖尿病的风险就越大)。
复制# 将基于最重要特征的风险评分逻辑应用于 DataFrame
def calculate_risk_score ( row ):
score = 0 # 初始化为 0 并按条件递增
if row['BMI'] > 30:
score += 1
if row['Glucose'] > 140:
score += 1
if row['Age'] > 40:
score += 1
if row['Insulin'] > 150:
score += 1
if row['Pregnancies'] > 3:
score += 1
return score
df['RiskScore'] = df.apply(calculate_risk_score, axis=1)
# 计算每个风险评分的糖尿病发病率
risk_diabetes_rate = df.groupby('RiskScore')['Outcome'].mean().reset_index()
# 创建热图
plt.figure(figsize=(10, 6))
sns.heatmap(risk_diabetes_rate.set_index('RiskScore').T, annot=True, cmap='Reds', fmt=".2f", linewidths=.5)
plt.title('Diabetes Rate vs. Risk Score Heatmap')
plt.xlabel('Risk Score')
plt.ylabel('Outcome (1=Diabetes)')
plt.yticks([]) # 隐藏 y 轴标签,因为它只有'结果 (1=糖尿病)'
plt.show()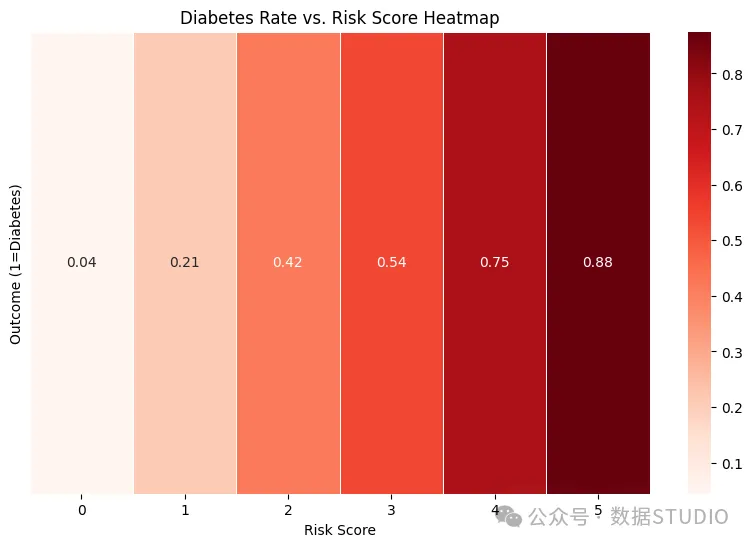 风险评分热图
风险评分热图
即使只超过 3 个阈值,患者也或多或少有可能患有糖尿病。超过 4 个阈值是一个巨大的灾难性危险信号,我们希望迅速找到干预措施,而超过 5 个阈值几乎肯定是糖尿病
测试虚拟数据
我们将一个虚拟数据集传递给模型,以测试该患者是阳性还是阴性。我们将数据以数组的形式传递,顺序与数据字典中的顺序相同,然后缩放数据,使用部署的模型执行预测,并评估两种结果的确定性概率。请看下面的代码:
复制# 示例患者数据作为 NumPy 数组
# 确保特征的顺序与训练数据匹配
# 训练数据 (X) 中的特征为:
# ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
# 示例患者数据(用实际患者数据替换)
# 这只是一个包含 8 个值的占位符数组。
# 您需要在此处提供实际患者数据。
patient_data_array = np.array([[ 2 , 130 , 70 , 30 , 128 , 35.0 , 0.82 , 43 ]])
# 使用与训练数据相同的缩放器缩放患者数据
scaled_patient_data = scaler.transform(patient_data_array)
# 使用随机搜索模型执行预测
prediction = best_tree_model.predict(scaled_patient_data)
# 预测结果是一个 numpy 数组,访问第一个元素
prediction_result = prediction[ 0 ]
# 解释预测
if prediction_result == 1:
print("Prediction: The patient is likely to have diabetes.")
else:
print("Prediction: The patient is likely not to have diabetes.")
# 获取每个类的概率
prediction_proba = best_rs_forest_model.predict_proba(scaled_patient_data)
print(f"Probability of no diabetes (Class 0): {prediction_proba[0][0]:.4f}")
print(f"Probability of diabetes (Class 1): {prediction_proba[0][1]:.4f}") 根据虚拟数据进行预测
根据虚拟数据进行预测
预计这位患者最有可能患有糖尿病——我叫她 Anaya
这是一个显示 Anaya 的用户资料及其病史的仪表板
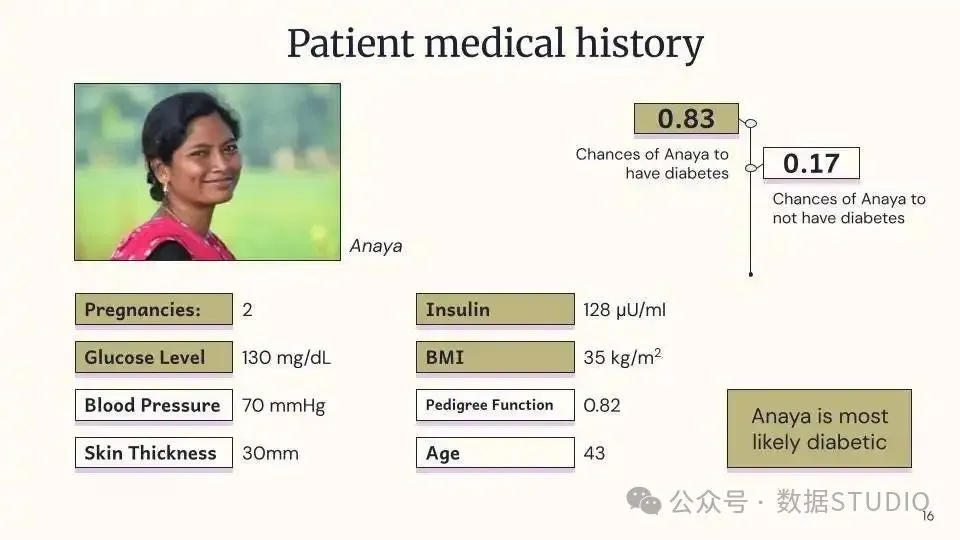 anaya 的个人资料
anaya 的个人资料
我们还做了一个交互式的,要求用户输入。我们收集了用户(例如患者)的医疗输入,对输入进行预处理,使其与经过训练的机器学习模型(例如本例中的 KNN)使用的格式相匹配,预测患者是否可能患有糖尿病,并显示结果的概率和解释。
我们利用 try-except 验证块来确保数据float仅在数据类型中被接受并附加到列表数组中patient_data
复制# 本项目的数据集和代码获取:@公众号:数据STUDIO 原文《机器学习实战:糖尿病预测分析及可视化》 文末打赏任意金额便可获取
# 允许用户输入进行预测
def get_patient_input ():
"""从用户那里获取患者属性作为输入并进行验证。"""
feature_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
patient_data = []
print("Please enter the patient's details:")
for feature in feature_names:
whileTrue:
try:
value = float(input(f"Enter {feature}: "))
# 添加基本验证(例如,非负值)
if feature in ['Pregnancies', 'Age'] and value < 0:
print("Value cannot be negative. Please enter again.")
continue
if feature in ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI'] and value < 0:
print("Value cannot be negative. Please enter again.")
continue
if feature == 'DiabetesPedigreeFunction'and value < 0:
print("Value cannot be negative. Please enter again.")
continue
patient_data.append(value)
break# 如果输入有效,则退出循环
except ValueError:
print("Invalid input. Please enter a numerical value.")
except Exception as e:
print(f"An error occurred: {e}"))
return np.array([patient_data])
# 从用户那里获取输入
user_patient_data = get_patient_input()
# 使用在训练数据上适合的相同缩放器缩放用户输入数据
scaled_user_data = scaler。transform(user_patient_data)
user_prediction = knn.predict(scaled_user_data)
# 解释预测
user_prediction_result = user_prediction[ 0 ]
if user_prediction_result == 1:
print("\nPrediction: Based on the input data, the patient is likely to have diabetes.")
else:
print("\nPrediction: Based on the input data, the patient is likely not to have diabetes.")
print("\nPrediction: Based on the input data, the patient is likely not to have diabetes.")
# 获取每个类的概率
user_prediction_proba = knn.predict_proba(scaled_user_data)
print(f"Probability of no diabetes (Class 0): {user_prediction_proba[0][0]:.4f}")
print(f"Probability of diabetes (Class 1): {user_prediction_proba[0][1]:.4f}")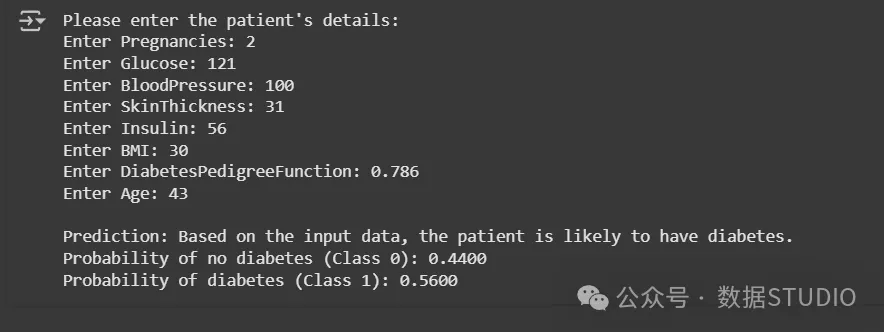 用户输入——预测
用户输入——预测
在这里,你可以看到,即使它预测患者可能患有糖尿病,也并不像第一个例子那样确定。所以,谁知道呢?这可能是假阳性(也可能不是)。
当我们继续探索健康与机器学习的交集时,记住:每个数据点不仅仅是一个统计数据;它代表着一个人类的故事。