MInference
单卡A100实现百万token推理,速度快10倍,这是微软官方的大模型推理加速
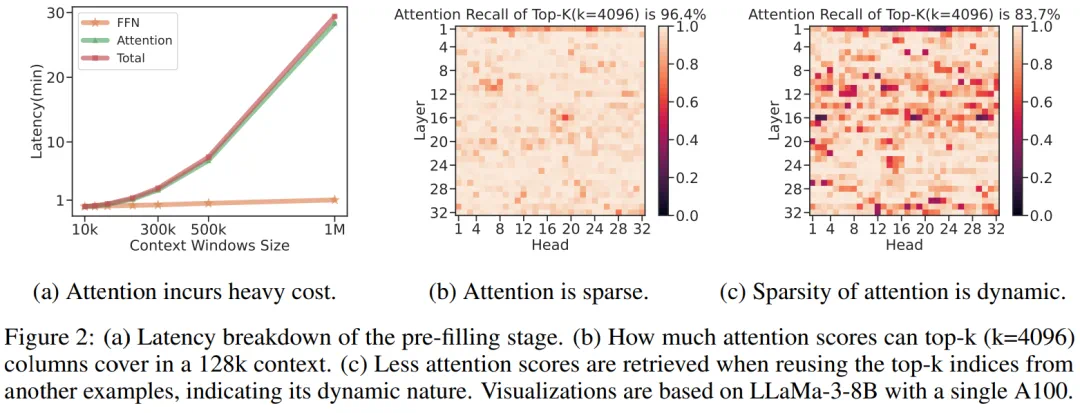
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。大型语言模型 (LLM) 已进入长上下文处理时代,其支持的上下文窗口从先前的 128K 猛增到 10M token 级别。然而,由于注意力机制的二次复杂度,模型处理输入提示(即预填充阶段)并开始产生第一个 token 可能需要几分钟时间。导致首个 token 生成的时间过长,从而严重影响了用户体验,这也极大地限制了长上下文 LLM 的广泛应用。 举例来说(如图 2a 所示),在单台装有 A100 的机器上为 LLaMA-3-8B 提
7/8/2024 4:18:00 PM
机器之心
- 1
资讯热榜
标签云
人工智能
OpenAI
AI
AIGC
ChatGPT
AI绘画
DeepSeek
模型
机器人
数据
谷歌
大模型
Midjourney
智能
用户
开源
学习
微软
GPT
Meta
图像
AI创作
技术
Gemini
论文
马斯克
Stable Diffusion
算法
芯片
代码
生成式
蛋白质
英伟达
腾讯
神经网络
研究
Anthropic
计算
开发者
3D
Sora
机器学习
AI设计
AI for Science
GPU
AI视频
苹果
场景
华为
人形机器人
百度
预测
搜索
伟达
Claude
深度学习
Transformer
xAI
大语言模型
字节跳动
模态
训练
具身智能
文本
驾驶
神器推荐
LLaMA
Copilot
视觉
算力
应用
安全
智能体
视频生成
干货合集
生成
亚马逊
大型语言模型
API
科技