VideoMamba
CNN、Transformer、Uniformer之外,我们终于有了更高效的视频理解技术
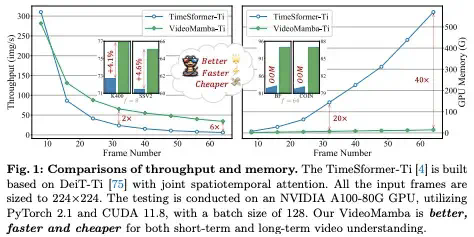
视频理解因大量时空冗余和复杂时空依赖,同时克服两个问题难度巨大,CNN 和 Transformer 及 Uniformer 都难以胜任,Mamba 是个好思路,让我们看看本文是如何创造视频理解的 VideoMamba。视频理解的核心目标在于对时空表示的把握,这存在两个巨大挑战:短视频片段存在大量时空冗余和复杂的时空依赖关系。尽管曾经占主导地位的三维卷积神经网络 (CNN) 和视频 Transformer 通过利用局部卷积或长距离注意力有效地应对其中之一的挑战,但它们在同时解决这两个挑战方面存在不足。UniForme
3/25/2024 11:19:00 AM
机器之心
- 1
资讯热榜
Cursor宣布免费向学生开放一年Pro会员,助力AI编程教育
大BUG!非学生用户竟能白嫖谷歌顶级AI全家桶 白嫖攻略速看
看不懂新开源的DS-Prover V2版本?解读来了,攻克像人类一样数学证明,达到SoTA水平,不知道如何测?样题来了
Midjourney V7推出全新功能 “Omni-Reference”,让图像生成更灵活
保姆级教程:零代码基础也能微调Qwen3,并本地部署
GPT-4o生成的烂自拍,反而比我们更真实
英伟达全新开源自动语音识别模型 Parakeet-TDT-0.6B-V2,语音转录能力再提升
DeepSeek-Prover-V2 登场:AI 数学推理新王者,88.9% 通过率设新标杆
标签云
人工智能
OpenAI
AI
AIGC
ChatGPT
AI绘画
DeepSeek
模型
数据
机器人
谷歌
大模型
Midjourney
智能
用户
开源
学习
微软
GPT
Meta
图像
AI创作
技术
论文
Gemini
马斯克
Stable Diffusion
算法
蛋白质
芯片
代码
生成式
英伟达
腾讯
神经网络
研究
Anthropic
计算
3D
Sora
机器学习
AI for Science
AI设计
开发者
GPU
AI视频
华为
场景
人形机器人
预测
百度
苹果
伟达
Transformer
深度学习
Claude
xAI
模态
大语言模型
字节跳动
搜索
驾驶
具身智能
神器推荐
文本
LLaMA
Copilot
视觉
训练
算力
安全
视频生成
干货合集
应用
智能体
亚马逊
科技
大型语言模型
AGI
DeepMind