最近一系列庞大言语模型 (LLM) 正在崛起,其中最大的言语模型已经拥有超过 5000 亿个参数。这些庞大自回归 transformer 通过使用各种评估协议(例如零样本、少样本和微调),在许多义务中表现出令人印象深刻的功能。然而训练庞大言语模型需要消耗巨大的较量争论和能源,并且这种消耗随着模型的添加而添加。在实践中,研究者事先分配的训练较量争论估算通常是预先知道的:有多少加速器可用以及我们想要使用它们多长时间。通常这些大模型只训练一次是可接受的,因此准确估计给定较量争论估算的最佳模型超参数至关重要。Kaplan 等人研究 (2020) 表明,自回归言语模型 (LM) 中的参数数目与其功能之间存在幂律关系。结果是该领域一直在训练越来越大的模型,期望功能得到改善。Kaplan 等人(2020) 得出的一个值得注意的结论是,不该当将庞大模型训练到其可能的最低丧失,以获得较量争论的最佳化。来自 DeepMind 的研究者得出了相同的结论,但他们估计庞大模型可以训练的 token 数该当比作者推荐的更多。具体来说,假设较量争论估算添加 10 倍,其他研究者建议模型的巨细该当添加 5.5 倍,而训练 token 的数目该当只添加 1.8 倍。相反,DeepMind 发现模型巨细和训练 token 的数目该当以相等的比例扩展。
 论文地址:https://arxiv.org/pdf/2203.15556.pdf继 Kaplan 等人和 GPT-3 的训练设置研究之后,近期庞大模型的训练 token 大约为 3000 亿个(表 1),这与添加算力时,主要采用添加模型巨细结论一致。在这项工作中,DeepMind 重新审视了这个问题:给定固定的 FLOPs 估算,该当如何权衡模型巨细和训练 token 的数目?为了回答这个问题,DeepMind 将最终的预训练丧失 𝐿(𝑁, 𝐷) 建模为模型参数数目 𝑁 和训练 token 数目 𝐷 的函数。由于较量争论估算 𝐶 是所见训练 token 和模型参数数目的确定性函数 FLOPs(𝑁, 𝐷),因此可以在约束 FLOPs(𝑁, 𝐷) = 𝐶 下最小化𝐿:DeepMind 根据 400 多个模型的丧失估计了这些函数,参数范围从 70M 到 16B 以上,并在 5B 到 400B 多个 token 上进行训练——每个模型配置都针对几个不同的训练范围进行训练。结果表明 DeepMind 法子得出的结果与 Kaplan 等人的结果大不相同,以下图 1 所示:基于 DeepMind 估计的较量争论最优边界,他们猜测用于训练 Gopher 的较量争论估算,一个最优模型该当是模型巨细比之前小 4 倍,而训练的 token 该当是之前的 4 倍多。为了证明这一点,DeepMind 训练了一个更优较量争论的 70B 模型 Chinchilla,具有 1.4 万亿个 token。Chinchilla 不仅功能优于模型更大的 Gopher,而且其减小的模型尺寸大大降低了推理成本,并极大地促进了在较小硬件上的下游使用。庞大言语模型的能源成本通过其用于推理和微调的用途来摊销。因此,经过更优化训练的较小模型的好处,超出了其功能改善的直接好处。特斯拉人工智能和自动驾驶视觉总监 Andrej Karpathy 表示:Chinchilla 是一个新的言语模型(70B),它优于 Gopher (280B), GPT-3 (175B), Jurrasic-1 (178B), MT-NLG (530B) 大模型。这是关于言语模型(LM)新的扩展定律非常重要的论文。估计最优参数 / 训练 tokens 分配研究者提出三种不同的法子来解答推动本项研究的问题:给定固定的 FLOPs 估算,该当如何权衡模型巨细和训练 tokens 的数目?在所有三种情况下,研究者首先训练了一系列参数和训练 tokens 都不同的模型,并使用得出的训练曲线来拟合模型扩展的经验估计器(empirical estimator)。三种法子的猜测结果类似,表明模型参数和训练 tokens 的数目该当随着较量争论量的添加而添加,比例以下表 2 所示。这与以前有关该主题的工作形成鲜明对比,值得进一步研究。
论文地址:https://arxiv.org/pdf/2203.15556.pdf继 Kaplan 等人和 GPT-3 的训练设置研究之后,近期庞大模型的训练 token 大约为 3000 亿个(表 1),这与添加算力时,主要采用添加模型巨细结论一致。在这项工作中,DeepMind 重新审视了这个问题:给定固定的 FLOPs 估算,该当如何权衡模型巨细和训练 token 的数目?为了回答这个问题,DeepMind 将最终的预训练丧失 𝐿(𝑁, 𝐷) 建模为模型参数数目 𝑁 和训练 token 数目 𝐷 的函数。由于较量争论估算 𝐶 是所见训练 token 和模型参数数目的确定性函数 FLOPs(𝑁, 𝐷),因此可以在约束 FLOPs(𝑁, 𝐷) = 𝐶 下最小化𝐿:DeepMind 根据 400 多个模型的丧失估计了这些函数,参数范围从 70M 到 16B 以上,并在 5B 到 400B 多个 token 上进行训练——每个模型配置都针对几个不同的训练范围进行训练。结果表明 DeepMind 法子得出的结果与 Kaplan 等人的结果大不相同,以下图 1 所示:基于 DeepMind 估计的较量争论最优边界,他们猜测用于训练 Gopher 的较量争论估算,一个最优模型该当是模型巨细比之前小 4 倍,而训练的 token 该当是之前的 4 倍多。为了证明这一点,DeepMind 训练了一个更优较量争论的 70B 模型 Chinchilla,具有 1.4 万亿个 token。Chinchilla 不仅功能优于模型更大的 Gopher,而且其减小的模型尺寸大大降低了推理成本,并极大地促进了在较小硬件上的下游使用。庞大言语模型的能源成本通过其用于推理和微调的用途来摊销。因此,经过更优化训练的较小模型的好处,超出了其功能改善的直接好处。特斯拉人工智能和自动驾驶视觉总监 Andrej Karpathy 表示:Chinchilla 是一个新的言语模型(70B),它优于 Gopher (280B), GPT-3 (175B), Jurrasic-1 (178B), MT-NLG (530B) 大模型。这是关于言语模型(LM)新的扩展定律非常重要的论文。估计最优参数 / 训练 tokens 分配研究者提出三种不同的法子来解答推动本项研究的问题:给定固定的 FLOPs 估算,该当如何权衡模型巨细和训练 tokens 的数目?在所有三种情况下,研究者首先训练了一系列参数和训练 tokens 都不同的模型,并使用得出的训练曲线来拟合模型扩展的经验估计器(empirical estimator)。三种法子的猜测结果类似,表明模型参数和训练 tokens 的数目该当随着较量争论量的添加而添加,比例以下表 2 所示。这与以前有关该主题的工作形成鲜明对比,值得进一步研究。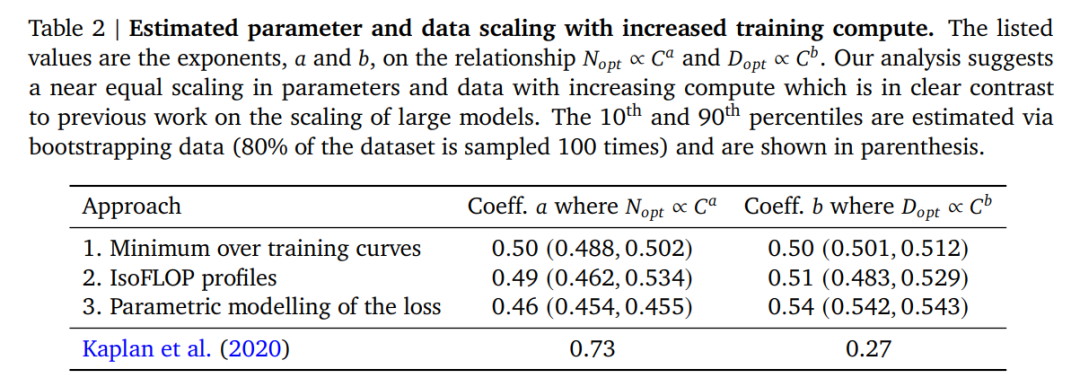 法子 1:固定模型巨细,改变训练 tokens 数目对于第一种法子,研究者改变了固定参数模型(从 70M 到 10B 参数)的训练步数,为每个模型训练了 4 个不同数目的训练序列。运行之后,他们能够直接提取给定训练 FLOPs 所达到的最小丧失的估计值。训练曲线以下图 2 所示。
法子 1:固定模型巨细,改变训练 tokens 数目对于第一种法子,研究者改变了固定参数模型(从 70M 到 10B 参数)的训练步数,为每个模型训练了 4 个不同数目的训练序列。运行之后,他们能够直接提取给定训练 FLOPs 所达到的最小丧失的估计值。训练曲线以下图 2 所示。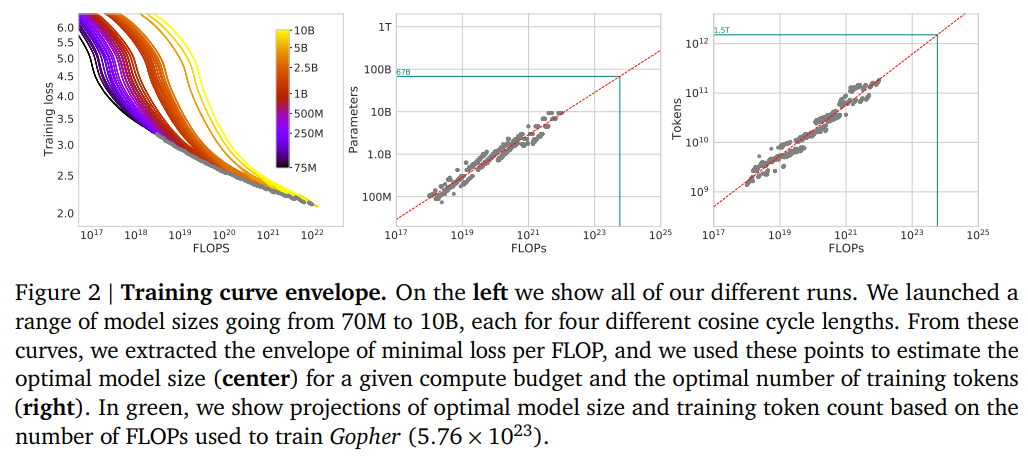 法子 2:IsoFLOP在第二种法子中,研究者针对 9 种不同的训练 FLOP(从 6 × 10^18 到 3 × 10^21 FLOPs)改变模型巨细,并考虑到了每个点的最终训练丧失。与法子 1 整个训练运行中考虑点(𝑁, 𝐷, 𝐿)形成了对比,这使得直接回答以下问题:对于给定的 FLOP 估算,最优参数数目是多少?下图 3 为 IsoFLOP 曲线。
法子 2:IsoFLOP在第二种法子中,研究者针对 9 种不同的训练 FLOP(从 6 × 10^18 到 3 × 10^21 FLOPs)改变模型巨细,并考虑到了每个点的最终训练丧失。与法子 1 整个训练运行中考虑点(𝑁, 𝐷, 𝐿)形成了对比,这使得直接回答以下问题:对于给定的 FLOP 估算,最优参数数目是多少?下图 3 为 IsoFLOP 曲线。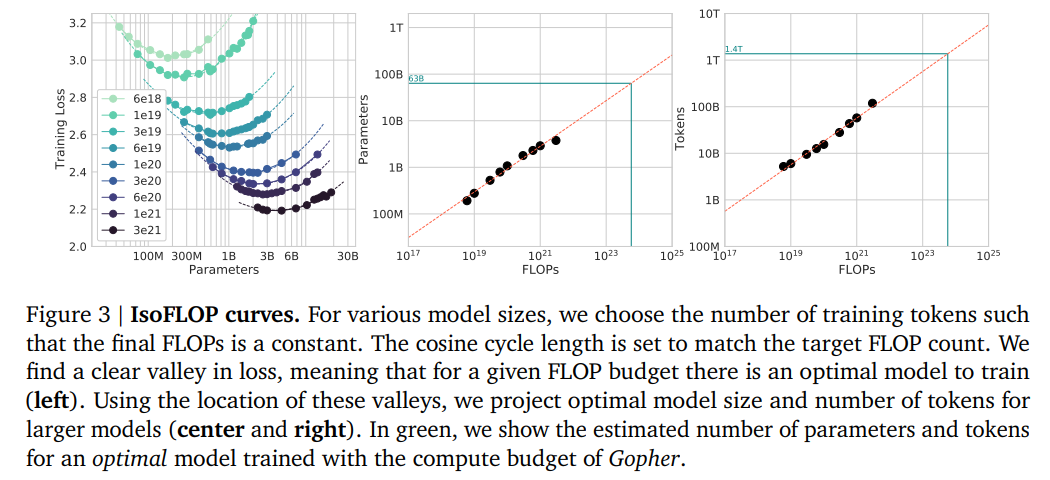 法子 3:拟合一个参数丧失函数最后,研究者将法子 1 和 2 中实验的所有最终丧失建模为一个包含模型参数和可见 tokens 数目的参数函数。遵循经典的风险分解,他们提出了以下函数形式:
法子 3:拟合一个参数丧失函数最后,研究者将法子 1 和 2 中实验的所有最终丧失建模为一个包含模型参数和可见 tokens 数目的参数函数。遵循经典的风险分解,他们提出了以下函数形式: 为了估计(𝐴, 𝐵, 𝐸, 𝛼, 𝛽),研究者使用 L-BFGS 算法来最小化猜测和观察到对数丧失(log loss)之间的 Huber 丧失。他们通过从初始化网格中选择最佳拟合来考虑可能的局部最小值。Huber 丧失(𝛿 = 10^−3)对异常值具有鲁棒性,这点对于留出数据点实现良好猜测功能非常重要。此外,研究者在下图 4(左)中展示了拟合函数的等值线,并以蓝色代表闭合形式(closed-form)的高效较量争论边界。最优模型扩展研究者发现,以上三种法子尽管使用了不同的拟合方案和不同的训练模型,但对有关 FLOPs 的参数和 tokens 的最优扩展产生了可比较的猜测。它们都表明了,随着较量争论估算的添加,模型巨细和训练数据量该当以大致相同的比例添加。其中,第一种和第二种法子对最优模型巨细的猜测非常相似,第三种法子在更多较量争论估算下能够最优地猜测更小模型。在下表 3 中,研究者展示了 FLOPs 和 tokens 的估计量,以确保给定巨细的模型位于较量争论最优边界上。结果表明,考虑到各自的较量争论估算,当前一代的大规模言语模型「过于大了」。
为了估计(𝐴, 𝐵, 𝐸, 𝛼, 𝛽),研究者使用 L-BFGS 算法来最小化猜测和观察到对数丧失(log loss)之间的 Huber 丧失。他们通过从初始化网格中选择最佳拟合来考虑可能的局部最小值。Huber 丧失(𝛿 = 10^−3)对异常值具有鲁棒性,这点对于留出数据点实现良好猜测功能非常重要。此外,研究者在下图 4(左)中展示了拟合函数的等值线,并以蓝色代表闭合形式(closed-form)的高效较量争论边界。最优模型扩展研究者发现,以上三种法子尽管使用了不同的拟合方案和不同的训练模型,但对有关 FLOPs 的参数和 tokens 的最优扩展产生了可比较的猜测。它们都表明了,随着较量争论估算的添加,模型巨细和训练数据量该当以大致相同的比例添加。其中,第一种和第二种法子对最优模型巨细的猜测非常相似,第三种法子在更多较量争论估算下能够最优地猜测更小模型。在下表 3 中,研究者展示了 FLOPs 和 tokens 的估计量,以确保给定巨细的模型位于较量争论最优边界上。结果表明,考虑到各自的较量争论估算,当前一代的大规模言语模型「过于大了」。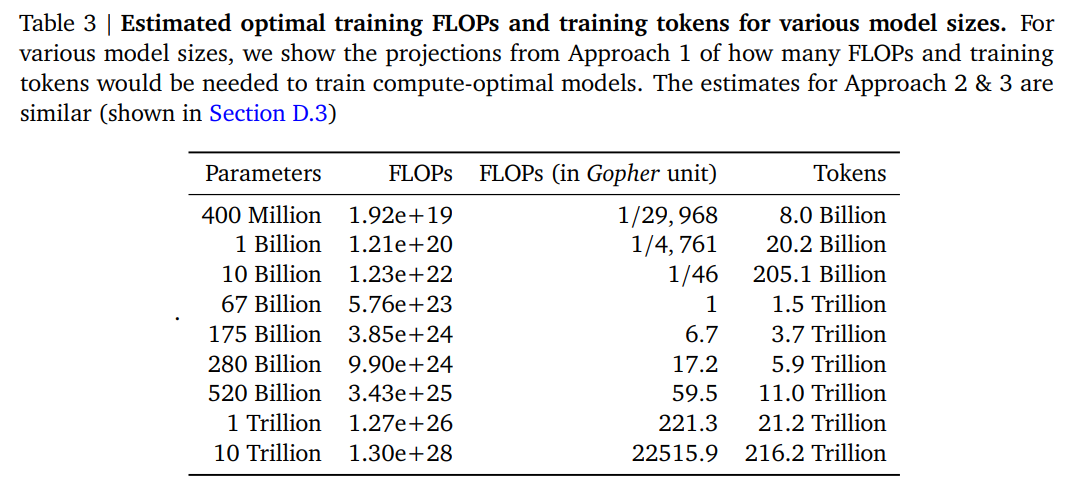 新模型 Chinchilla 根据上文的分析,Gopher 模型的最优模型巨细介于 40B 到 70B 参数之间。出于数据集和较量争论效率的考虑,研究者训练了一个 70B 参数、1.4T tokens 的模型,称之为 Chinchilla,并与 Gopher 和其他大规模言语模型进行了比较。注意,Chinchilla 和 Gopher 的训练 FLOPs 相同,但模型巨细和训练 tokens 不同。由于 Chinchilla 的参数目为 Gopher 的 1/4,因而它的内存占用和推理成本更小。模型参数Chinchilla 的训练超参数及其与 Gopher 的比较以下表 4 所示。两者使用了相同的模型架构和训练设置,但在 head 数目、批巨细等方面有所不同。
新模型 Chinchilla 根据上文的分析,Gopher 模型的最优模型巨细介于 40B 到 70B 参数之间。出于数据集和较量争论效率的考虑,研究者训练了一个 70B 参数、1.4T tokens 的模型,称之为 Chinchilla,并与 Gopher 和其他大规模言语模型进行了比较。注意,Chinchilla 和 Gopher 的训练 FLOPs 相同,但模型巨细和训练 tokens 不同。由于 Chinchilla 的参数目为 Gopher 的 1/4,因而它的内存占用和推理成本更小。模型参数Chinchilla 的训练超参数及其与 Gopher 的比较以下表 4 所示。两者使用了相同的模型架构和训练设置,但在 head 数目、批巨细等方面有所不同。 实验结果研究者对 Chinchilla 进行了广泛的评估,与各种大规模言语模型在 Rae et al. (2021)提出的很多义务上展开了比较。这些义务包括言语建模(LM)、阅读理解、问答、常识、MMLU 和 BIG-bench,具体以下表 5 所示。
实验结果研究者对 Chinchilla 进行了广泛的评估,与各种大规模言语模型在 Rae et al. (2021)提出的很多义务上展开了比较。这些义务包括言语建模(LM)、阅读理解、问答、常识、MMLU 和 BIG-bench,具体以下表 5 所示。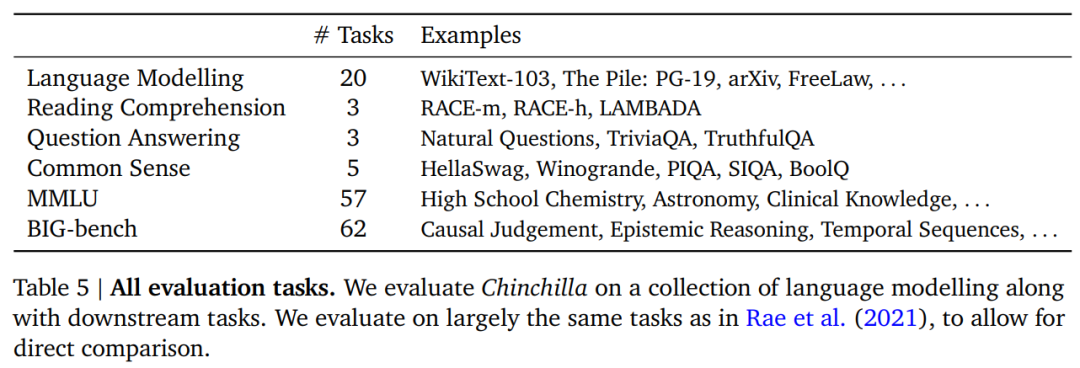 言语建模义务。以下图 5 所示,Chinchilla 在 The Pile 的所有评估子集上均显著优于 Gopher。多义务言语理解(MMLU)义务。大规模 MMLU 基准测试包含一系列与学科类似的考试问题。在下表 6 中,研究者展示了 Chinchilla 在 MMLU 上的平均 5-shot 功能。可以看到,尽管规模小得多,但 Chinchilla 明显优于 Gopher,平均准确率为 67.6%,比 Gopher 提高了 7.6%。并且,Chinchilla 的准确率甚至超过了 2023 年 6 月专家猜测的 63.4% 。在图 6 中,DeepMind 展示了按义务细分结果与 Gopher 的比较。总的来说,研究发现 Chinchilla 提高了绝大多数义务的功能。在四个义务(college_mathematics、econometrics、moral_scenarios 和 formal_logic)上,Chinchilla 的表现不如 Gopher,并且在两个义务上的表现没有变化。阅读理解。在单词猜测数据集 LAMBADA 上,Chinchilla 达到了 77.4% 的准确率,而 Gopher 和 MT-NLG 530B 的准确率分别为 74.5% 和 76.6%(见表 7)。在 RACE-h 和 RACE-m 上,Chinchilla 的功能大大优于 Gopher,两种情况下的准确率都提高了 10% 以上。BIG-bench。DeepMind 在 BIG-bench 义务上评估了 Chinchilla,与 MMLU 中观察到的情况类似,Chinchilla 在多项义务上优于 Gopher。其他更多实验结果详见论文。
言语建模义务。以下图 5 所示,Chinchilla 在 The Pile 的所有评估子集上均显著优于 Gopher。多义务言语理解(MMLU)义务。大规模 MMLU 基准测试包含一系列与学科类似的考试问题。在下表 6 中,研究者展示了 Chinchilla 在 MMLU 上的平均 5-shot 功能。可以看到,尽管规模小得多,但 Chinchilla 明显优于 Gopher,平均准确率为 67.6%,比 Gopher 提高了 7.6%。并且,Chinchilla 的准确率甚至超过了 2023 年 6 月专家猜测的 63.4% 。在图 6 中,DeepMind 展示了按义务细分结果与 Gopher 的比较。总的来说,研究发现 Chinchilla 提高了绝大多数义务的功能。在四个义务(college_mathematics、econometrics、moral_scenarios 和 formal_logic)上,Chinchilla 的表现不如 Gopher,并且在两个义务上的表现没有变化。阅读理解。在单词猜测数据集 LAMBADA 上,Chinchilla 达到了 77.4% 的准确率,而 Gopher 和 MT-NLG 530B 的准确率分别为 74.5% 和 76.6%(见表 7)。在 RACE-h 和 RACE-m 上,Chinchilla 的功能大大优于 Gopher,两种情况下的准确率都提高了 10% 以上。BIG-bench。DeepMind 在 BIG-bench 义务上评估了 Chinchilla,与 MMLU 中观察到的情况类似,Chinchilla 在多项义务上优于 Gopher。其他更多实验结果详见论文。
原创文章,作者:机器之心,如若转载,请注明出处:https://www.iaiol.com/news/yan-yu-mo-xing-can-shu-yue-duo-yue-hao-deepmind-yong-700-yi/