本文第一作者卫雅珂为中国人民大学四年级博士生,主要研究方向为多模态学习机制、多模态大模型等,师从胡迪副教授。作者来自于中国人民大学和上海人工智能实验室。
近年来,多模态大模型(MLLMs)已经在视觉语言、音频语言等任务上取得了巨大进展。然而,当在多模态下游任务进行微调时,当前主流的多模态微调方法大多直接沿用了在纯文本大语言模型(LLMs)上发展出的微调策略,比如 LoRA。但这种「照搬」 策略,真的适用于多模态模型吗?
来自中国人民大学高瓴人工智能学院 GeWu-Lab 实验室、上海人工智能实验室的研究团队在最新论文中给出了一种全新的思考方式。他们指出:当下 MLLMs 微调方案大多简单的将单模态策略迁移至多模态场景,未结合多模态学习特性进行深入思考。事实上,在多模态场景中,单模态信息的独立建模(Unimodal Adaptation)和模态之间的交互建模(Cross-modal Adaptation)是同等重要的,但当前的微调范式往往没有关注思考这两个重要因素,导致对单模态信息的充分利用及跨模态充分交互存在较大局限性。
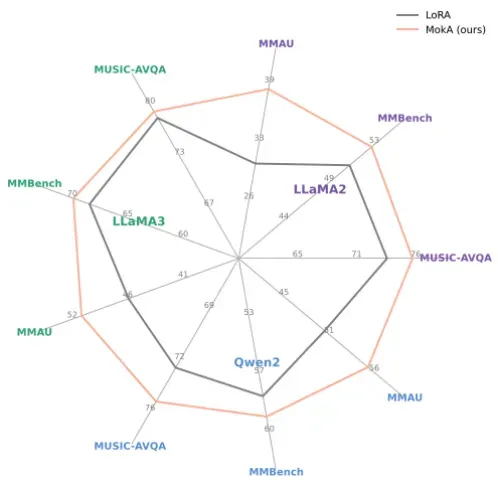
为此,研究团队充分结合多模态场景的学习特性,提出了 MokA(Multimodal low-rank Adaptation)方法,在参数高效微调背景下对单模态信息的独立建模和模态之间的交互建模进行了并重考量。实验覆盖音频 - 视觉 - 文本、视觉 - 文本、语音 - 文本三大代表性场景,并在 LLaMA、Qwen 等主流 LLM 基座上进行了系统评估。结果显示,MokA 在多个 benchmark 上显著提升了任务表现。

- 论文链接:https://arxiv.org/abs/2506.05191
- 项目主页:https://gewu-lab.github.io/MokA
多基座、多场景下均实现性能提升
当下被忽略的模态特性
在本文中,研究团队指出当前多数高效多模态微调方法存在一个关键性限制:它们直接借鉴自单模态的大语言模型的设计。以 LoRA 为例,如下公式所示,在多模态场景中,直接应用 LoRA 将会使得同样的可学习参数 W 被用于同时处理和适配来自不同模态的输入 x。其中,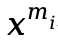 代表第 i 个模态的输入。
代表第 i 个模态的输入。
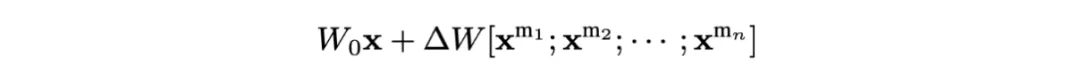
而在真实场景中,不同模态的信息存在异质性。因此,这种直接 “照搬” 单模态微调方法的实践忽视多模态场景中模态之间的本质差异,可能导致模型难以充分利用所有模态的信息。基于此研究团队提出,要高效地微调多模态大模型,单模态信息的独立建模(Unimodal Adaptation)和模态之间的交互建模(Cross-modal Adaptation)缺一不可:
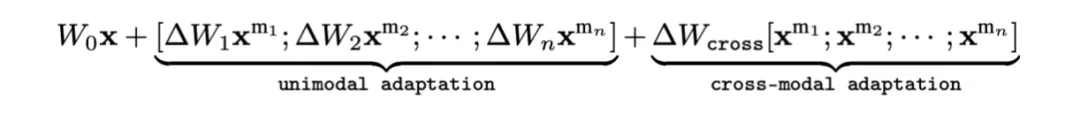
如上公式所示意,既需要单模态独有参数保证单模态信息适配不受其他模态干扰,同时也需要跨模态参数对模态间交互对齐进行适配建模。
MokA:关注模态特性的多模态微调方法
基于以上思想,研究团队提出了 MokA 方法,兼顾单模态信息的独立建模和模态之间的交互建模。
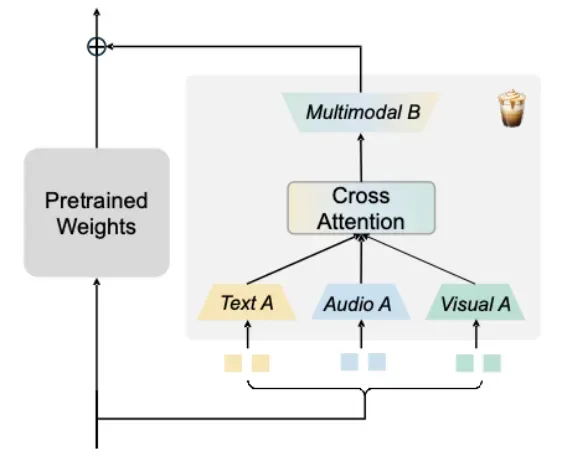
MokA 在结构上继承了 LoRA 的核心思想,以保持高效的优点。但基于多模态场景对于 A、B 投影矩阵的角色进行了重新定义。如上图所示,MokA 包括三个关键模块:模态特异的 A 矩阵,跨模态注意力机制和模态共享的 B 矩阵。
模态特异的 A 矩阵: MokA 考虑多模态场景,使用模态特异的 A 矩阵,从而可以在参数空间中保留模态独立性,确保每种模态的信息压缩过程不会互相干扰,是实现单模态信息独立建模的关键一步。
跨模态注意力机制:这一模块的主要目的是显式增强跨模态之间的交互。在进行 instruction tuning 时,通常文本信息包含了具体的问题或任务描述,而其他模态信息提供了回答问题的场景。因此,为了显式加强跨模态交互,MokA 在独立压缩后的低秩空间内对文本和非文本模态之间进行了跨模态建模,加强任务和场景间的关联关系。
模态共享的 B 矩阵:最后,在独立子空间中的各个模态被统一投影到一个共享空间中,利用一个共享的低秩矩阵 B 进行融合,以共享参数的方式进一步隐式实现跨模态对齐。
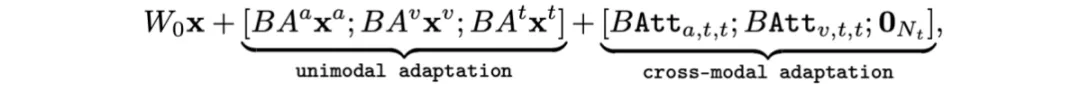
最终,MokA 的形式化表达如上所示。在多模态场景下,MokA 有效保证了对单模态信息的独立建模和模态之间的交互建模。
实验结果
实验在三个具有代表性的多模态任务场景上进行了评估,分别包括音频 - 视觉 - 文本、视觉 - 文本以及语音 - 文本。同时,在多个主流语言模型基座(如 LLaMA 系列与 Qwen 系列)上系统地验证了方法的适用性。结果表明,MokA 在多个标准评测数据集上均取得了显著的性能提升,展现出良好的通用性与有效性。
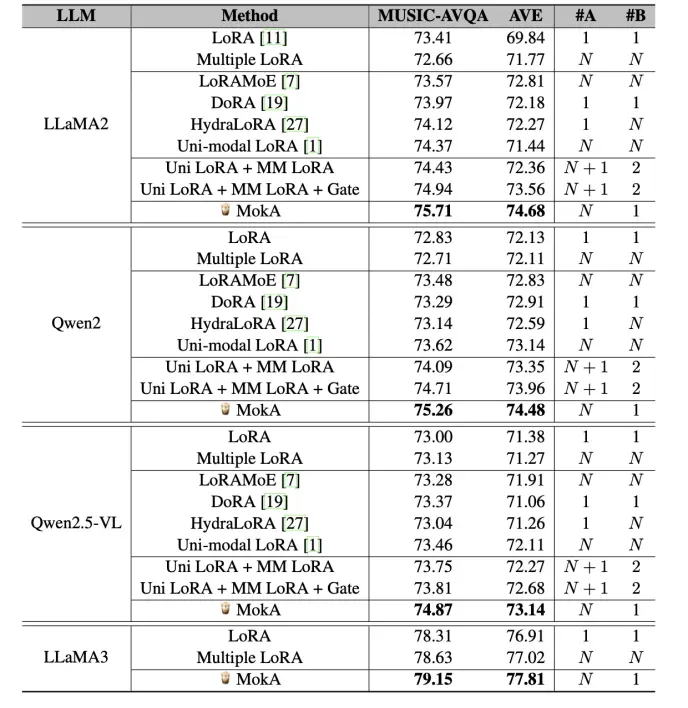
表 1: 在音频 - 视觉 - 文本的实验结果。
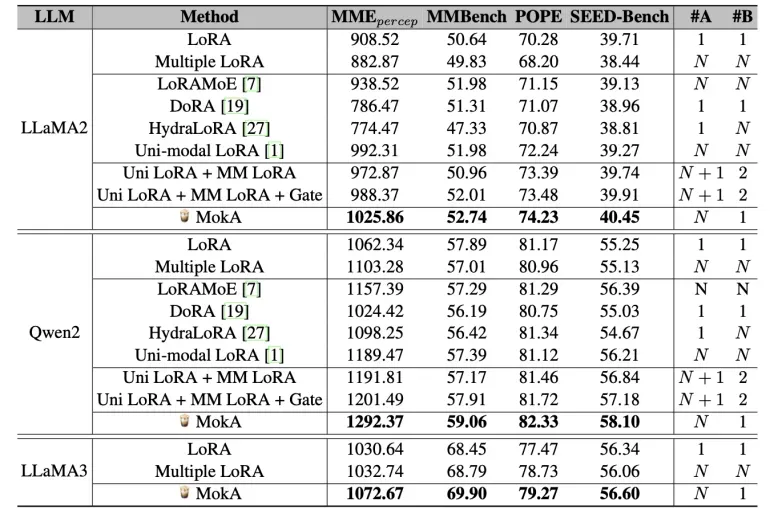
表 2: 在视觉 - 文本场景的实验结果。
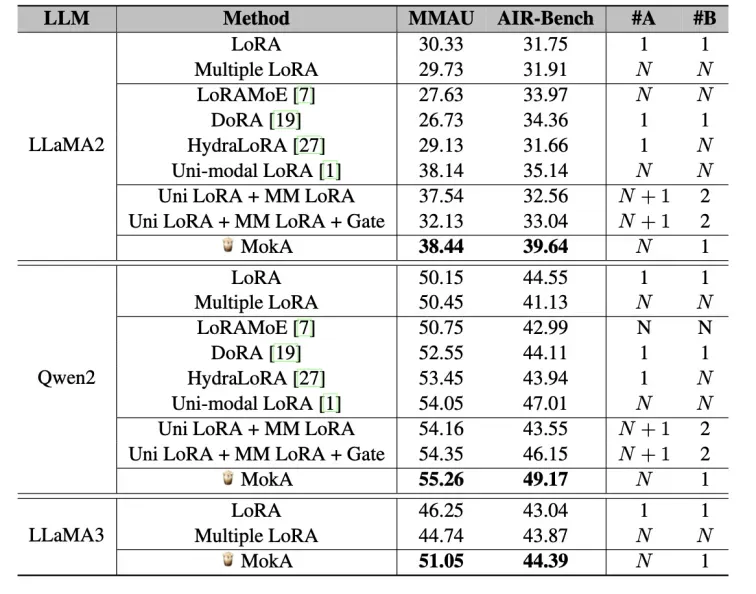
表 3:在语音 - 文本场景的实验结果。
总述
综上所述,MokA 作为一种面向多模态大模型的高效微调方法,兼顾了单模态特性建模与模态间交互建模的双重需求,克服了对模态差异性的忽视问题。在保留 LoRA 参数高效优势的基础上,MokA 通过模态特异 A 矩阵、跨模态注意力机制与共享 B 矩阵协同工作,实现了有效的多模态微调。实验验证表明,MokA 在多个任务和模型基座上均取得显著性能提升,展现适应性和推广潜力,为多模态大模型的微调范式提供了新的方向。