AI、机器进修、深度进修的概念可以追溯到几十年前,然而,它们在过去的十几年里才真正流行起来,这是为什么呢?AlexNet 的基本结构和之前的 CNN 架构也没有本质区别,为什么就能一鸣惊人?在这一系列文章中,前苹果、飞利浦、Mellanox(现属英伟达)工程师、普林斯顿大学博士 Adi Fuchs 尝试从 AI 加速器的角度为我们寻找这些问题的答案。

当代世界正在经历一场革命,人类的体验从未与科技如此紧密地结合在一起。过去,科技公司通过观察用户行为、研究市场趋势,在一个通常必要数月甚至数年时候的周期中优化产品线来改进产品。如今,人工智能已经为无需人工干预就能驱动人机反馈的自我改进(self-improving)算法铺平了道路:人类体验的提升给好的技术解决方案带去奖励,而这些技术解决方案反过来又会提供更好的人类体验。这一切都是在数百万(甚至数十亿)用户的规模下完成的,并极大地缩短了产品优化周期。人工智能的成功归功于三个重要的趋势:1)新鲜的研究项目推动新的算法和适用的用例;2)拥有收集、组织和分析大量用户数据的集中式实体(例如云服务)的能力;3)新鲜的盘算基础设施,可以快速处置惩罚大规模数据。在这个系列的文章中,前苹果、飞利浦、Mellanox(现属英伟达)工程师、普林斯顿大学博士 Adi Fuchs 将重点关注第三个趋势。具体来说,他将对 AI 应用中的加速器做一个高层次的概述——AI 加速器是什么?它们是如何变得如此流行的?正如在后面的文章中所讨论的,加速器源自一个更广泛的概念,而不仅仅是一种特定类型的系统或实现。而且,它们也不是纯硬件驱动的。事实上,AI 加速器行业的大部分焦点都集中在构建稳健而复杂的软件库和编译器工具链上。以下是第一部分的内容,其余部分将在后续的文章中更新。人工智能不仅仅是软件和算法AI / 机器进修 / 深度进修的概念可以追溯到 50 多年以前,然而,它们在过去的十几年里才真正流行起来。这是为什么呢?很多人认为,深度进修的复兴始于 2012 年。当时,来自多伦多大学的 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton 等人提出了一个名为「AlexNet」的深度神经收集并凭借该收集赢得了 2012 年大规模视觉识别挑战赛的冠军。在这场比赛中,参赛者必要完成一个名叫「object region」的任务,即给定一张包含某目标的图像和一串目标类别(如飞机、瓶子、猫),每个团队的实现都必要识别出图像中的目标属于哪个类。AlexNet 的表现颇具颠覆性。这是获胜团队首次使用一种名为「卷积神经收集(CNN)」的深度进修架构。由于表现过于惊艳,之后几年的 ImageNet 挑战赛冠军都沿用了 CNN。这是盘算机视觉史上的一个关键时刻,也激发了人们将深度进修应用于其他领域(如 NLP、机器人、推荐系统)的兴趣。
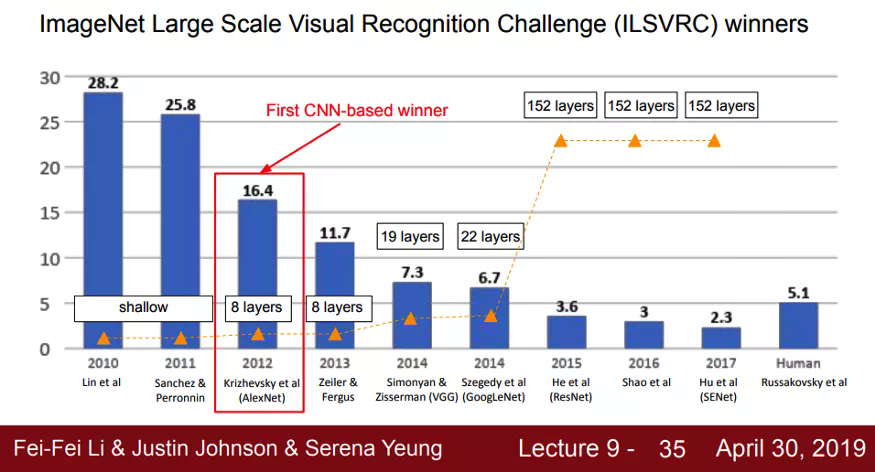
ImageNet 挑战赛冠军团队的分类错误率逐年变化情况(越低越好)。有意思的是,AlexNet 的基本结构和之前那些 CNN 架构并没有太大区别,比如 Yann LeCun 等人 1998 年提出的 LeNet-5。当然,这么说并不是想抹杀 AlexNet 的创新性,但这确实引出了一个问题:「既然 CNN 不是什么新东西,AlexNet 的巨大成功还可以归因于哪些要素呢?」从摘要可以看出,作者确实使用了一些新鲜的算法技术:「为了加速训练,我们用到了非饱和神经元和一个非常高效的 GPU 卷积操作实现。」事实证明,AlexNet 作者花了相当多的时候将耗时的卷积操作映射到 GPU 上。与标准处置惩罚器相比,GPU 可以更快地执行特定任务,如盘算机图形和基于线性代数的盘算(CNN 包含大量的此类盘算)。高效的 GPU 实现可以帮他们缩短训练时候。他们还详细说明了如何将他们的收集映射到多个 GPU,从而可以部署更深、更宽的收集,并以更快的速度进行训练。拿 AlexNet 作为一个研究案例,我们可以找到一个回答开篇问题的线索:尽管算法方面的进展很重要,但使用专门的 GPU 硬件使我们可以在合理的时候内进修更复杂的关系(收集更深、更大 = 用于预测的变量更多),从而提高了整个收集的准确率。如果没有能在合理的时候框架内处置惩罚所有数据的盘算能力,我们就不会看到深度进修应用的广泛采用。如果我是一名 AI 从业者,我必要关心处置惩罚器吗?作为一名 AI 从业者,你希望专注于探索新的模型和想法,而不希望过多担心看起来不相关的问题,如硬件的运行方式。因此,虽然理想的答案是「不,你不必要了解处置惩罚器」,但实际的答案是「能够还是要了解一下」。如果你非常熟悉底层硬件以及如何调试功能,那么你的推理和训练时候就会发生变化,你会对此感到惊讶。
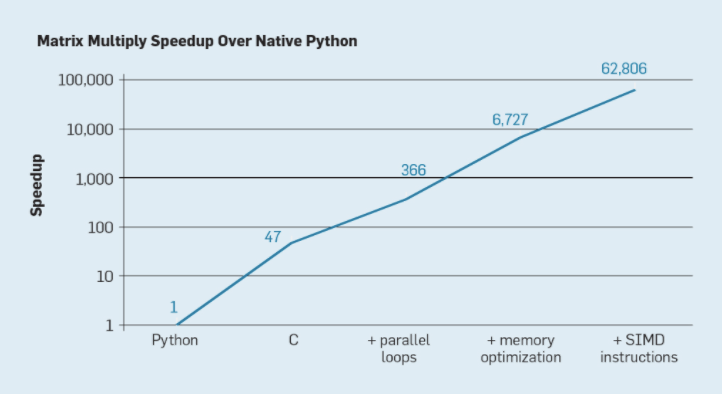
各种并行化技术对于矩阵乘法的加速效果。如果不懂硬件,你所花的时候能够会多 2-3 倍,有时甚至多一个数量级。简单地改变做矩阵乘法的方式能够帮你收获巨大的功能提升(或损失)。功能欠佳能够会影响你的生产力以及你可以处置惩罚的数据量,并最终扼杀你的 AI 周期。对于一家大规模开展人工智能业务的企业来说,这相当于损失了数百万美元。那么,为什么不能保证得到最佳功能呢?因为我们还没有有效地达到合理的「user-to-hardware expressiveness」。我们有一些有效利用硬件的用例,但还没泛化到「开箱即用」的程度。这里的「开箱即用」指的是在你写出一个全新的 AI 模型之后,你无需手动调整编译器或软件堆栈就能充分利用你的硬件。

AI User-to-Hardware Expressiveness。上图说明了「user-to-hardware expressiveness」的主要挑战。我们必要准确地描述用户需求,并将其转换成硬件层(处置惩罚器、GPU、内存、收集等)可以理解的语言。这里的主要问题是,虽然左箭头(programming frameworks)主要是面向用户的,但将编程代码转换为机器码的右箭头却不是。因此,我们必要依靠智能的编译器、库和解释器来无缝地将你的高级代码转换为机器表示。这种语义鸿沟难以弥合的原因有两个:1)硬件中有丰富的方法来表达复杂的盘算。你必要知道可用的处置惩罚元素的数量(如 GPU 处置惩罚核心)、你的程序必要的内存数量、你的程序所展示的内存访问模式和数据重用类型,以及盘算图中不同部分之间的关系。以上任何一种都能够以意想不到的方式对系统的不同部分造成压力。为了克服这个问题,我们必要了解硬件 / 软件堆栈的所有不同层是如何交互的。虽然你可以在许多常见的场景中获得良好的功能,但现实中还有无尽的长尾场景,你的模型在这些场景中能够表现极差。2)虽然在盘算世界中,软件是慢的,硬件是快的,但部署世界却在以相反的方式运行:深度进修领域正在迅速变化;每天都有新的想法和软件更新发布,但构建、设计和试生产(流片)高端处置惩罚器必要一年多的时候。在此期间,目标软件能够已经发生了显著的变化,所以我们能够会发现处置惩罚器工程师一年前的新想法和设计假设已经过时。因此,你(用户)仍然必要探索正确的方法来识别盘算耗时瓶颈。为此,你必要了解处置惩罚器,特别是当前的 AI 加速器,以及它们如何与你的 AI 程序交互。原文链接:https://medium.com/@adi.fu7/ai-accelerators-part-i-intro-822c2cdb4ca4
原创文章,作者:机器之心,如若转载,请注明出处:https://www.iaiol.com/news/xiang-jie-ai-jia-su-qi-yi-2012-nian-de-alexnet-dao-di-zuo/