在多模态大模型的飞速发展中,R1 系列多模态推理模型凭借显式的长链推理机制,在复杂任务中屡屡突破传统「快思考」范式的性能瓶颈。
然而,研究发现,随着推理链条的加长,这类模型的视觉感知能力却呈现出明显下滑的趋势,逐渐转而依赖语言先验进行「脑补」,生成内容也越来越容易脱离图像本身,甚至出现凭空捏造的幻觉现象。
这一「推理增强—感知削弱」的悖论,凸显了当前多模态推理模型在推理能力与感知准确性之间面临的平衡挑战。
为进一步验证这一现象,来自加州大学圣克鲁兹分校、圣塔芭芭拉分校和斯坦福大学的研究团队开展了系统性分析。
通过引入推理长度控制机制与可解释性注意力可视化方法,研究者发现:随着推理链的延长,模型对图像内容的关注显著下降,而对语言提示的依赖不断增强,凸显出语言主导下的视觉偏离趋势。

论文链接:https://arxiv.org/pdf/2505.21523
项目链接:https://mlrm-halu.github.io
代码链接:https://github.com/MLRM-Halu/MLRM-Halu
在此基础上,团队提出了全新的评估指标RH-AUC,并构建了配套的诊断性基准集RH-Bench,首次系统量化了多模态推理模型在推理能力与视觉感知稳定性之间的平衡表现。
该工具不仅提升了模型幻觉风险的可测性,也为未来多模态系统的稳健性评估与改进提供了重要参考。
推理增强带来的视觉幻觉放大效应

在当前多模态大模型的演进中,R1 类推理模型因引入显式的长链语言推理过程(Reasoning Chain),在复杂任务上展现出强大的表达能力。


然而,研究人员系统性观察到一个被广泛忽视的现象:随着推理链长度的加深,模型在感知任务中的视觉对齐能力显著下降,幻觉风险随之放大。
这一趋势在多组实证对比中被清晰观察到。
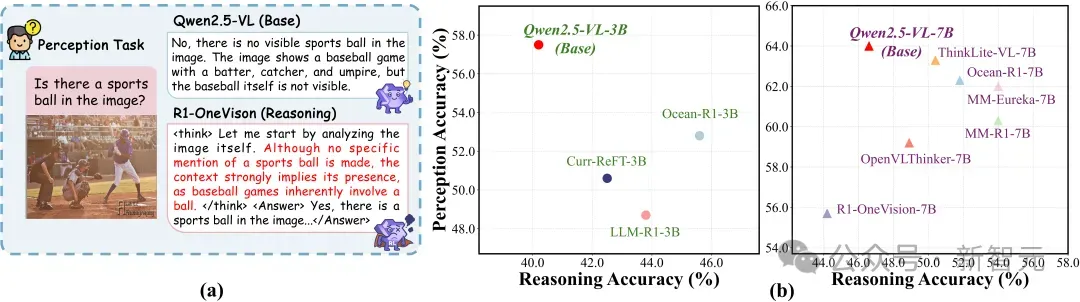
例如,在图 (b) 中,研究人员对比了多个 7B 规模的多模态模型在推理与感知两类任务中的表现:尽管 R1-OneVision-7B 等模型在推理准确率上具备一定优势,但其在感知任务中的准确率却降至最低,显著低于同规模的非推理模型(如Qwen2.5-VL-7B)。
这表明推理链的加深并非「无代价」的增强,而是以牺牲图像感知能力为代价,放大了幻觉。
具体来说,当模型在图文任务中逐步延展其语言链条时,原本应支撑答案的图像证据信号却被悄然边缘化。
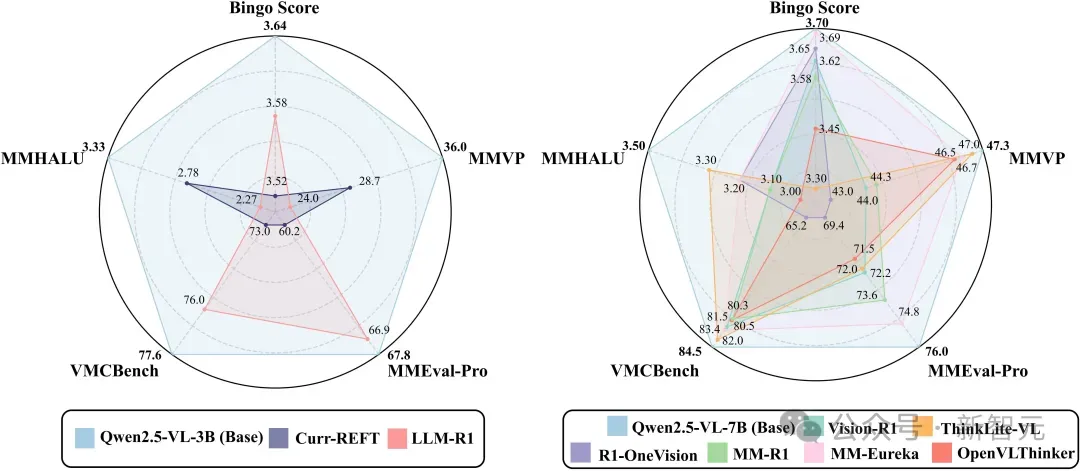
以典型视觉问答任务为例,在推理模型中生成的冗长输出往往并未真正参考图像内容,而是依赖语言常识「脑补」出一个听上去合理、但图像中并不存在的答案。这种现象在多个感知评测基准(如MMVP、MMHAL)中反复出现。
如图所示,在多个视觉感知任务的综合评估中,R1类模型普遍低于同规模的Base模型,尤其在需要细致图像对齐能力的MMHAL和MMVP上,差距更为显著。
这进一步印证了:推理链的增强不仅没有提升感知质量,反而加剧了模型「脱图而答」的幻觉倾向。
综上,推理链的增强并非无代价,「更聪明」的推理模型在感知类任务上反而可能「看得更少」。
越「聪明」越容易出错?

为了深入理解多模态推理模型为何更容易产生幻觉,研究团队对模型内部的注意力分布进行了系统分析,揭示出一种结构性机制:推理增强并非免费午餐,它以牺牲视觉关注为代价换取语言推理能力的提升。
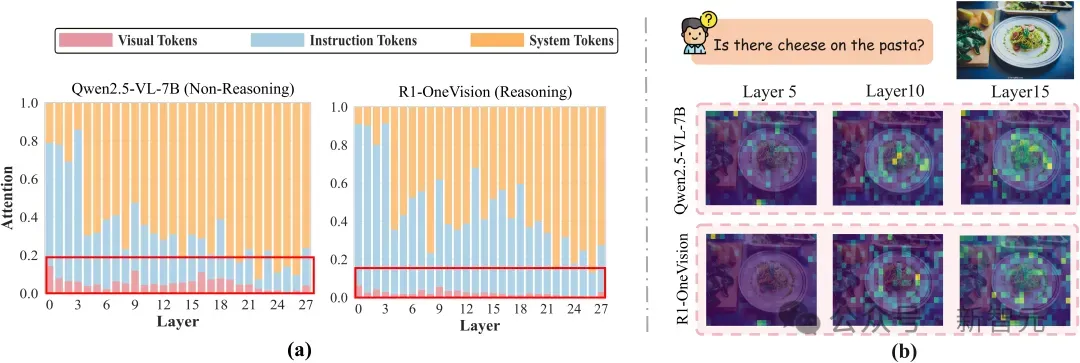
具体来说,相较于非推理模型,R1类推理模型在生成过程中显著减少了对视觉token的关注,取而代之的是将大量注意力分配给指令token与语言上下文(图a)。
更为关键的是,这种「注意力迁移」并非固定偏差,而是随着推理链条的延展而逐层加剧——越往后层,模型越倾向于忽略图像输入,而完全依赖语言信号进行推理。
如图 (b) 所示,在视觉聚焦任务中,非推理模型(Qwen2.5-VL)在多层均展现出对图中关键区域(如奶酪)的稳定关注;而R1模型(R1-OneVision)在同样问题下,其注意力热图呈现出明显的视觉退化,深层几乎完全失焦。
这种结构性偏移使得模型即使面对明确依赖图像的问题,也往往「凭语言猜」,最终生成与图像严重脱节的幻觉答案。
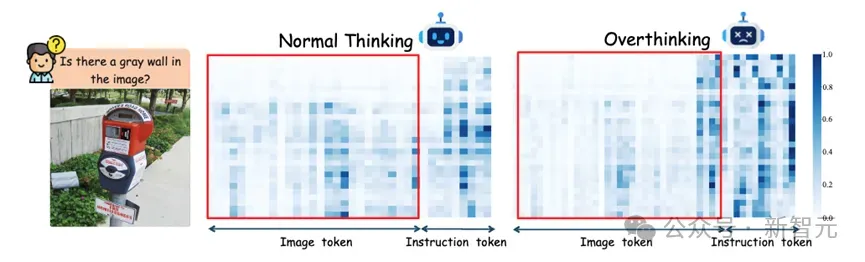
不仅如此,研究发现这一现象在模型进入「过度思考」(Overthinking)阶段时表现得尤为明显。
随着推理链的延长,模型对视觉token的关注持续减弱,而对指令等语言token的注意力则显著增强,导致生成过程越来越依赖语言线索而非图像内容。
推理链「长度悖论」:思考越多,幻觉越大?

模型推理链条的长短,真的越长越好吗?研究团队对比了三种不同的推理长度控制策略在多个基准测试中(Token Budget Forcing、Test-Time Scaling与Latent State Steering),首次系统揭示了一个关键现象:推理链条的长度与模型表现之间,呈现出非单调的「倒U型」关系。
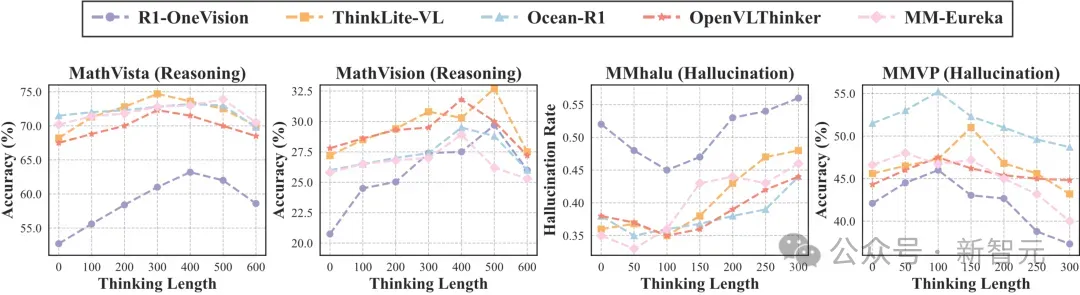
如图所示,在以推理为主的任务中(左两图),模型准确率先随推理链延长而提升,但当链条过长后反而回落,说明「过度思考」并不一定带来更强的reasoning能力。
而在以感知为主的任务中(右两图),随着推理长度的增加,幻觉率则持续上升,表明冗余语言生成会系统性干扰视觉对齐。
这一趋势强调:合理控制推理长度,是提升模型稳健性与感知–推理平衡能力的关键。
RH-AUC等指标的引入,也为这一非线性关系提供了更具解释力的定量刻画。
RH-AUC:推理与幻觉的动态权衡评估
面对多模态模型中推理增强与幻觉放大的两难局面,研究团队提出了一项全新评估指标:RH-AUC(Reasoning-Hallucination Area Under Curve)。
不同于传统指标只在单一推理长度上评估准确率或幻觉率,RH-AUC从整体视角出发,衡量模型在不同推理深度下「思考力」与「看清力」的动态平衡水平。
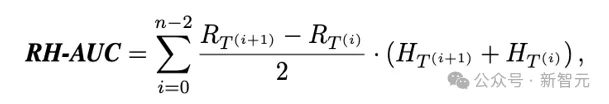
具体做法是:在新构建的RH-Bench数据集中(包含1000个跨感知与推理的样本),分别统计模型在不同推理长度下的reasoning accuracy与hallucination risk,然后计算两者构成曲线下的面积。
RH-AUC越高,说明模型在推理增强的同时,视觉对齐能力保持得越好——既能「想得深」,也能「看得清」。
实验结果揭示出三个关键趋势:
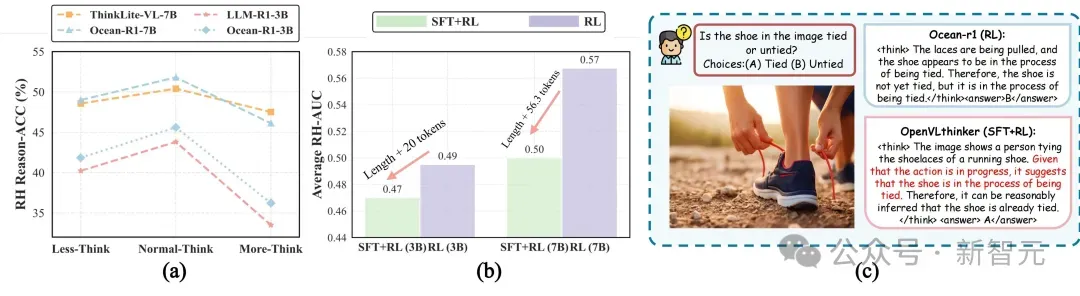
1. 更大规模模型更具稳健性:如图 (a) 所示,7B 模型在不同思考深度下展现出更平滑的 RH-AUC 曲线,并在峰值处取得更高分数,说明其具备更强的推理–感知整合能力。
2. RL-only 训练范式优于SFT+RL:如图 (b) 所示,在不同训练策略下,纯RL训练的模型平均 RH-AUC 均高于混合范式,尤其在长推理链条件下差距显著(0.57vs0.50)。
这表明RL-only更倾向于自适应生成高质量的推理路径,而SFT+RL更容易陷入冗余模仿,从而干扰感知判断。
3. 数据「类型」比规模更重要:实验发现,与其盲目扩展训练集规模,不如引入少量具备领域感知特征的样本(如数学推理或图像感知任务),更有助于引导模型在「看图」与「思考」之间实现平衡。
RH-AUC不仅填补了评估维度上的空白,也为未来多模态模型的训练目标提供了更明确的参考方向:推理不是越多越好,保持在「看见图像」与「想通问题」之间的张力,才是更优范式。


