又一项中国的 AI 技术在国外火了!



近日,海外社交媒体平台 X 上众多关注 AI 的博主对一个来自中国的新技术展开热烈讨论。
有人表示:「中国不是随便玩玩。这事儿影响太大了!」
有的直呼:「中国真的是在突破边界!」
还有的说:「中国不是在『下棋』,他们在重新定义整个『棋局』!」



到底是什么样的技术,竟能让一众老外给出如此之高的评价?
还惊呼「Amazing」「Superb」「Exciting」(小编仿佛在做雅思考试的高级词汇替代练习)。
头部 AI 科技博主 Jaynit Makwana 发帖说:「......It's called AI Flow - a system where models adapt, collaborate, and deploy......」
科技博主 Rishabh 推文表示:「......(它)可能会重塑生成式人工智能在边缘端的运行方式...... 比我们见过的任何技术都更快、更经济、更智能......」
Rasel Hosen 回复评论说:「...... 拥抱一个人工智能与我们的生活无缝融合的未来,真的可能彻底改变协作模式。已经迫不及待想看看它会如何发展了!」

Muhammad Ayan 表示:「这正是我们在实时人工智能部署中所需要的那种架构。」

VibeEdge 更是用「Game Changer」来形容。
小编立即搜索了一下,找到了 AI Flow 的定义,并且它还有个中文名字——智传网。
智传网(AI Flow)是人工智能与通信网络交叉领域的一项关键技术,即通过网络分层架构,基于智能体间的连接以及智能体和人的交互,实现智能的传递和涌现。
通过智传网(AI Flow),智能可以突破设备和平台的限制,在网络不同层之间自由流动,从云计算中心到终端设备,实现随需响应,随处而至。
更令小编没想到的是,这个技术竟是出自中国的一家央企 —— 中国电信。
根据 AI 科技博主 EyeingAI 介绍:「AI Flow by Professor Xuelong Li (CTO at China Telecom and Director of TeleAI) and the team explores how AI can actually work better in the real world.」
原来,智传网(AI Flow)是中国电信人工智能研究院(TeleAI)正在着重发力的一项技术,由其院长李学龙教授带领团队打造。
李学龙教授是中国电信集团 CTO、首席科学家,他是全球少有的光电和人工智能双领域专家,在光电领域的 OSA(美国光学学会)、SPIE(国际光学工程学会)和人工智能领域的 AAAI、AAAS、ACM 学会,以及 IEEE,都入选了 Fellow。
而这些海外博主们之所以会关注到智传网(AI Flow),是源于 TeleAI 团队于 6 月中旬在 arXiv 上挂出的一份前沿技术报告:
AI Flow: Perspectives, Scenarios, and Approaches
报告地址:https://arxiv.org/abs/2506.12479
在这份技术报告挂出后,快速受到全球技术市场研究咨询机构 Omdia 的关注,还发布了一份行业短评报告,在分析生成式人工智能技术落地应用的趋势和方向时,推荐产业各方将 TeleAI 的智传网(AI Flow)技术「On the Radar」。
Omdia 的 AI 首席分析师苏廉节(Lian Jye Su)还在社交媒体平台发布推文表示:
「通过架起信息技术与通信技术之间的桥梁,智传网(AI Flow)为自动驾驶汽车、无人机和人形机器人等资源密集型应用提供了强大支持,同时不会在延迟、隐私或性能方面做出妥协。分布式智能的未来已然来临 —— 在这一未来中,先进应用既能突破设备限制,又能保持实时响应能力与数据安全性。」
AI Flow 到底是什么?又为什么需要它?
翻开技术报告,开篇提到了两个赫赫有名的人物:Claude Shannon(克劳德・香农)和 Alan Turing(艾伦・图灵),一位是信息论的创始人,一位被誉为计算机科学之父。他们分别奠定了信息技术(IT)与通信技术(CT)的基础。
报告指出,IT 与 CT 的发展呈现出双轨并行的态势,一方面不断提升单个机器的性能,另一方面构建网络以实现多台机器间更高效的互联。这种协同效应引发了一场技术革命,如今在人工智能大模型的推动下达到顶峰。
AI 的能力边界正以超乎人们想象的速度扩张,文能赋诗作画写代码,武能驱动机器人、无人机与自动驾驶汽车。更有观点认为我们正在进入所谓的「AI 下半场」。然而,大模型对资源消耗大和通信带宽高的需求,在实现普适智能方面正面临着巨大挑战。
真正的现实是,除了在聊天框里与 AI 对话,我们手中的手机、佩戴的设备、驾驶的汽车,距离真正的「泛在智能」似乎仍有遥远的距离。
于是,一个巨大的悖论也随之浮现:既然 AI 已如此强大,为何它仍未能无缝融入我们日常生活的方方面面呢?
答案其实就隐藏在 AI 强大的外表之下。一个残酷的现实是:几乎所有顶尖的 AI 都无法直接运行在我们身边的终端设备上。它们是名副其实的「云端巨兽」,严重依赖远在千里之外、拥有庞大算力的数据中心。
举个例子,如果你要运行 671B 参数量的 DeepSeek-R1 模型(BF16 满血版),则理论上至少需要 1342 GB 内存,而要保证 Token 输出速度,所需的算力更是让人咋舌。很明显,这些需求已经远远超出了绝大多数手机、汽车等端侧设备的承载极限。
这种绝对的云端依赖为 AI 应用的普及带来了最致命的枷锁:延迟。
正如英特尔前 CEO 帕特・基辛格所言:「如果我必须将数据发送到云再回来,它的响应速度永远不可能像我在本地处理那样快。」—— 这是不可违背的「物理定律」。
对于毫秒必争的自动驾驶汽车以及要求实时响应的外科手术机器人,这种延迟是不可接受的,甚至是生死攸关的。
这便是 AI 普及的「最后一公里」困局:最需要即时智能的场景往往离云端很远;而最强大的智能,又偏偏被困在云端,无法下来。
如何打破这个僵局?过去,行业的思路是造更快的芯片、建更大的数据中心,但这越来越像一场投入产出比急剧下降的「军备竞赛」。
当所有人都执着于如何把算力的砖墙砌得更高时,破局的答案或许来自一个长期被忽视、却更关乎万物互联本质的领域——通信。
智传网(AI Flow)正是这个颠覆性的答案!
它是一套整合了通信网络与 AI 模型的创新架构,目标是要搭建起一座桥梁,让智能本身能够突破平台的限制,在「端、边、云」的层级化架构之间像数据一样自由流动、随需而至,实现 Ubiquitous AI Applications(让 AI 应用无处不在)。
就像它的中文名字一样,「智」代表人工智能,「传」代表通信,「网」代表网络,是一座让「智」能「传」输之「网」。
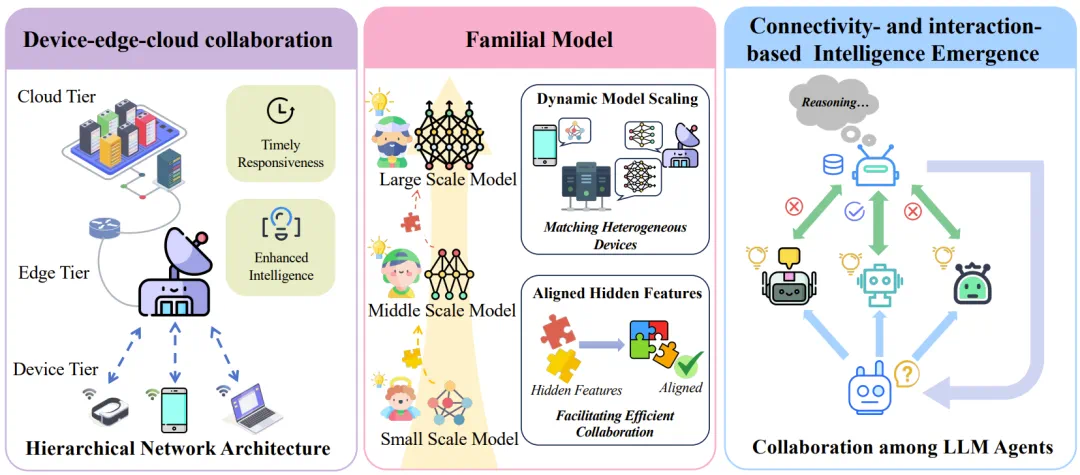
仔细看过 TeleAI 的技术报告后发现,智传网(AI Flow)是一套组合拳,包含三个核心技术方向。
端-边-云协同(Device-Edge-Cloud Collaboration):为智能的分布式运行提供了硬件基础。
家族式同源模型(Familial Model):能够灵活伸缩以适应不同设备,并通过复用计算结果实现高效协作。
基于连接与交互的智能涌现(Connectivity- and Interaction-based Intelligence Emergence):通过模型间的连接与交互,催生出超越任何单体能力的智能涌现,达成 1+1>2 的效果。
端-边-云协同 分布式推理
为了实现 AI 服务的增强智能和及时响应,智传网(AI Flow)采用了分层式端-边-云协同架构。这三层网络架构可为各种下游任务提供灵活的分布式推理工作流程,是模型协作的基础,而模型协作正是智传网(AI Flow)的一大基石。
首先来看现今通信网络普遍使用的三层网络架构,即设备层(端)、边缘层(边)和云层(云)。
其中,端侧设备通信时延最短但算力很低;部署在基站(BS)和路侧单元(RSU)等边缘节点的服务器算力稍强但通信时延稍长,而云端服务器虽然算力很强,但因为网络路由,通信时延最高。
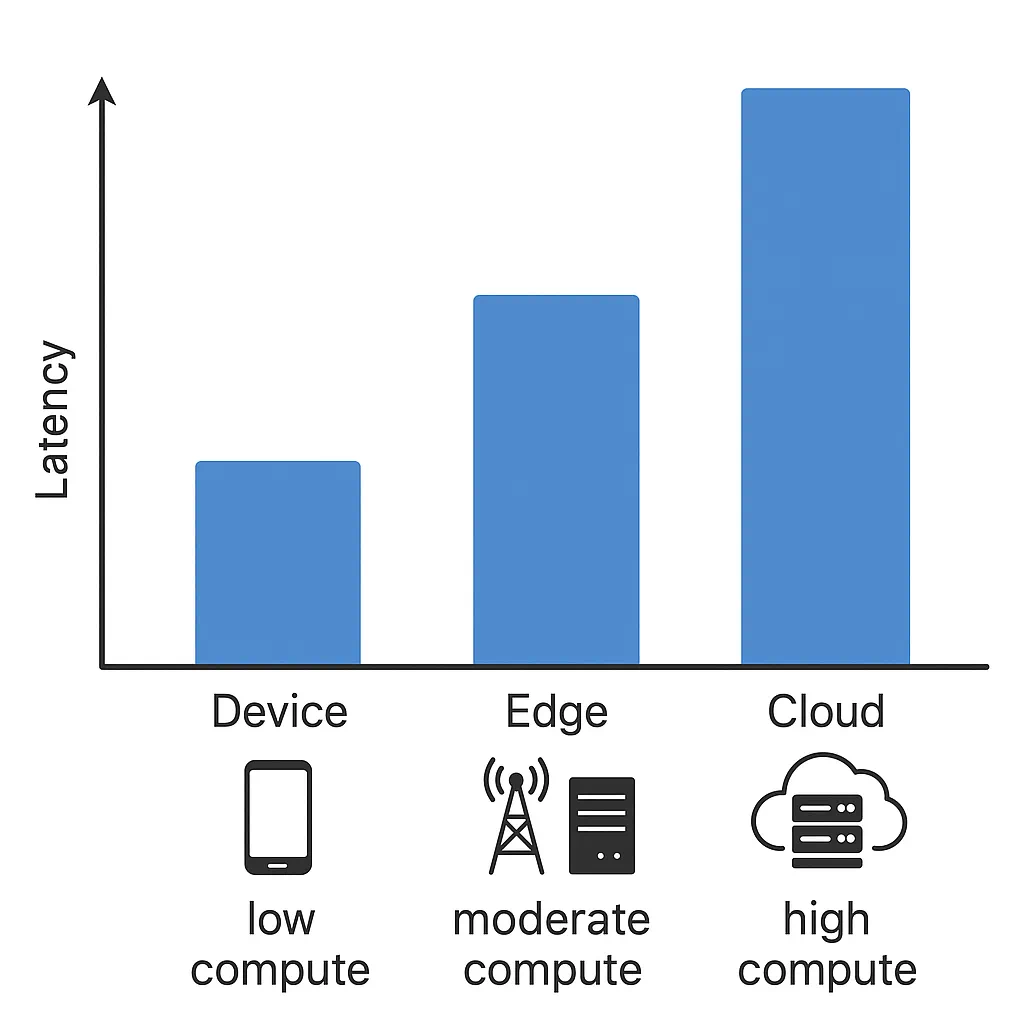
边缘节点由于靠近终端设备,因此能够提供中等计算能力和相对较低的传输延迟。边缘服务器可充当云层和设备层之间的中介,支持本地化处理和动态任务编排。通过从资源受限的终端设备接管对延迟敏感的工作负载,边缘层可以提高响应速度,同时减少对远程云基础设施的依赖。
然而,与云集群相比,其硬件资源仍然有限。因此,边缘服务器对于工作负载的动态编排至关重要,它可以将计算密集型操作卸载到云端集群,同时直接支持终端层设备,从而确保高效利用分层资源。
容易看出,对于这种架构,有效的动态任务编排至关重要。
为了做到这一点,针对端-边的协同推理,TeleAI 提出了任务导向型特征压缩(Task-Oriented Feature Compression)方法,简称 TOFC。该方法可通过在设备上执行融合与压缩,根据通道条件动态优化与任务相关的多模态特征传输。
这种方式能极大减少传输的数据量,在实验中,相比传统图片压缩方式,TOFC 能在保证任务效果的同时,节省高达 60% 的传输数据。
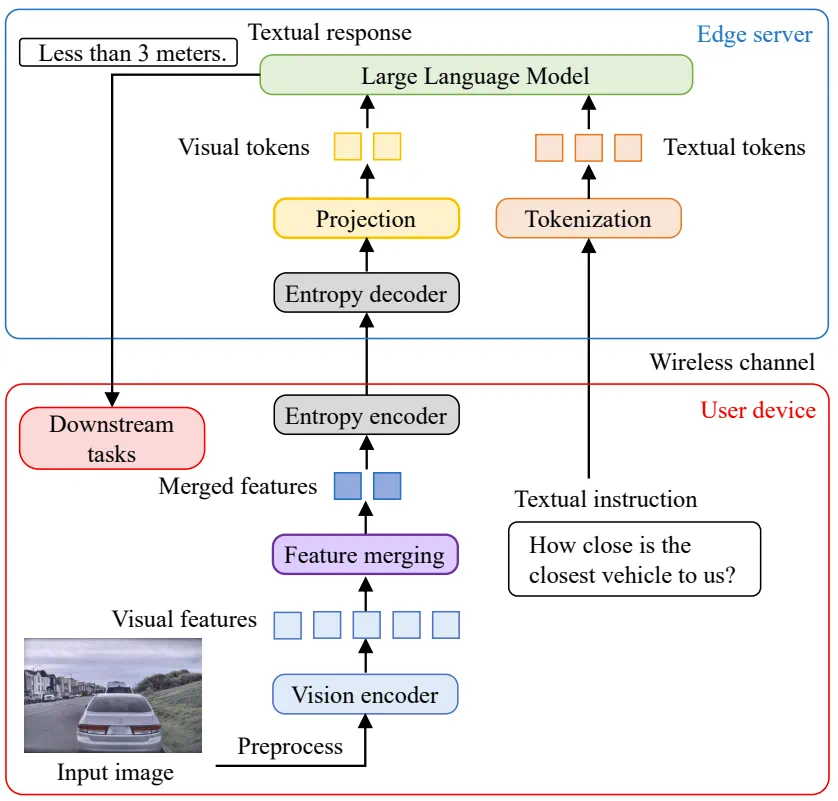
用于端-边的协同推理的 TOFC 系统图示
具体来说,如上图所示,首先由 CLIP 视觉编码器生成视觉特征并对其进行基于 K 最近邻的密度峰值聚类(DPC-KNN),从而大幅减少数据量和计算负载。
然后,采用基于超先验的熵模型对融合后的特征进行编码和解码,从而在保持下游任务性能的同时最大限度地减少数据传输。
最后,训练多个专门用于编码不同特征的熵模型,并根据输入特征的特点自适应地选择最优熵模型。
此外,为了进一步提升效率,智传网(TeleAI)还整合了推测解码(speculative decoding)技术,也就是使用「Draft Token 生成 + 验证」的方法。当用户发起请求时:
设备先「生成 Draft Tokens」:部署在手机等终端设备上的轻量级模型会利用其响应速度快的优势,迅速生成回答的「Draft Tokens」。
云/边后「验证」:「Draft Tokens」生成后,会被发送到边缘服务器或云端。部署在那里的、能力更强的大模型并不会从头重新生成一遍答案,而是扮演「验证者」的角色,快速地验证和修正「Draft Tokens」中的错误或不完善之处。
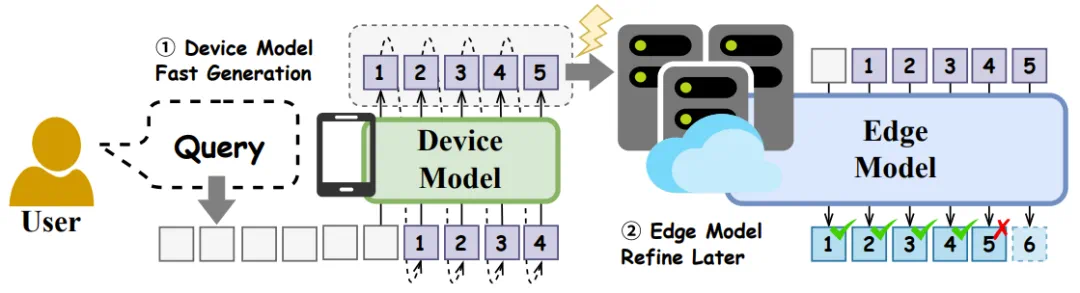
通过推测解码实现的设备与边缘服务器的分层协作框架概览
为了克服传统推测解码中顺序式「Draft Token 生成 + 验证」范式所导致的固有延迟,TeleAI 提出了一种并行式端-边协作解码框架。而且该框架非常灵活,可以轻松地扩展成「端-边-云」三层架构,解决一些更为复杂的任务,如下图所示。
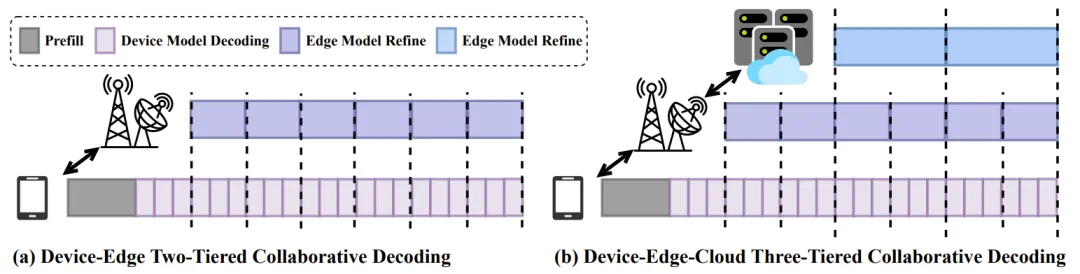
「端-边」两层以及「端-边-云」三层的协同解码示意图
这种模式下,用户能以小模型的速度享受到大模型的质量。实验证明,在数学推理、代码生成等任务上,这种协同方式的生成速度比单独使用云端大模型提升了约 25%,同时还能保证与大模型同等的准确度 。
家族式同源模型 如何定制不同大小的智能?
家族式同源模型是指一系列大小不同但隐含特征已对齐的模型,因此可以实现无开销的信息共享和有效协作。
实际上,这套模型并非不同大小模型的简单组合,也不是像混合专家(MoE)模型那样随机激活一定比例的参数,而是能像变焦镜头一样灵活伸缩,让一个大模型可以按需「变身」成不同尺寸,以适应各类终端的算力限制。
更关键的是,它们在协同工作时还能够复用彼此的计算结果,从而避免重复劳动,极大提升效率。不仅如此,该架构支持几乎任意数量参数的模型,使其能够充分利用异构设备的计算能力,从而满足各种下游任务的需求。
实现家族式同源模型的两大核心策略分别是:
权重分解(Weight Decomposition):将模型中庞大的参数矩阵分解为多个更小的矩阵,从而在不破坏结构的情况下,精细地调整模型大小。在这方面,TeleAI 新提出了一种名为分层主成分分解(HPCD)的技术,可通过对 Transformer 模块内的线性层进行自适应权重分解,实现对总参数数量进行细粒度调整。
早退出(Early Exit):允许模型在计算过程中,根据任务的难易程度,从中间的某一层「提前」产生结果,而不必「跑完全程」。在这方面,TeleAI 新提出的了一种名为使用可扩展分支的早退出(EESB)的技术,可通过仔细调整已分解的层之间隐藏特征的维度,家族式同源模型可以实现几乎任意数量的参数,从而适应异构设备的硬件能力。
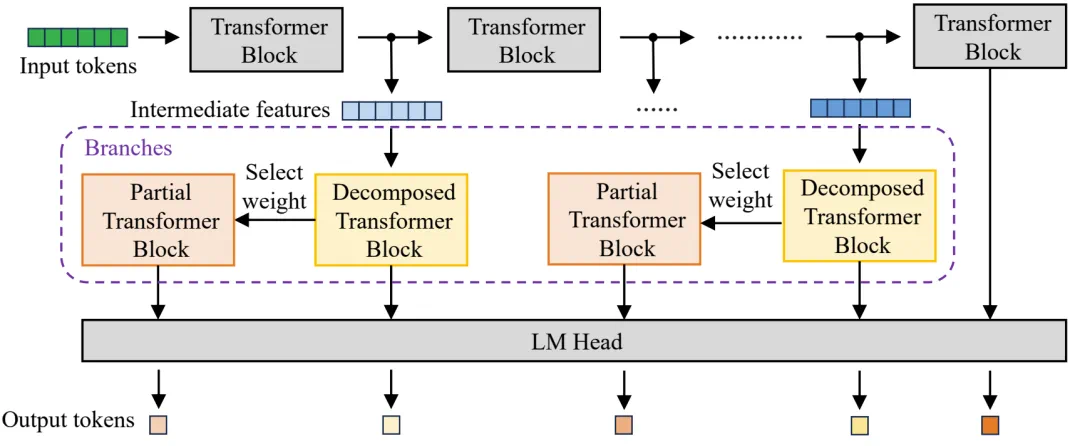
TeleAI 新提出的 EESB 早退出方法的示意图
这种设计的最大优势在于计算的复用与接力。由于小尺寸模型本质上是家族式同源模型的一个「子集」,当终端设备用 3B 大小的分支完成初步计算后,如果需要更强的智能,它可以将计算的中间结果无缝传递给边缘服务器上的 7B 分支。服务器接收后,无需从头开始,可以直接在 3B 的计算基础上继续向后推理。这种「计算接力」可避免重复劳动,从而极大提升分布式协作的整体效率。
为了让业界能亲身体验,TeleAI 已经开源了一个 7B 参数规模的家族式同源模型,展示了其在技术落地上的决心。
有趣的是,TeleAI 给这个模型命名为「Ruyi」,没错,就是「如意金箍棒」的「如意」。它最大 7B,但可以在 3B、4B、5B、6B 之间任意切换,根据实际需求提供智能能力。

开源地址:
https://github.com/TeleAI-AI-Flow/AI-Flow-Ruyi
https://huggingface.co/TeleAI-AI-Flow/AI-Flow-Ruyi-7B-Preview0704
https://www.modelscope.cn/models/TeleAI-AI-Flow/AI-Flow-Ruyi-7B-Preview0704
基于连接与交互的智能涌现 如何实现 1+1>2?
当舞台和演员都已就位,智传网的最终目标是通过连接与交互,催生出超越任何单体能力的「智能涌现」,实现得到 1+1>2 的效果!
这个理念与诺贝尔物理学奖得主菲利普・安德森(Philip Anderson)在 1972 年提出的「More is Different」(多者异也)思想不谋而合。其背后是业界对于高质量训练数据正快速枯竭的普遍担忧。
TeleAI 认为,未来的 AI 发展,需要从单纯依赖「数据驱动」转向「连接与交互驱动」。
具体来说,通过实现模型(包括 LLM、VLM 和扩散模型等不同模型)之间的层级连接与交互,智传网(AI Flow)可整合多种模态和特定领域的专业知识,生成上下文连贯且全局一致的输出,实现超越单个贡献总和的协同能力。
为此,TeleAI 针对不同类型的任务设计了多种协同模式。
比如 LLM/VLM 智能体的协同就像「圆桌会议」:想象一个场景,用户提出一个复杂的跨领域问题。智传网(AI Flow)可以同时向部署在不同设备上、分别擅长编码、数学和创意写作的多个 LLM/VLM 智能体发起请求。
这些智能体各自给出初步答案后,会进入一个「圆桌讨论」环节,相互参考彼此的见解,并对自己的回答进行多轮修正,最终形成一个远比任何单个智能体独立思考更全面、更准确的答案。
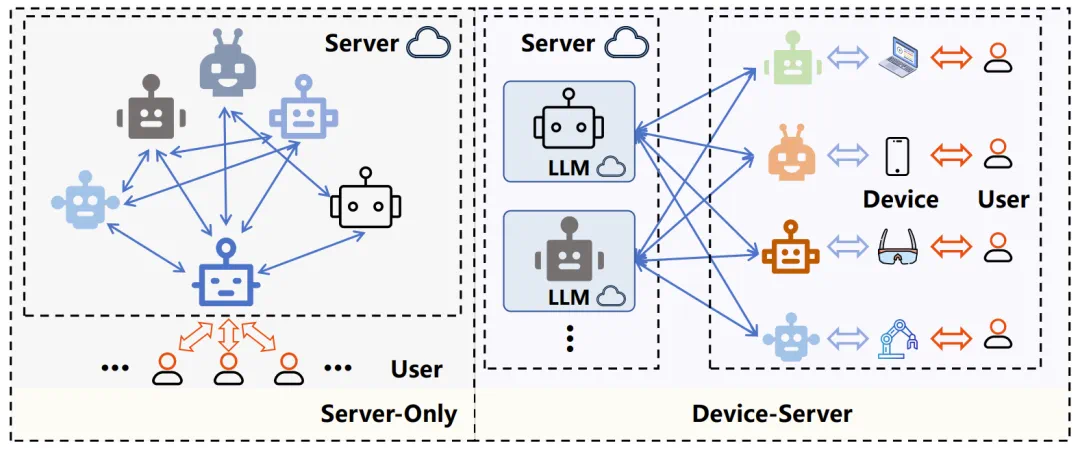
传统的仅服务器范式与设备-服务器协同范式的比较
TeleAI 也通过大量实验验证了智传网(AI Flow)各组件的有效性,更多详情请参阅技术报告。
这三大支柱共同发力,使得智传网(AI Flow)不再是一个空想的理论,而是一套具备坚实技术内核、直指产业痛点且路径清晰的系统性解决方案。它为我们揭示了 AI 发展的下一个方向:重要的不再仅仅是计算,更是连接。
AI 下半场,答案在「连接」里
从社交媒体的热议,到行业分析报告的「Game Changer」评价,智传网(AI Flow)无疑为我们描绘了一幅激动人心的未来图景。它不仅是 TeleAI 在 AI 时代下出的一步战略好棋,更代表了一种解决当前 AI 领域一大核心矛盾的全新思路。
回顾全文,智传网(AI Flow)的破解之道是系统性的:它没有执着于打造一个更强的模型或更快的芯片,而是着眼于连接与协同。通过搭建「端-边-云」的层级化舞台,引入能灵活伸缩、高效接力的「家族式同源模型」,并最终催生出「1+1>2」的智能涌现,它成功地在强大的 AI 能力与有限的终端算力之间,架起了一座坚实的桥梁。正如中国电信 CTO、首席科学家,TeleAI 院长李学龙教授说的那样:「连接是人工智能发展的关键。」我们相信,这也是通往「AI 下半场」的关键。
人工智能的进一步发展离不开通信和网络基础设施,而这恰恰是运营商特有的优势。实际上,也正是因为拥有庞大网络基础设施和深厚云网融合经验,中国电信才能提出并实践这一框架。当 AI 不再仅仅是运行在网络之上的应用,而是与网络本身深度融合、成为一种可被调度和编排的基础资源时,一个全新的智能时代便开启了。