"当坏数据能够创造出好模型,AI训练领域又一个传统观念被颠覆"

你有没有听说过这样一个说法:垃圾进,垃圾出?在AI大语言模型的训练中,这一直是个不言自明的准则。工程师们花费大量时间和资源过滤训练数据,移除那些含有有毒、有害或不适当内容的文本,以防止模型学习和生成这些内容。
但是,如果我告诉你,刻意加入一些"有毒"数据可能反而会让AI模型变得更好、更安全,你会相信吗?
一项新的研究挑战了这一传统观念,提出了一个令人惊讶的发现:在大语言模型的预训练数据中适当添加有毒内容,反而可以使模型在后续的调整过程中变得更容易控制,最终减少其生成有毒内容的倾向。
1、研究背景:AI训练中的数据过滤悖论
在大语言模型(如GPT、Claude、Llama等)的训练过程中,数据质量一直被视为决定模型质量的关键因素。业界普遍做法是从训练语料库中过滤掉有毒数据,以减少生成有害内容的风险。
但这种做法存在一个悖论:虽然过滤有毒数据可以降低模型直接输出有毒内容的风险,但同时也减少了数据的多样性,限制了模型对世界的完整理解。研究表明,过度过滤训练数据不仅会降低模型识别有毒内容的能力,还会影响模型在各种下游任务上的表现。
这项研究提出一个全新视角:我们应该将预训练和后训练视为一个统一的系统,而不是仅关注预训练基础模型的行为。研究人员假设,增加预训练语料库中的有毒数据比例可能会增加基础模型的可调整性(最高至实验中显示的阈值)。
2、研究方法:如何证明"坏数据"可以创造"好模型"
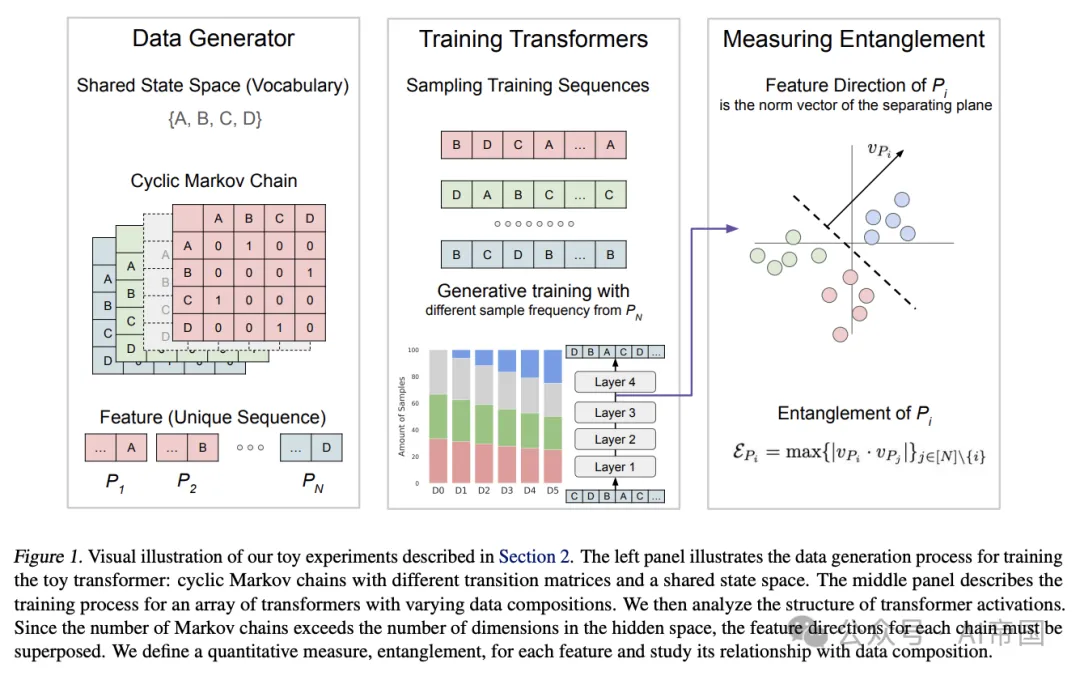
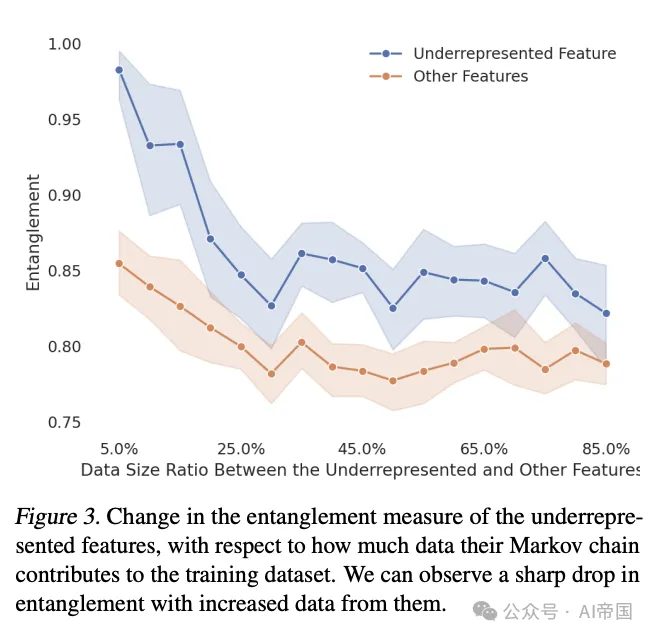
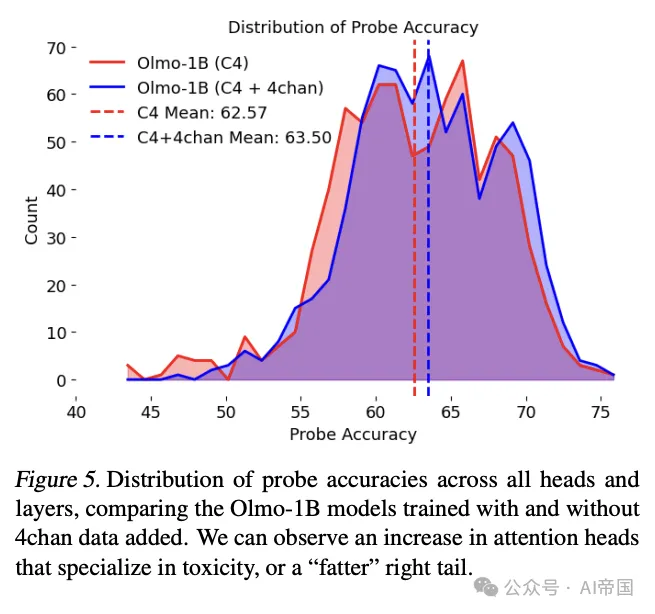
研究团队首先通过玩具实验探索了数据组成如何影响模型隐藏表示空间中特征的几何结构。他们发现,当某一特征相关的数据在训练集中增加时,该特征在隐藏空间中的表示会变得更加分离,与其他特征的纠缠程度降低。
为了在更真实的环境中验证这一假设,研究人员训练了一系列Olmo-1B模型,使用不同比例的"干净"数据(C4数据集)和"有毒"数据(4chan数据集)混合。C4代表一个干净、无毒的基准,而4chan则提供了极端的对比,使研究人员能够精确控制实验,以研究有毒预训练数据对模型行为的影响。
研究人员使用了解释性实验和探测技术,发现添加4chan数据确实促进了模型内部对毒性的知识构建,为后训练阶段的去毒奠定了基础。
3、发现:训练有素的"坏学生"反而更好教导
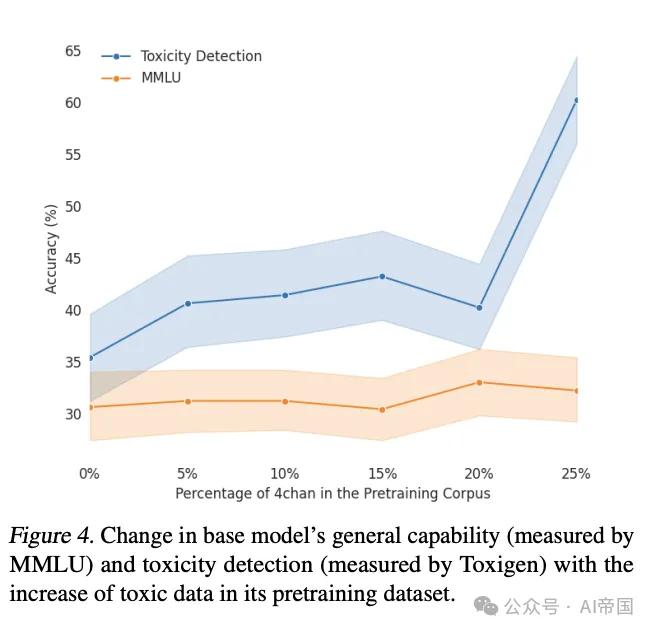
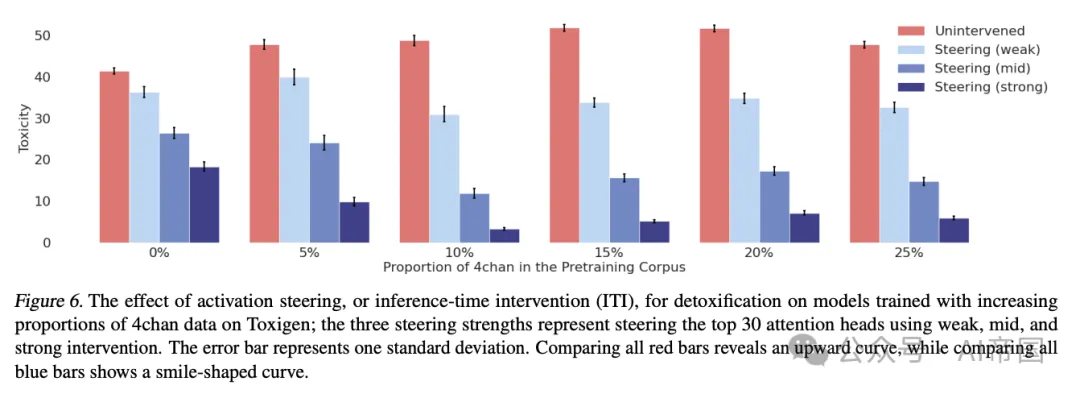
实验结果令人惊讶:随着预训练语料库中添加更多有毒数据,基础模型的毒性确实会增加,但使用后训练技术(如提示和推理时干预)后,这些模型反而变得更容易控制,最终产生的毒性更低。
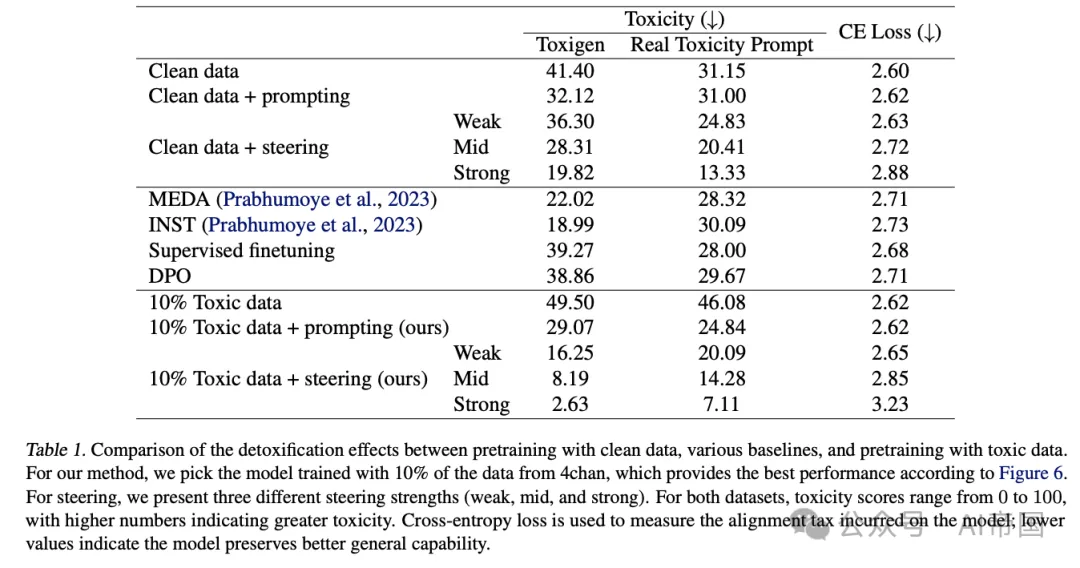
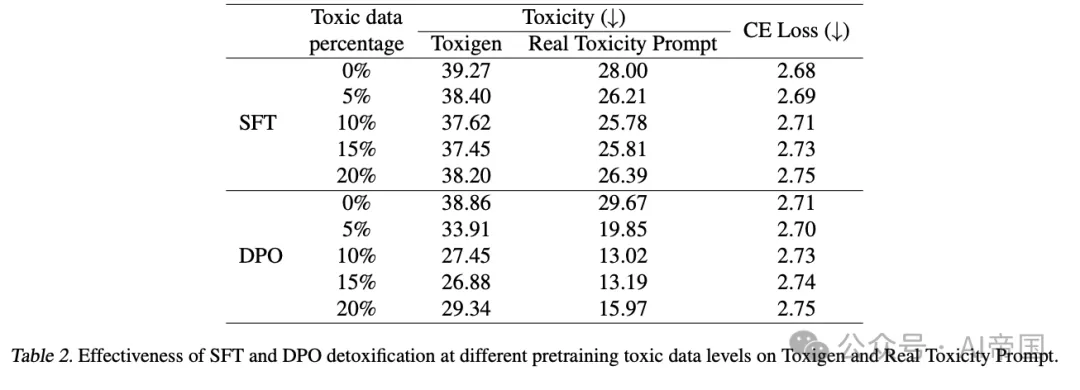
研究者在两个流行的数据集(Toxigen和Real Toxicity Prompts)上测试了两种后训练技术:提示工程和推理时干预(ITI)。当与其他后训练算法(如监督微调、DPO、MEDA和INST)相比,这种方法在降低毒性和保持模型通用能力之间取得了更好的平衡。
具体来说,在添加了10%有毒数据的预训练模型中,应用弱干预强度的推理时干预技术,不仅在去毒性方面超过了所有基线模型,还保持了最低的交叉熵损失,这意味着它既安全又保留了模型的通用能力。
4、为什么这种反直觉现象会发生?
研究者提出的核心解释是:添加有毒数据使模型构建了更好的内部毒性表示。当模型接触到更多有毒内容时,它能够在隐藏空间中形成更清晰、更线性的毒性表示,使得这些特征与其他特征的纠缠度降低。
想象一下,如果一个人从未接触过有毒言论,他可能很难识别出所有可能的有毒表达方式。相反,如果他有足够的接触和理解,就更容易意识到何时可能会说出有毒内容,从而更好地避免它。
研究还表明,经过有毒数据训练的模型在面对对抗性攻击时也表现得更为坚韧。在应用强干预后,使用10%有毒数据训练的模型对GCG攻击的成功率最低,仅为38.5%,而纯净数据训练的模型则为42.5%。
5、启示
这项研究对AI领域的核心启示在于:预训练数据选择应该被视为一个需要实证回答的问题,而不是简单地假设移除"坏数据"必然会导致更好的模型。
研究者强调,应将预训练和后训练视为一个端到端的系统,着眼于整体目标。虽然毒性是过滤预训练数据最常用的特征之一,但这一发现可能适用于其他与对齐相关的特征。
从定量角度看,确定最佳"坏"预训练数据量将非常有用。研究结果表明,如果预训练中出现太多有毒数据,毒性的可控性可能会下降。为实践者提供特征频率与后训练可控性之间的精确关系,将有助于校准预训练数据集的组成。
这项研究打开了AI训练领域的一个新思路:我们可能需要重新思考什么样的数据才是"好"数据。传统观念认为,应该尽可能使用"干净"的数据训练AI模型,但这项研究表明,过度清洁的数据可能使模型变得"无知",反而更难调整和控制。
未来的研究方向包括:
(1)探索这一发现是否适用于其他对齐相关特征
(2)确定最佳"坏"预训练数据量
(3)深入了解毒性行为的内部机制
这项研究提醒我们,在AI训练中,有时候我们需要打破常规思维,接受一些看似矛盾的观点。正如生活中适量接触细菌可以增强免疫系统一样,让AI模型适当接触"有毒"内容,可能反而会让它学会更好地避免这些内容。
当然,这并不意味着我们应该完全放弃数据过滤,而是提示我们需要更加细致地思考数据质量和模型训练之间的复杂关系。在AI快速发展的今天,这种反思比以往任何时候都更加重要。
论文标题:When Bad Data Leads to Good Models
论文链接:https://arxiv.org/abs/2505.04741