业界功能最全、消费级显卡可跑、而且还是开源的?!
不卖关子了,这就是阿里最新开源的通义万相Wan2.1-VACE,号称当前业界功能最全的视频生成与编辑模型。
有多全呢?来看官方介绍海报:
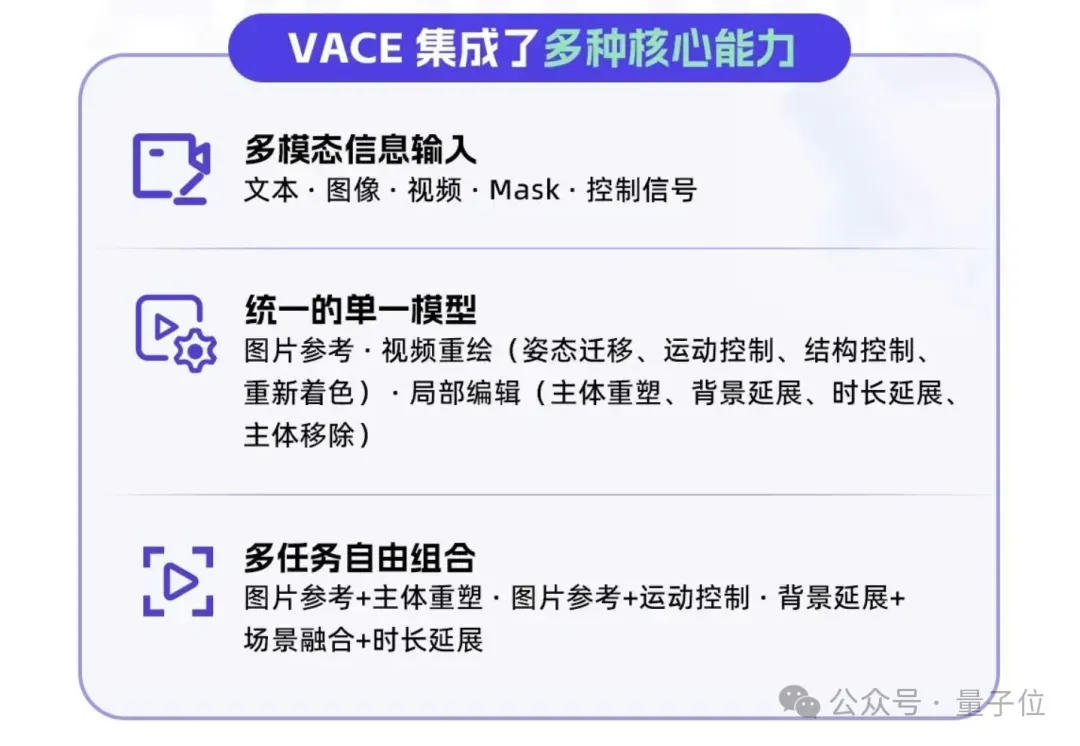
按照万相产品负责人的说法,“所有你能想到的关于视频生成的玩法,几乎都在这里了”。
而且与以往不同,以上功能主打“All in one”,都能在一个模型里体验。
目前Wan2.1-VACE一共有两个版本:
- 1.3B版本:消费级显卡可跑,支持480p分辨率;
- 14B版本:满血版,支持480p、720p分辨率。
模型已在GitHub、Hugging Face和魔搭社区上线,动手能力强的小伙伴现在可自行本地化部署,至于其他想在产品端直接体验的朋友,可能还要等一两天。
OK,话不多说,我们直接看新模型究竟有哪些玩法。
视频生成领域的“全能选手”
经过一番梳理,Wan2.1-VACE的“进阶攻略”如下:
- 初阶玩法:基础的文生视频、图生视频(含首尾帧)、视频生视频等;
- 中阶玩法:加入编辑功能,局部抹除或替换、视频重绘、时长或背景延展等;
- 高阶玩法:将各种能力花式组合。
下面我们依次挑其中的一些亮点来看。
首先,在初级阶段,Wan2.1-VACE根据参考图生成融合视频的能力看起来相当丝滑。
比如分别上传两张娃娃和小蛇的图片:

生成的视频如下,不仅还原了文字所描述的氛围感,而且娃娃和小蛇的动作姿态都比较自然,整体构图和谐。

提示词:在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。
当然也有官方demo中效果更惊艳的(游戏中的角色直接照进现实):

 除了融合能力,Wan2.1-VACE更值得说道的还是编辑功能。
除了融合能力,Wan2.1-VACE更值得说道的还是编辑功能。
要知道目前绝大多数视频生成AI都无法“一次就100%成功”,所以编辑功能几乎已成为刚需。
比如在产品宣传中,咱们直接来个“无中生有”。
第一步,直接使用文生视频创造出下列场景。

提示词:纪实摄影风格,房产自媒体博主站在一间现代化的客厅中央。博主穿着简洁时尚的衣物,面带微笑,两只手举在身前,手上空无一物正对着镜头介绍房屋情况。背景是一间宽敞明亮的客厅,家具简约现代,落地窗外是绿意盎然的花园。房间内光线充足,温馨舒适。中景全身人像,平视视角,轻微的运动感,如手指轻点屏幕。
第二步,给产品绘制一块想要放置的区域。

最后一步,“凭空捏造”后的效果be like:

同时,Wan2.1-VAC也支持视频重绘,包括姿态迁移、运动控制、结构控制、重新着色等。
比如给一段球体落入水中的姿势视频:

整个过程就能完整迁移到真实物体和环境中:

此外,Wan2.1-VACE还支持对原视频进行画面扩展和时长扩展。

最终,如果将以上所有基础功能组合起来,我们就能用来花式整活了(doge)。
比如将竖图变成横图的同时,让蒙娜丽莎戴上可爱眼镜:

又或者给视频“一键换脸”:

更多网友实测
鉴于以上官方demo所展示的效果确实令人惊艳,更多网友也迫不及待地开启了实测。
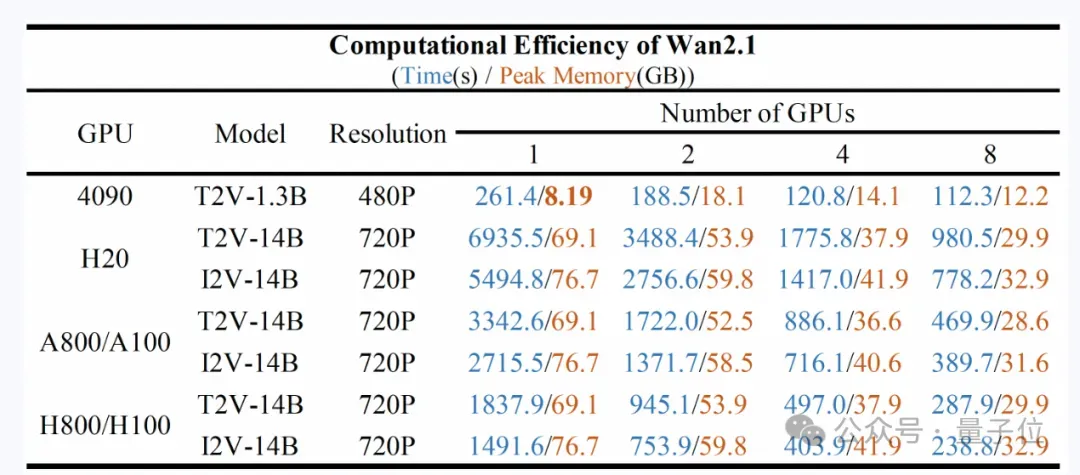
这里要补充一下,如果要进行本地部署,官方测试的模型在不同GPU上的计算效率如下:
OK,回到正题。
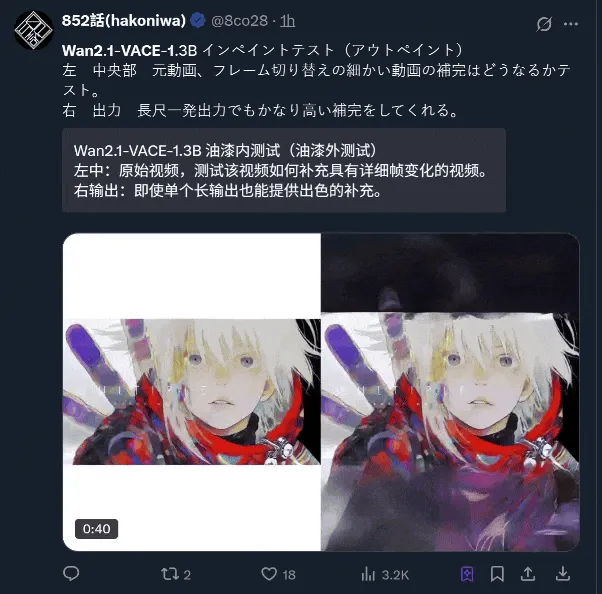
有网友尝试改变视频画幅比例(左边为原视频),结果其画面补充能力获得了认可。
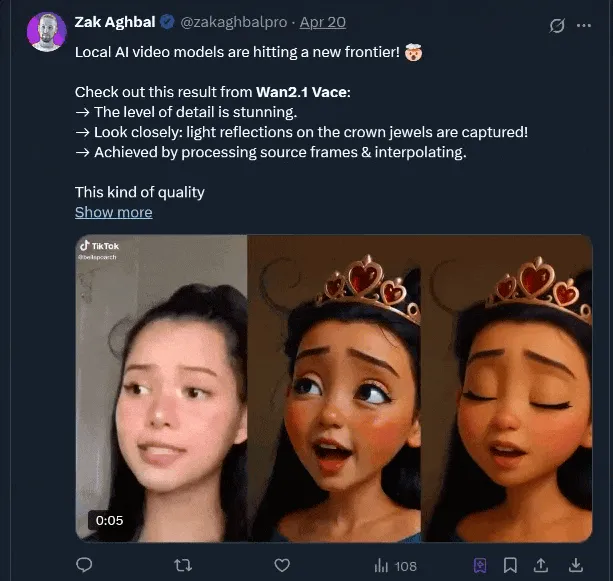
还有人尝试给一张参考图和视频,以实现人物姿势、面部表情迁移,结果其细节控制能力也收获了好评。
同样获得认可的还有其融合能力,看起来也和demo一样自然。

那么最后问题来了,其实际能力究竟如何呢?
想知道答案的朋友欢迎在评论区留言“想看”,没准咱们后续就安排一波实测(doge)~
GitHub:https://github.com/Wan-Video/Wan2.1魔搭:https://modelscope.cn/organization/Wan-AIHugging Face:https://huggingface.co/Wan-AI


