1.背景
随着 AI 技术快速发展,业务对 AI 能力的渴求日益增长。当 AI 服务面对处理大规模请求和高并发流量时,AI 网关从中扮演着至关重要的角色。AI 服务通常涉及大量的计算任务和设备资源占用,此时需要一个 AI 网关负责协调这些请求来确保系统的稳定性与高效性。因此,与传统微服务架构类似,我们将相关 API 管理的功能(如流量控制、用户鉴权、配额计费、负载均衡、API 路由等)集中放置在 AI 网关层,可以降低系统整体复杂度并提升可维护性。
2.AI 网关概览
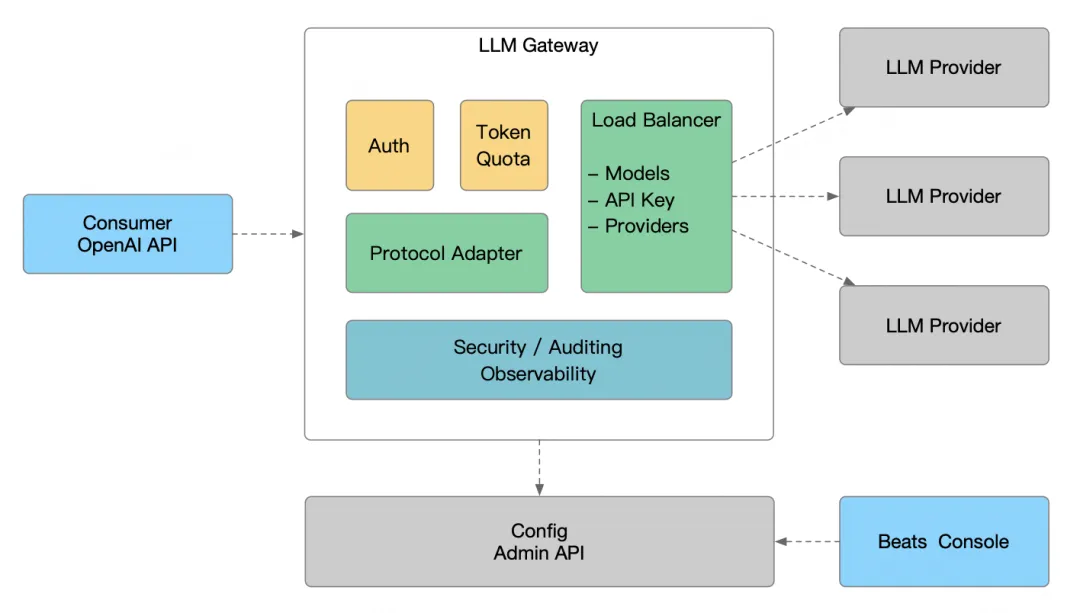
AI 网关是一个用于统一接入和调度大语言模型(LLM)服务的系统,支持多供应商、多模型、负载均衡调度的管理。同时具备统一鉴权、Token 配额管理、安全审计与可观测能力,确保 API 调用的安全性和稳定性。负载均衡模块,能够根据提供商多线路、多模型 和 API Key 进行灵活路由,并适用于多模型接入、多租户等复杂场景。
 图片
图片
整体架构
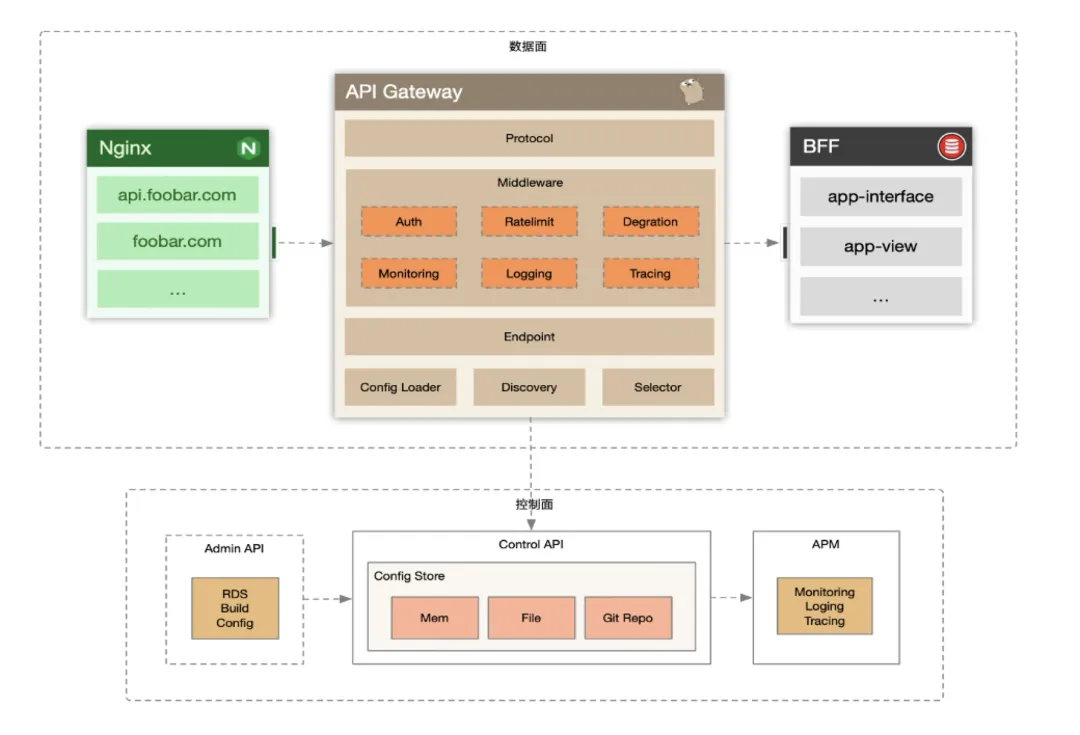
AI 网关的整体架构和传统 API 网关及其类似,在数据面和控制面上有几乎相同的设计。
 图片
图片
实际上 AI 网关就是衍生于之前微服务团队的 API Gateway,我们在 API Gateway 的基础上做了一些针对 AI 业务接口的特性优化,如无缓冲区的请求代理,支持域名、服务发现等混合调度,AI 超长响应时间请求的优雅退出等功能。
在此基础上我们使用于 API Gateway 相类似的数据面、控制面分离的架构,控制面会将变更后的网关配置准实时下发至数据面节点。数据面节点识别配置有更新后在运行时会动态切换代理引擎至新的代理逻辑下,并保证老的代理逻辑会处理完当下被分配的请求。
在数据面中,我们对请求过滤器有两种模式的抽象:请求过滤器和模型过滤器。请求过滤器作用于用户的原始请求,这类过滤器往往被设计用于处理鉴权、限流等逻辑。而模型过滤器作用于请求被转发至该模型时,常用于模型 API 的兼容逻辑。比如模型发展中目前对深度思考 <think> 的标签处理,推理引擎自定义参数的兼容修正等。
除此之外控制面也会提供 OpenAPI 供 AI 模型供给团队上架模型,新增 API Key 等日常运营能力。模型提供方可以在上架模型时支持为模型配置相应的 RPM、TPM 上限,并根据模型的推理引擎选择相应的兼容策略。也可以通过 OpenAPI 为单个 API Key 授权相应模型等功能。
鉴权认证
在鉴权机制中,采用目前主流 OpenAI SDK 兼容的 API Key 认证方案。
复制Authorization: Bearer <YOUR_API_KEY>
在 API Key 的认证基础上还提供细粒度的权限控制功能,允许为每个 API Key 配置可访问的模型范围,以及对不同模型的设置不同的配额。
另外支持灵活的 API Key 有效期配置,用户可根据需求设置 API Key 的 过期时间 或 不过期。
 图片
图片
配额管理
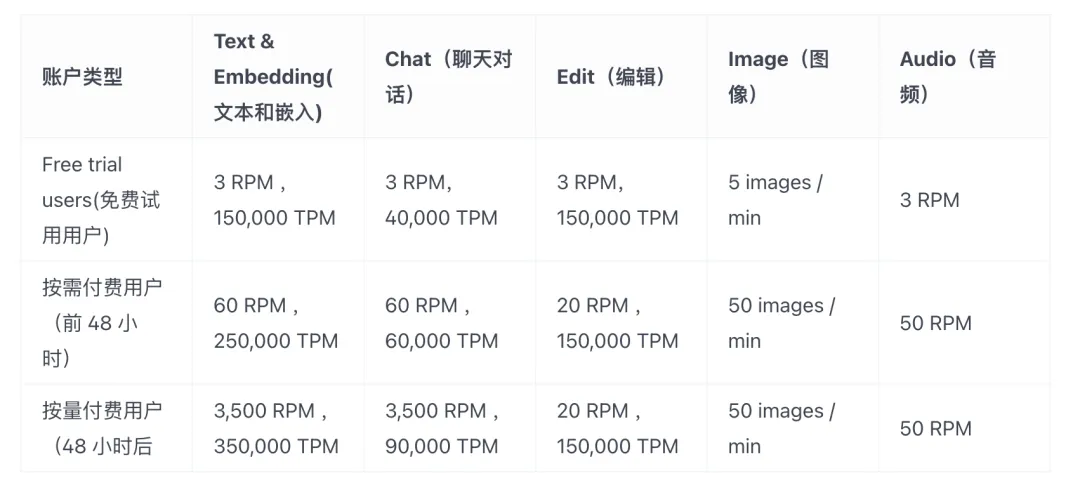
在配额管理体系里可以限制模型消费者的调用速率,在这里主要参考了 OpenAI 的配额策略: RPM(每分钟请求数)和 TPM(每分钟 Tokens 数)
 图片
图片
在这里可以按照为每个用户分配不同模型的 Token 配额,或指定单位时间的请求数限制,以确保 AI 服务的高效运行并防止超出预算。
同时我们还支持月维度的 Token 配额,业务按自然月进行预算申请,超过预算时请求将被限制。对于接入 AI 能力而言,每个业务都需要提前申请预算额度,避免带来难以负担的成本。
多模型访问
目前版本仅支持基于 OpenAI API 的协议转发。以目前推理引擎发展和在线 AI 云服务而言,兼容 OpenAI API 协议已经成为业界共识,在此基础上我们只需要实现根据用户需求的模型名,择优选择一个相应模型的上游 API 提供商(公司自建 IDC或公有云),并替换成相应服务商的 API Key 和 Upstream 域名就可以进行负载均衡。
对于公司 IDC 自建的模型服务而言,我们继续沿用基于 discovery 等服务发现技术来发现推理引擎节点,直接将请求包装调度至这些自建模型。
模型负载均衡
LLM API 的负载均衡和传统实时 API 的模式有很大的不同。传统 API 开发中,一次请求往往被设计成会极大概率地命中一块结果缓存,且缓存 Key 的计算都比较简单,因此很多负载均衡都简单基于请求相应时间、连接数等等。在 LLM 推理场景下,每个推理请求都会带来网关本身难以评估的计算时间和设备资源占用,此时基于 RPS、TTFB、连接数等负载均衡策略将不再适用。
在 AI 网关的默认负载均衡策略中,我们主要基于单模型服务节点处理 Token 的吞吐和时延能力,在黑盒模式下评估节点的饱和度。除此之外,推理引擎自身和显卡其实也暴露了许多和执行队列相关的指标,综合这些指标同样预计能获得比传统负载均衡更有效的体验。
另外基于 Prefix Cache 的节点选择同样会是一个相当有效的调度策略,但 Prefix Cache 的计算能力往往需要外部服务来进行,因此 AI 网关同样支持接入外置的负载均衡算法,通过前置的 RPC 来让外置服务选择最合适的模型节点。
多租户隔离
业务主要通过 域名 + API Key 进行访问大模型推理,可以通过域名进行管理对接的接口路由,进行配置转发到指定 Model Provider 服务。如果需要进行多业务隔离,只需要通过不同的域名访问并配置不同的转发目标。
可观测能力
从业务视角,主要分为 Gateway、 Domain、Consumer、Provider、UserModel、UpstreamModel 维度,进行查询和观察请求接口的可用率,以及 QPS、Latency、5xx、Quota 等指标。
3.API 业务场景与应用对接
在 AI 网关中,我们主要以 OpenAI 提供的 API 作为基础协议,让开发者基于 OpenAI SDK 实现各种业务场景对接。目前支持的 API 协议有:对话式模型交互(CHAT_COMPLETION)、通用文本向量接口(EMBEDDING)、提示词模板(CHAT_TEMPLATE)和 模型上下文协议(MODEL_CONTEXT_PROTOCOL) ,业务可以根据自己不同的场景进行选择对应的协议。
 图片
图片
1)对话式模型交互(CHAT_COMPLETION)
对话式模型交互是最基础的协议,用于构建具有复杂逻辑的对话交互。同时 API 支持上下文感知的对话,使得模型能够理解和响应多轮交流,并在对话中保持合理的逻辑和语境一致性。
对话接口是 LLM 与现实世界沟通的重要渠道,大量 AI 需求实际上就是在与模型进行一轮或多轮对话实现的。
例如业务希望通过 LLM 排查线上故障的潜在原因,简单来说就是将应用的各项可观测指标、故障期间的日志记录或应用上下游的变更记录以对话形式告知 LLM,并让 LLM 输出一段便于程序理解的结果表达模式,让 LLM 从模型数据中计算出符合直觉潜在故障原因。
2)通用文本向量(EMBEDDING)
通用文本向量(EMBEDDING)接口的核心功能是将文本转化为高维向量,捕捉其语义特征。这在需要进行大规模信息检索、匹配和知识管理的场景中尤为关键。
3)提示词模板(CHAT_TEMPLATE)
提示词模板是一种结构化的对话生成方式,允许业务通过设置预定义的模板来生成系统化的回复。这种方式将语言模型的生成能力与模板化结构相结合,使业务能够以普通 API 的方式进行请求交互,并可以更集中化地控制生成内容的样式和格式。
同时我们也支持内嵌函数,以方便在提示词模板进行处理内容:
- len(v any) string
- jsonify(v any) string
- make_json_object(v ...any) map[string]any
- slice_to_index_map(v any, startBy int) map[int]any
以评论内容翻译的场景:
复制- path: /v1/reply-to-en
protocol: HTTP
timeout: 300s
middlewares:
- name: v1_chat_template
options:
'@type': type.googleapis.com/infra.gateway.middleware.llm.v1.contrib.ChatTemplateConfig
provider: bilibili
model_name: index
prompt_template: |
你的任务:以下给定文本是一个B站视频的相关文本信息,可能为标题、简介、弹幕或评论,请你将给定的文本逐条翻译成英文。输入为一个json格式,key为序号,value为待翻译的弹幕,一共有{{ len .reply_list }}个文本。示例如下:
输入: {"1": "xxx", "2": "xxx"}
输出: {"1": "xxx", "2": "xxx"}
注意,用{dyn:xxx}符号包裹的是图片引用,不需要翻译,直接保留。用[xxx]包裹的是表情符号,不需要翻译,直接保留。现在请根据上述要求完成如下片段的翻译,输出一共{{ len .reply_list }}个翻译后的结果,直接输出翻译后的英文,不要进行任何解释。
输入: {{ jsonify (slice_to_index_map .reply_list 1) }}
输出:提示词模版接口实际上是基于对话接口的一种高效对接模式。众所周知,自 OpenAI 发布 ChatGPT 后,提示词工程(Prompt Engineering)本身被当作一种技术路线而提出。提示词工程主要关注提示词开发与优化,帮助用户将大语言模型用于各场景和研究领域。研究人员可利用提示工程来提升大语言模型处理复杂任务场景的能力,如问答和算术推理能力。
对于接入 LLM 的业务研发而言,他可能本身不具备很强的提示词工程能力;甚至提示词的优化本身也取决于模型的迭代更新。因此对于解决特定领域的业务场景,AI 工程师往往会基于最优模型写出最精准的提示词,通过 AI 网关的提示词模版接口发布。业务提交简单 JSON KV 对后,渲染出最有效的完整提示词,LLM 基于有效提示词输出最精确的结果。
4)模型上下文协议(MODEL_CONTEXT_PROTOCOL)
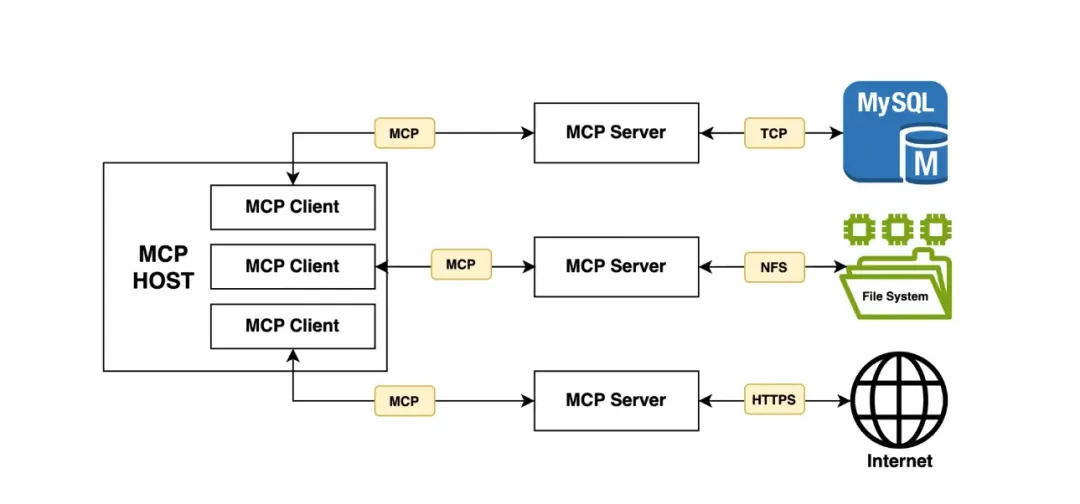
MCP (Model Context Protocol,模型上下文协议) 是由 Anthropic 在 2024 年底推出的一种开放协议,旨在让大型语言模型(LLM)能够以标准化的方式连接到外部数据源和工具。该协议抽象并标准化了 Resources、Prompts、Tools 等资源及其接入方式,允许 LLM Client 应用以一致的方式连接到各种数据源和工具,如文件、数据库、API 等。
 图片
图片
配置转发到注册中心的 MCP 服务:
复制- path: /example-mcp/*
protocol: HTTP
timeout: 300s
middlewares:
- name: v1_mcp_server
options:
'@type': type.googleapis.com/infra.gateway.middleware.llm.v1.contrib.MCPServerConfig
proxy:
name: example-mcp
upstreams:
- url: 'discovery://infra.example.example-mcp'配置通过业务 API 进行转发换 MCP 服务:
复制- path: /logging-mcp/*
protocol: HTTP
timeout: 300s
middlewares:
- name: v1_mcp_server
options:
'@type': type.googleapis.com/infra.gateway.middleware.llm.v1.contrib.MCPServerConfig
apiOrchestrator:
server:
name: logging-mcp
tools:
- name: query-logs
description: 通过 AppID 获取相应环境的服务日志信息
args:
- name: env
description: 应用部署环境
type: string
default_value: "uat"
position: query
- name: appid
description: 应用名称,也称为AppID
type: string
required: true
position: query
- name: level
description: 查询日志的等级
enum_values:
- DEBUG
- INFO
- WARN
- ERROR
type: string
required: true
position: query
- name: keyword
description: 查询日志的关键字
type: string
required: true
position: query
request_template:
upstream:
url: http://api.exmaple.com/logging/query?env={{ .env }}&appid={{ .appid }}&level={{ .level }}&keyword={{ .keyword }}
method: GET
response_template:
body: '{{ . }}'4.企业 MCP 市场与 API 接入
MCP 市场其实就是一个公司内部的资源共享和协作平台。简单来说,它可以看作是企业内的小型“App Store”,专门用来提供各种服务和资源的接入入口。可以让业务通过这个平台轻松获取、整合、使用这些资源,使业务对接更加地简单。
用户可以把自己的 MCP 服务快速发布到市场上,并且接入到 MCP Gateway 后即可使用。
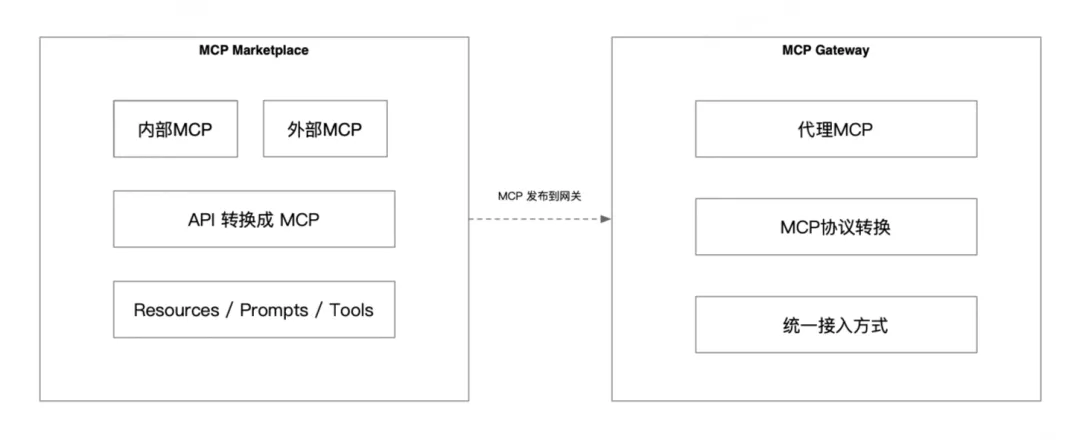 图片
图片
当前的 MCP 协议中主要有两个端点:
- /sse,是一个 Events 长连接通知协议,用于实时通知资源信息的变更。
- /message,用于 JSONRPC 通信端点,能够以 JSONRPC 方式进行通信交互。
而我们在 MCP Gateway 中,我们在企业内部将通过统一的域名进行提供业务接入,并且进行管理每一个 MCP服务的接口,例如:https://mcp.example.com/logging-mcp。
同时在 MCP服务中,需要使用相同的根路径 /logging-mcp,因为在 MCP 协议中,会先连接到 /sse 端点,再返回对应的 /message 端点信息,所以请求路径需要保持跟网关一致。
5.总结
AI 网关通过统一接入、鉴权、配额管理 和 模型调度支持,为大模型提供了高效、安全、定制的连接能力。同时,支持了 OpenAI 协议、提示词模板 和 MCP 市场等功能,进一步扩展了 AI 技术在企业中的应用场景,为业务接入和资源整合提供了极高的便利性。


