
大家好,我是肆〇柒。今天,我要和大家聊一篇极具创新性的论文 ——《ALITA: GENERALIST AGENT ENABLING SCALABLE AGENTIC REASONING WITH MINIMAL PREDEFINITION AND MAXIMAL SELF-EVOLUTION》。该论文由普林斯顿大学、清华大学、上海交通大学等多所顶尖高校等机构提出。这些研究机构在人工智能领域都具有深厚的技术积累和广泛的研究影响力,它们的携手合作为我们带来了 Alita 这一突破性的通用智能体项目。
在AI领域,大型语言模型(LLM)经历了从单纯文本生成到能够自主规划和执行复杂任务的智能体的深刻演变。这些智能体,如旅行规划助手、Computer Use 智能体以及多步骤研究任务执行者等,能够以极小的人工监督为用户提供更智能的服务。它们的出现,标志着 AI 技术在处理复杂、开放性任务方面取得了重大突破,为各行各业带来了前所未有的机遇。
随着应用场景的不断拓展,人们逐渐发现,现有的通用智能体在应对多领域任务时存在诸多局限性。例如,它们往往依赖于大规模手动预定义的工具和工作流,这不仅导致系统复杂且难以维护,还限制了智能体的灵活性和泛化能力。此外,不同工具之间的接口不兼容问题也使得智能体难以无缝集成各种功能,增加了系统的不稳定性。这些问题迫切需要一种全新的设计范式来突破瓶颈,实现更高效、更智能的任务处理。
正所谓 “简洁是终极的复杂”。Alita 作为一种新型通用智能体,秉持极简预定义和极大自我进化的设计原则,为通用智能体领域带来了一场深刻思考。它摒弃了传统智能体对繁琐预定义工具和工作流的依赖,转而通过自主学习和动态能力扩展,在保持设计简洁性的同时,实现了强大的任务处理能力和广泛的适用性。Alita 的提出,不仅挑战了现有的通用智能体设计范式,还为大家带来启发,也许一个更加高效、灵活和智能的通用智能体时代即将到来。从下图可以看到,Alita 在性能上就体现了其优势,与 manus.ai 和 OpenAI DeepResearch 相比,有出色的表现。
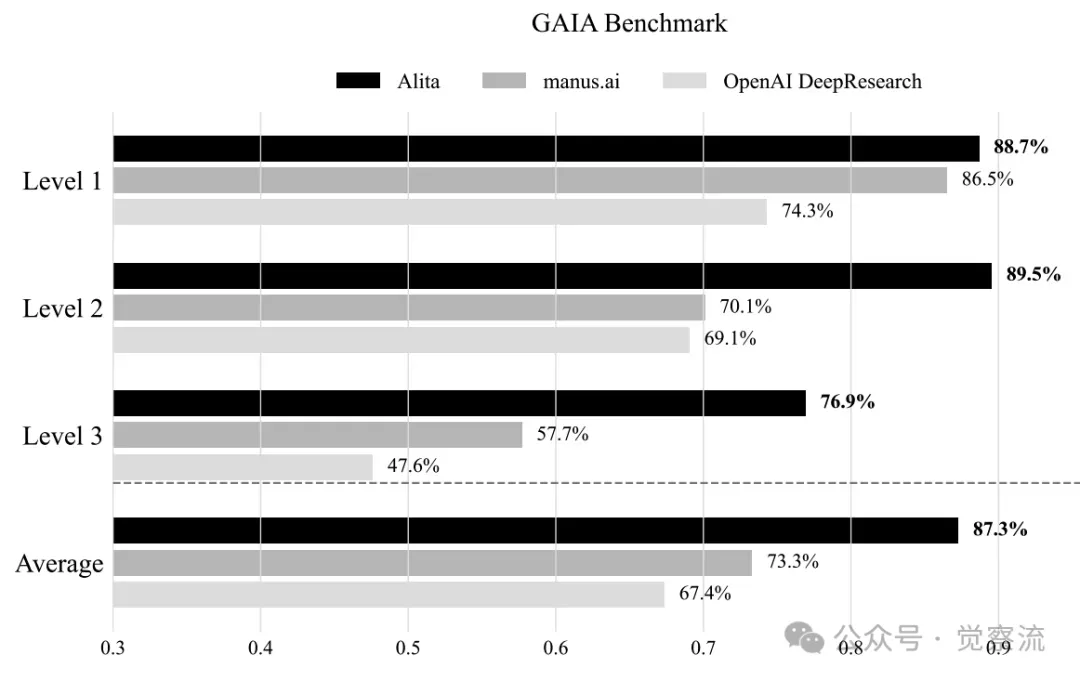
Alita 与 Manus.ai 以及 OpenAI Deep research 性能的对比
Alita 的设计理念:极简预定义与极大自我进化
摒弃繁杂:极简预定义,智能体架构的 “断舍离”
Alita 的设计严格遵循 “极简预定义” 原则,仅配备一个用于直接问题解决的核心组件 —— 网络智能体。这种高度精简的设计思路与传统智能体形成鲜明对比,后者往往依赖大量手工设计的工具和复杂工作流,不仅开发成本高昂,还因预定义工具的局限性难以适应新任务和环境变化。而 Alita 通过大幅减少预定义组件,有效降低了系统复杂性和维护成本,同时显著增强了其泛化能力,使其能够轻松应对各种任务场景,无需为每个特定任务单独定制工具和工作流。从 Figure 2 可以直观地看到,传统通用智能体依赖大规模手动工程构建预定义工具和工作流,而 Alita 剥离了这些繁琐的预定义部分,以简洁架构实现更广泛的任务适应性。
拥抱进化:极大自我进化,智能体动态成长密码
Alita 借助通用组件自主构建、优化和复用外部能力,实现可扩展的智能体推理,其核心在于通过从开源生成任务相关的模型上下文协议(MCP)。当面临新任务时,Alita 能够根据任务需求,动态地从开源资源中获取相关信息和工具,并将其转化为 MCP。这些 MCP 如同智能体的能力扩展模块,可被即时调用和执行,使 Alita 能够以灵活多变的方式应对各种复杂任务。从 Figure 2 可以看到,与传统智能体固定工具和工作流的模式不同,Alita 通过 MCP 创建实现动态能力扩展,打破传统智能体能力固定化的局限,赋予了 Alita 持续进化和自我提升的能力,使其在不断变化的任务环境中始终保持竞争力和适应性。这一机制让 Alita 能够在任务执行过程中,根据实际情况灵活调整和扩展自身能力,实现真正的自我进化。
平衡之道:于极简与进化间,智能体设计的黄金分割
Alita 的设计理念并非简单地追求简洁或进化,而是在两者之间找到了独特的平衡。极简预定义为智能体提供了稳定的基础架构,确保系统高效运行和易于维护;而极大自我进化则使智能体能够突破预定义的限制,动态适应各种复杂任务和环境变化。这种平衡使得 Alita 在保持简洁性的同时,具备了强大的任务处理能力和广泛的适用性。从下图的对比中可以清晰地看到,传统智能体由于过度依赖预定义工具和工作流,导致其在面对新任务时灵活性不足。
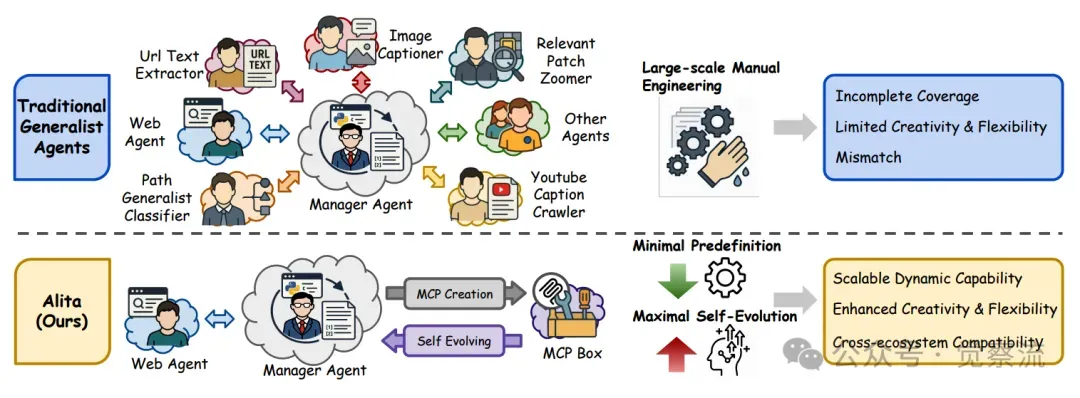
传统通用智能体与 Alita 的比较。传统通用智能体严重依赖大规模人工工程,而 Alita 坚持最小预定义和最大自我进化
而 Alita 通过极简设计与自我进化的结合,实现了敏捷的任务适应和高效的问题解决。这种平衡的设计理念,不仅提升了智能体的性能和适应性,还为通用智能体领域的发展提供了一种全新的思路和方向。
Alita 的架构与方法:全方位技术解读
架构概览:管理智能体与网络智能体的极简设计
Alita的框架由管理智能体和网络智能体构成,二者分工明确又紧密协作。管理智能体作为中央协调者,负责任务的整体规划和资源调配;网络智能体则专注于外部信息的检索和资源获取。在任务执行过程中,管理智能体根据任务需求调动网络智能体,网络智能体从外部获取必要的信息和工具,然后管理智能体对这些信息和工具进行整合和利用,最终完成任务目标。这种架构设计既保证了系统的高效运行,又使得各个组件能够专注于自身擅长的功能,提升了整体性能。下图直观地展示了 Alita 的架构,让我们能清晰地看到其各部分是如何协同工作的。
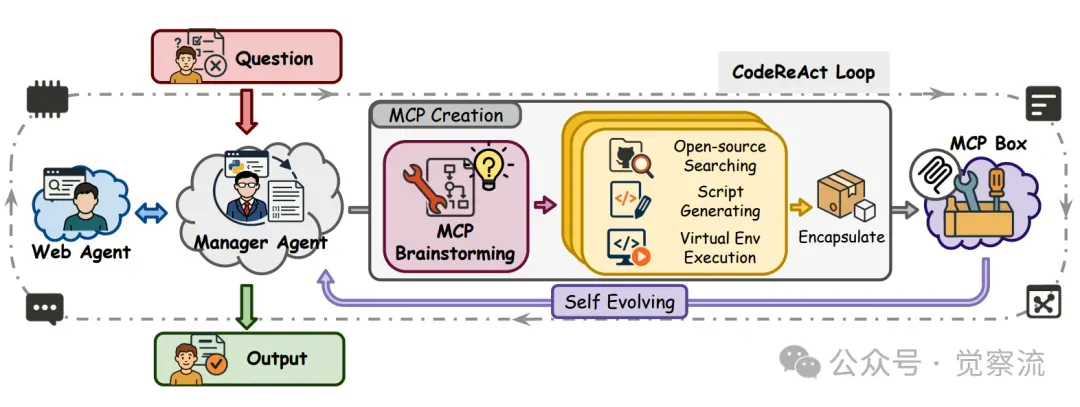
Alita 的架构。在收到问题后,Manager Agent 会启动一个迭代的 CodeReAct 循环来分析任务、识别功能缺口,并触发 MCP 头脑风暴进行综合创造。该系统动态地执行开源搜索、脚本生成以及虚拟环境执行,以构建与任务相关的功能。有用的被封装成可复用的 MCP 并存储在 MCP 沙盒中。在整个过程中,Manager Agent 与 Web Agent 合作以检索外部信息,并持续整合中间结果,直到产生最终输出。这一过程使得 Alita 能够在不依赖大量手工制作、复杂工具和工作流程的情况下自我进化
执行流程:任务处理的标准化
任务执行流程始于构建包含原始查询的增强型提示。管理智能体随后启动多步推理过程,涉及查询外部源、规划和合成新工具、在隔离环境执行等步骤。成功生成工具后,相应的脚本会被转化为MCP并存储起来,以便未来复用。当接收到任务时,管理智能体首先对任务进行初步分析,确定所需的信息和工具类型。然后,网络智能体根据指示从外部资源中检索相关信息,如开源代码库、文档等。接着,管理智能体利用检索到的信息生成新的工具或调整现有工具,以满足任务需求,并在一个安全的隔离环境中执行这些工具。执行结果经过验证后,相关的脚本和环境配置会被封装成MCP,存储在内部工具注册表中。这一流程确保了任务执行的高效性和安全性,同时通过MCP的生成和存储,实现了知识和能力的积累与复用。
管理智能体:智能体中的 “智慧大脑”
管理智能体在接收任务提示后,首先调用MCP群思来评估智能体当前的能力是否足以完成任务。若发现能力不足,则确定所需补充的具体工具类型和功能。随后,管理智能体将任务分解为多个子任务,并将这些子任务分配给网络智能体或生成所需的外部工具来完成。在必要时,管理智能体利用网络智能体检索到的信息生成新的工具及其对应的环境配置指令。收集所有中间结果后,管理智能体进行最终的结果汇总和响应生成,将复杂的信息整合为简洁明了的答案呈现给用户。
管理智能体所使用的工具包简洁而强大,包括MCP群思、脚本生成工具和代码运行工具。MCP群思用于识别能力差距和规划工具生成;脚本生成工具根据任务需求创建定制化的工具;代码运行工具则在隔离环境中验证和执行脚本,确保生成的工具安全可靠。这些工具根据任务的动态需求智能调用,相互协作,共同推动任务的顺利进行。
网络智能体:智能体外部信息的 “抓手”
网络智能体在内部知识不足时发挥关键作用,通过检索外部信息来补充智能体的知识和能力。尤其在需要获取领域特定代码或文档的任务中,网络智能体能够快速定位和提取相关信息,为任务解决提供有力支持。
网络智能体配备了简单文本浏览器和页面级控制工具,如访问工具、页面上翻工具和页面下翻工具,以便在网页中导航和检索信息。此外,它还运用谷歌搜索工具和github搜索引擎工具,实现对开放网络和代码资源的高效搜索。这种设计使网络智能体能够实时获取代码片段和上下文信息,为工具规划和生成提供丰富的素材,确保智能体在面对复杂任务时能够迅速获取必要的资源和知识。
MCP 创建组件:智能体的 “创意工厂”
MCP群思通过提供任务和框架描述,对智能体的能力进行初步评估。当发现框架能力不足以完成任务时,它为工具生成提供具体参考,指导后续的任务规划和工具选择。这就好比在开始一项工程前,先进行详细的勘察和评估,确定所需的资源和设备类型,为后续施工打下坚实基础。
脚本生成工具根据子任务描述、代码构建建议以及网络智能体获取的GitHub链接等信息生成外部工具。它还生成环境脚本和清理脚本,确保生成的脚本具有有效性、独立性和可执行性。环境脚本负责搭建工具运行所需的环境,清理脚本则在任务完成后清理冗余文件和环境,避免资源浪费和系统污染。通过这种方式,脚本生成工具为任务执行提供了稳定可靠的运行环境,确保工具能够正常发挥作用。
代码运行工具在隔离环境中验证脚本功能。如果脚本执行成功并产生预期结果,则将其注册为可复用的MCP。这一过程不仅保证了脚本的质量和安全性,还支持迭代细化,允许对脚本进行错误检查和性能优化,不断提升其表现。这如同在产品出厂前进行严格的质量检测和优化,确保每个交付给用户的工具都具备高品质和高可靠性。
环境管理模块负责解析仓库或脚本元数据,提取依赖和设置指令,创建新的Conda环境并安装依赖。它确保了不同任务之间的环境隔离,避免了不同任务间的依赖冲突,提高了系统的兼容性和可移植性。在环境初始化失败时,环境管理模块会启动自动化恢复程序,尝试多种备用策略,如放宽版本约束或确定功能所需的最小依赖集。如果恢复尝试失败,则丢弃问题工具并记录失败信息,以便后续离线分析和改进。这种机制保证了系统的稳定性和健壮性,使智能体能够在复杂的任务环境中持续运行而不受影响。
对MCP创建关键技术细节的探讨
精准筛选 :信息筛选与工具评估
Alita 在从开源资源中获取信息和工具时,采用了一套 sophisticated 的信息筛选和工具评估机制。它首先利用基于机器学习的文本相似度计算方法,快速从海量开源资源中筛选出与任务描述具有高度相关性的候选工具。这一过程不仅考虑了工具的功能描述和关键词匹配,还结合了任务的上下文信息和历史任务数据,确保筛选出的工具在语义层面与当前任务紧密相关。
接下来,Alita 会进一步对候选工具进行评估,以确定其适用性和可靠性。评估指标包括工具的代码质量、社区反馈、使用频率以及与其他工具的兼容性等。通过一个多维度的评估模型,Alita 能够准确地量化每个候选工具的优势和局限性,从而为后续的工具选择提供有力依据。
流程精炼 :转化为 MCP 的关键步骤
将筛选后的工具转化为 MCP 的过程涉及多个关键步骤。首先,Alita 会根据任务需求和工具特性,定义一个标准化的封装格式,确保每个 MCP 都包含清晰的接口定义和输入输出参数说明。这一封装过程通过一套专门的适配器代码实现,能够将不同来源的工具统一转化为 Alita 可识别和调用的 MCP 格式。
然后,Alita 会自动生成与 LLM 的交互协议,定义 MCP 在任务执行过程中的调用逻辑和数据流动方式。这一协议不仅确保了 MCP 与 Alita 其他组件之间的无缝协作,还支持动态调整和优化,以适应不同任务场景的需求。
最后,Alita 会对转化后的 MCP 进行一系列的测试和验证,包括功能测试、性能测试和安全性测试等,确保其在实际应用中的可靠性和稳定性。通过这一严谨的流程,Alita 能够将开源工具高效地转化为具有高复用性和强适应性的 MCP,为智能体的动态能力扩展提供坚实的技术支持。
实验评估:彰显 Alita 卓越性能
实验设置
基准测试
GAIA基准测试是评估通用AI助手能力的重要工具,包含466个基于现实场景的问题,涵盖日常任务、科学推理、网页浏览和工具使用等多个领域。这些问题对人类来说概念简单,但对AI系统而言却极具挑战性,能够全面测试智能体在处理多样化任务时的性能和适应性。
Mathvista基准测试专注于评估基础模型在视觉语境中的数学推理能力,涉及视觉理解、数学推理、编程等多项技能。由于资源限制,实验中随机选取了100个样本进行测试。
Pathvqa基准测试是一个医学视觉问答数据集,能够评估智能体在视觉理解、空间推理、医学知识搜索或整合以及自然语言处理等多个维度的能力。同样由于资源限制,实验中也随机选取了100个样本进行测试。
基线比较
实验中选取了多种基线进行对比,包括Octotools、Open Deep Research-smolagents、AutoAgent、OWL、A-World和OpenAI Deep Research等。这些基线代表了当前通用智能体领域的不同设计思路和技术实现。例如,Octotools通过标准化工具卡片封装多种功能,赋予智能体处理多领域任务的强大能力;Open Deep Research则侧重于自动化多步骤研究任务,通过整合多样化在线信息生成综合性报告。通过与这些基线的比较,可以全面评估Alita的性能优势和创新之处。
实验结果
Alita在GAIA基准验证数据集上表现出色,以Claude-Sonnet-4和GPT-4o为模型配置时,取得了75.15% pass@1和87.27% pass@3的最佳性能,超越了其他复杂度更高的智能体系统。下表展示了 Alita 和其他基线智能体系统在 GAIA、Mathvista 和 PathVQA 基准测试中的性能比较,从中可以看到 Alita 在不同难度级别上的优势。
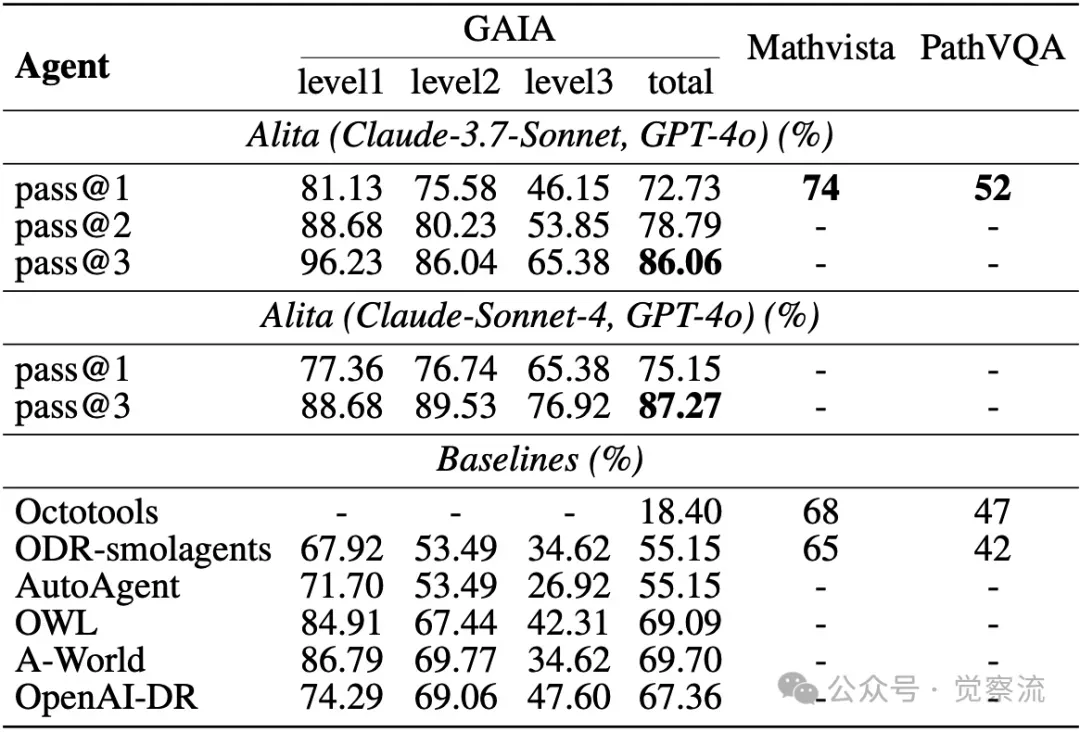
在GAIA、Mathvista和PathVQA基准测试中,Alita和基线智能体系统的性能对比。ODR-Smolagents指的是Smolagents框架中的 Open Deep Research Agent。OpenAI-DR指的是OpenAI的Deep Research。表格展示了GAIA在不同难度级别上的准确率,以及在Mathvista和PathVQA上的整体性能。Pass@1、pass@2和pass@3分别表示运行Alita框架1次、2次和3次所达到的准确率,并从中选择最佳答案。Alita在GAIA的所有级别上都优于所有基线智能体,实现了最高的总准确率在使用Claude 3.7 Sonnet + GPT-4o配置时,Alita在GAIA上的pass@1准确率为72.73%,在Mathvista上达到74.00%,在PathVQA上达到52.00%,全面优于多个基线系统。
在GAIA的不同难度级别上,Alita的性能表现也十分优异。例如,在Level 1任务中,Alita的pass@1准确率达到81.13%,pass@3准确率高达96.23%;在难度更高的Level 3任务中,pass@1准确率仍能达到46.15%,pass@3准确率为65.38%。相较于基线系统如Octotools在Level 1的18.40% pass@1准确率、Open Deep Research-smolagents在Level 3的34.62% pass@1准确率等,Alita的优势显而易见。这表明Alita不仅在简单任务中表现出色,在处理复杂任务时也能保持较高的准确率和稳定性,充分体现了其设计理念的先进性和有效性。
深度洞察:Alita 生成 MCP 的复用价值
Alita 生成的 MCP 的复用价值
复用Alita生成的MCP具有双重益处。一方面,这些MCP能够助力其他智能体框架提升性能。由于Alita通过试错法为GAIA等基准测试设计了一套实用的MCP,这些MCP可以直接被其他智能体框架使用,无需从头开始开发,从而节省了大量的开发时间和资源,提高了任务解决效率。另一方面,MCP复用可以视为一种新型的知识蒸馏方式。与传统的通过大型LLM生成的数据对小型LLM进行微调的知识蒸馏不同,MCP复用更加高效、低成本和快速。它将大型LLM中蕴含的高级知识和能力封装成MCP,直接传递给小型LLM智能体,使后者能够迅速获得处理复杂任务的能力,缩小了大小型LLM智能体之间的性能差距。
对 Open Deep Research-smolagents 的复用效果
实验数据显示,在GAIA的不同难度级别上,Open Deep Research-smolagents在使用Alita生成的MCP后性能显著提升。下表呈现了具体的提升数据,让这一结论更有说服力。

带有 Alita 生成的 MCP 和不带 Alita 生成的 MCP 的 ODR-smolagents 性能对比。结果在不同的GAIA级别上进行了报告:1级、2级、3级和平均值。每一列对应相应GAIA级别的性能。重复使用 Alita 生成的 MCP 可以提升其他智能体的性能例如,在Level 1任务中,pass@1准确率从33.96%提高到39.62%;在Level 2任务中,从29.07%提高到36.05%;在Level 3任务中,从11.54%提高到15.38%。这表明Alita生成的MCP不仅能够提升智能体在简单任务中的表现,还能在复杂任务中发挥重要作用,且在所有难度级别上均有改善,充分证明了MCP的通用实用性和对不同任务场景的良好适应性。
对小型 LLM 智能体的复用效果
以基于GPT-4o-mini的基础框架为例,使用Alita生成的MCP后,其在GAIA不同难度级别上的性能均显著提升。在Level 1任务中,pass@1准确率从32.08%提高到39.62%;在Level 2任务中,从20.93%提高到27.91%;在Level 3任务中,从3.85%大幅提高到11.54%。特别是在最具挑战性的Level 3任务中,准确率实现了三倍增长,凸显了MCP在复杂推理任务上的巨大价值。这说明MCP能够有效地将大型LLM的高级推理和问题解决能力传递给小型LLM智能体,弥补了后者在处理复杂任务时的能力不足,为资源有限的智能体提供了一种低成本、高效能的性能提升途径。下表直观地反映了这种提升效果。

在 GPT-4o-mini 基础框架上,有无 Alita 生成的 MCP 时的性能对比。结果在不同的 GAIA 层级(1级、2级、3级和平均值)进行了报告。每一列分别对应相应 GAIA 层级的性能表现。Alita 生成的 MCP 的复用显著提升了小规模 LLM 上智能体的性能
Alita 在小型 LLM 上的表现
对比Alita在Claude-3.7-Sonnet + GPT-4o和GPT-4o-mini模型配置下的GAIA表现,可以发现底层模型的编码能力对Alita的性能有着关键影响。下表则清晰地展示了不同模型配置下 Alita 的性能差异。

Alita(Claude-3.7-Sonnet,GPT-4o)与 Alita(GPT-4o-mini)的性能对比。结果在不同的 GAIA 级别进行了报告:一级、二级、三级以及平均值。每一列对应相应 GAIA 级别的性能。较小模型的整合显著降低了性能在Claude-3.7-Sonnet + GPT-4o配置下,Alita的pass@1准确率为72.73%,而在GPT-4o-mini配置下,这一数值下降到43.64%。这表明,尽管Alita的设计理念能够显著提升智能体的性能,但其底层模型的编码能力仍然是决定性能上限的重要因素。然而,随着LLM编码和推理能力的不断提升,Alita的性能也将持续增强。这预示着未来通用智能体的设计可能会向更极简的方向发展,人类开发者将更多地专注于设计能够激发智能体创造力和进化能力的模块,而非直接为每个任务预定义工具和工作流,从而推动智能体技术向更加智能化、自适应化的方向迈进。
案例研究:YouTube 360 VR 视频字幕提取
以GAIA中的一个Level 3难题——YouTube 360 VR视频字幕提取问题为例,我们可以详细剖析Alita的解决流程。Case Study 部分详细记录了这一过程,让我们能深入了解 Alita 如何基于任务进行结构化的 MCP 群思,并有效利用外部资源完成复杂任务。如下 Case Study: YouTube 360 VR Video Subtitle Extraction
复制Question ID: 0512426f-4d28-49f0-be77-06d05daec096 Question: In the YouTube 360 VR video from March 2018 narrated by the voice actor of Lord of the Rings’ Gollum, what number was mentioned by the narrator directly after dinosaurs were first shown in the video? Our Answer: 100000000 Correct Answer: 100000000 Is Correct: Yes Generated MCP: YouTube Video Subtitle Crawler Alita Workflow: 1. MCP Brainstorming: Alita propose the development of a "YouTube Video Subtitle Crawler" MCP, which should automate the extraction of subtitles from a given YouTube video. This involves scraping the subtitles of the video and processing them to isolate the relevant text after the event in question. 2. Web Agent Execution: To implement the subtitle extraction, a search is conducted in open-source repositories to find relevant tools that can assist in extracting YouTube video transcripts. An appropriate tool, the youtube-transcript- api, is identified from the following GitHub repository: https://github.com/jdepoix/youtube-transcript-api 3. Manager Agent: The Manager Agent synthesizes the information from the GitHub repository and proceeds to write a Python function that leverages the youtube-transcript-api to retrieve the transcript of the video with corresponding environment setup instructions. The environment setup and installation steps are defined as follows: conda create -n youtube_transcript conda activate youtube_transcript pip install youtube-transcript-api The Python code to retrieve the video transcript is as follows: from youtube_transcript_api import YouTubeTranscriptApi # Initialize the API ytt_api = YouTubeTranscriptApi() # Retrieve the transcript video_id = ... transcript_list = ytt_api.list(’video_id’) ... 4. Manager Agent Execution: Leveraging the Python code and the established environment, the Manager Agent successfully packaged the YouTube Video Subtitle Crawler MCP. Subsequently, this MCP was employed to efficiently scrape the subtitles from the video, enabling the extraction of the relevant content. After analyzing the content, the correct number (100000000) mentioned by the narrator following the dinosaur scene is extracted from the transcript. 5. Final Output: The number "100000000" is identified as the correct answer.
任务要求从2018年3月由《指环王》中咕噜姆配音演员叙述的YouTube 360 VR视频中,提取出在恐龙首次出现后叙述者提到的数字。Alita首先通过MCP群思提出开发“YouTube视频字幕爬取器”的想法,明确该MCP需要从给定的YouTube视频中自动提取字幕,并处理文本以定位相关事件后的文本内容。接着,网络智能体执行任务,在开源代码库中搜索相关工具,并找到了youtube-transcript-api这一合适工具。管理智能体随后整合信息,编写了一个Python函数,利用youtube-transcript-api获取视频字幕,并提供了相应的环境设置指令。通过在建立的环境中运行该Python代码,成功爬取视频字幕,并从中提取出正确的数字“100000000”。这一案例直观地展示了Alita如何基于任务进行结构化的MCP群思,并有效利用外部资源完成复杂任务,体现了其设计理念在实际应用中的强大威力和高效性。
局限性与未来展望
Alita 的短板:局限性分析
尽管Alita在多个基准测试中表现出色,但它对LLM编码能力的高度依赖也带来了一定的局限性。当LLM的编码能力较弱时,Alita的性能可能不如传统通用智能体。例如,在使用编码能力较弱的LLM时,Alita生成的工具可能不够准确或高效,导致任务执行失败或结果不理想。此外,Alita生成的MCP可能存在过拟合问题,即在特定数据集或任务类型上表现良好,但在其他场景中难以泛化。这限制了Alita在更广泛领域的应用和推广。
未来展望:智能体设计新思考
随着 LLM 编码和推理能力的不断提升,Alita 的性能有望进一步增强。未来通用智能体的设计可能会更加注重激发智能体的创造力和自我进化能力,而非依赖大量预定义的工具和工作流。人类开发者可以将更多精力放在设计能够促进智能体自主学习和动态适应的模块上,使智能体能够根据任务需求自动调整和优化自身能力。同时,MCP 作为一种有效的知识封装和传递机制,将在智能体之间实现更广泛的知识共享和能力复用,推动整个通用智能体领域的快速发展。
总结与感想
Alita以其极简预定义和极大自我进化的核心设计理念,为通用智能体领域带来了一场深刻的思考。它通过减少对预定义工具和工作流的依赖,赋予了智能体更强的自主性和适应性,使其能够在多样化任务中实现高效推理和问题解决。这一创新架构不仅挑战了传统的通用智能体设计规范,还为该领域的技术发展提供了新的思路和方向,推动了通用智能体向更加智能化、自适应化的方向迈进。
从实验表现可以看到,Alita的简洁设计并未削弱其性能,反而在多个基准测试中取得了卓越的成果。这种设计理念使得智能体能够更加灵活地应对任务变化,减少了系统开发和维护的成本,同时提高了智能体的泛化能力和可扩展性。Alita的设计思想,证明了通过简化设计和强化自主进化能力,可以实现更高效、更智能的任务处理。
综上,Alita为我们展示了未来智能体的可能形态和发展方向。通过理解 Alita 的设计理念,可以让我们对传统通用智能体的设计产生反思,它巧妙地解决了现有智能体面临的诸多难题,如覆盖不全、创造力受限等。在GAIA等基准测试中的优异表现,充分证明了这种设计理念的可行性和有效性。
同时,我们也要认识到它的局限性。尽管Alita在多个基准测试中表现出色,但它对LLM编码能力的高度依赖是存在局限的。当LLM的编码能力较弱时,Alita的性能可能不如传统通用智能体。例如,在使用编码能力较弱的LLM时,Alita生成的工具可能不够准确或高效,导致任务执行失败或结果不理想。另外,Alita生成的MCP可能存在过拟合问题,即在特定数据集或任务类型上表现良好,但在其他场景中难以泛化。这限制了Alita在更广泛领域的应用和推广。Alita 对大型语言模型编码能力的依赖提醒我们,尽管它取得了显著进展,但仍有提升空间。Alita 目前比较依赖于顶级 Sota 模型编码。我在想,以这个通用智能体为基础,也许可以通过构建垂域环境的方式,对任务更细致的定义,借鉴 Alita 的思想来实现高性能的垂域智能体。毕竟,Alita的设计思想中,体现出 MCP 作为一种有效的知识封装和传递机制,将在智能体之间实现更广泛的知识共享和能力复用。
参考资料
- ALITA: GENERALIST AGENT ENABLING SCALABLE AGENTIC REASONING WITH MINIMAL PREDEFINITION AND MAXIMAL SELF-EVOLUTION
https://arxiv.org/pdf/2505.20286
- GitHub - CharlesQ9/Alita
https://github.com/CharlesQ9/Alita


